group-telegram.com/ai_machinelearning_big_data/7962
Last Update:
Исследователи из из Гонконгского университета и инженеры Alibaba научили LLM генерировать семантически разные ответы, заставляя их «думать» в ортогональных направлениях.
Наверняка каждый, кто работает с LLM, сталкивался с их любовью к самоповторам. Запрашиваешь несколько вариантов решения, а получаешь одну и ту же мысль, просто перефразированную.
Стандартные подходы к декодированию, temperature sampling или diverse beam search, создают лишь лексическое разнообразие, но пасуют, когда требуется семантическое. Это серьезная проблема для Best-of-N или RLHF. Ведь без по-настоящему разных идей и подходов к решению задачи эти методы теряют свою силу: выбирать лучший вариант не из чего, а обучать модель на однотипных примерах неэффективно.
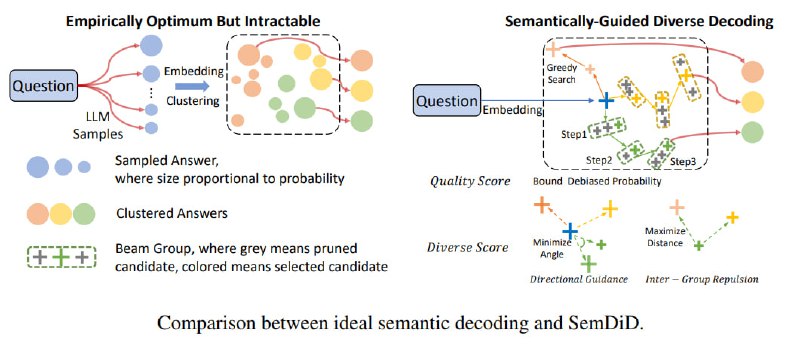
Решение предложили в методе SemDiD (Semantic-guided Diverse Decoding). Его суть, если кратко, перестать играть с токенами на поверхности и начать управлять генерацией напрямую в пространстве эмбеддингов.
Сначала, на старте, он принудительно направляет разные группы beams по ортогональным векторам в семантическом пространстве. Грубо говоря, это как дать команду разным поисковым группам двигаться строго на север, юг и запад, чтобы они гарантированно разошлись.
По мере генерации, когда жесткие директивы могут стать неоптимальными, включается второй механизм - inter-group repulsion. Он просто следит, чтобы смысловые траектории ответов не сближались, сохраняя их уникальность до самого конца.
Но как, гоняясь за разнообразием, не получить на выходе бессвязный бред?
SemDiD подходит к контролю качества уникально. Он не пытается слепо максимизировать вероятность последовательности, а использует ее лишь как нижнюю границу, чтобы отсечь совсем уж плохие варианты.
Кроме того, алгоритм корректирует системные искажения, когда вероятность токенов искусственно завышается в зависимости от их позиции в тексте.
Для баланса между качеством и разнообразием используется адаптивный механизм на основе гармонического среднего, который в каждый момент времени уделяет больше внимания той метрике, которая проседает.
На бенчмарках для Best-of-N, от MMLU-Pro+ до GSM8K, SemDiD увеличивает покрытие (шанс найти верный ответ) на 1.4%-5.2% по сравнению с аналогами.
Генерируя для GRPO или RLOO семантически богатые наборы ответов, SemDiD предоставляет им более качественный материал для обучения. Это ускоряет сходимость на 15% и повышает финальную точность моделей.
@ai_machinelearning_big_data
#AI #ML #LLM #SemDiD