group-telegram.com/ai_machinelearning_big_data/7782
Create:
Last Update:
Last Update:
Goodfire AI, вдохновившись примером Anthropic в интерпретации внутренних процессов Claude, воспроизвели методы трассировки цепей межслойных транскодеров (Cross-Layer Transcoders, CLT) на GPT-2 Small, чтобы проверить их способность раскрывать известные механизмы трансформеров.
Выбор на GPT-2 Small пал не случайно, эта модель небольшая и уже была ранее подвергнута ручному реверс-инжинирингу.
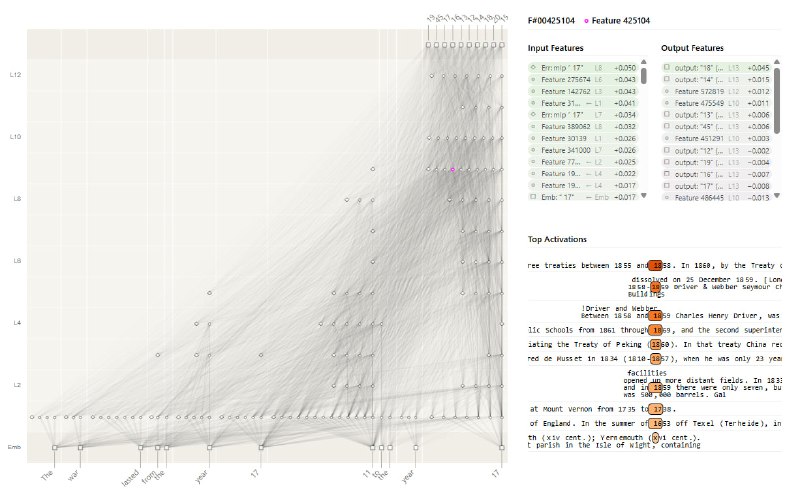
Cross-Layer Transcoders выжимают из модели разреженные признаки, которые объясняют работу MLP-слоев. Визуализируют это через графы атрибуции — это карты влияния признака на выход модели.
Натренировали на 100M токенов из FineWeb, получили ~590K признаков. Точность CLT-реплики модели составила 59%, что близко к оригинальным статьям. Тестировали на задаче сравнения чисел («больше, чем»), идеальном полигоне, где уже известны ключевые механизмы.
Задача "Больше, чем" (ориг. "greater-than") взята из статьи Michael Hanna, она заставляет предсказывать большие числа для второго года в диапазоне дат.
Промпт «The war lasted from the year 1711 to 17». CLT построил граф, где признаки с токена «11» (последняя цифра года) активнее всего влияли на предсказание.
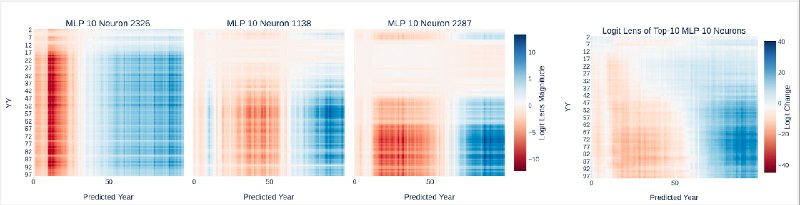
Дальше, выделили топ-160 признаков, для каждого построили логит-атрибуции — теплокарты, показывающие, как признак влияет на выходные годы (ZZ) при разных входных (YY).
Похоже, CLT подсветил кучу узкоспециализированных «сравнивателей», а не универсальные нейроны, как в ручных исследованиях.
CLT автоматически находит интерпретируемые признаки, даже такие неочевидные, как абстрактная четность. Но их «разреженный» мир выглядит иначе, чем ручная трассировка цепей: тут больше узких признаков-«спецов» (Feature 461858 для диапазона 10–30) и меньше универсальных механизмов.
Возможно, дело в методе: CLT смотрит изолированные вклады фич, а в полной модели они взаимодействуют.
В общем, эксперименты с CLT показал, что под капотом языковых моделей не только четкие «сравниватели чисел», но и куча скрытых паттернов вроде детекторов контраста или любителей чисел, кратных 5. И да, полуавтономный анализ иногда видит то, что люди упускают.
@ai_machinelearning_big_data
#AI #ML #LLM #Research #CLT