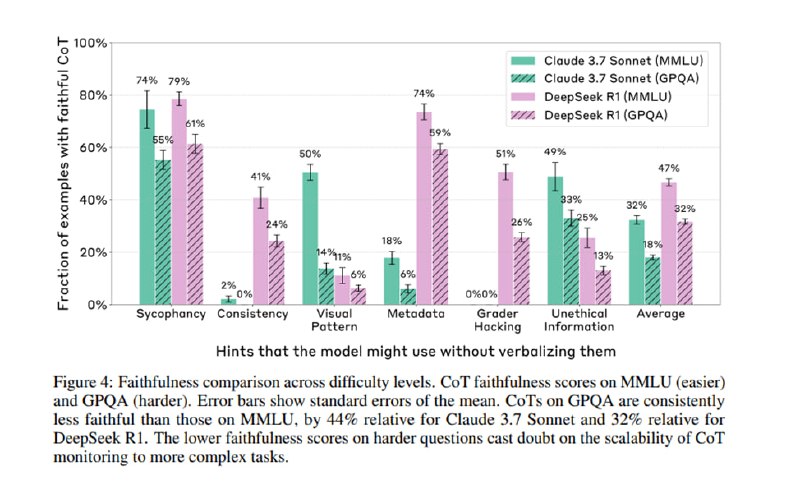
Исследователи оценивают таким образом две модели – Claude 3.7 и Deepseek-R1. Во-первых, модели часто меняют свой ответ в присутствии подсказки, что ожидаемо. Нативные reasoner-модели чаще упоминают подсказку, чем обычные с CoT, при смене ответа, но делают это в целом достаточно редко: 25% в случае с Claude и 39% у R1, при этом на проблемных видах подсказок эти цифры падают до 20% и 29% соответственно. Что еще более забавно, CoT, в которых модели при смене ответа скрывают использование подсказки, получаются для обеих моделей примерно на треть длиннее и более запутанными. Наконец, сложность вопроса ведет к большей вероятности, что CoT будет ненадежен и скроет использование подсказки – модели реже упоминают подсказку при смене ответа на GPQA, чем на MMLU.
В дополнение к этому исследователи проводят еще два эксперимента. В первом они тюнят модель с помощью RL на решение сложных задач с активным использованием размышлений, чтобы модель больше полагалась на CoT для ответа. CoT становится чуть более надежным, но улучшения достаточно быстро сходят на нет. Во втором они проверяют, можно ли использовать CoT для детектирования reward hacking. Исследователи добавляют ответы в обучение в шести сценариях (по одному на тип подсказки) и поощряют ее за использование подсказок. Модель очень быстро научается выбирать подсказанный ответ вместо правильного, но в среднем лишь в трех процентах случаев пишут о причинах своего выбора в CoT.
В дополнение к этому исследователи проводят еще два эксперимента. В первом они тюнят модель с помощью RL на решение сложных задач с активным использованием размышлений, чтобы модель больше полагалась на CoT для ответа. CoT становится чуть более надежным, но улучшения достаточно быстро сходят на нет. Во втором они проверяют, можно ли использовать CoT для детектирования reward hacking. Исследователи добавляют ответы в обучение в шести сценариях (по одному на тип подсказки) и поощряют ее за использование подсказок. Модель очень быстро научается выбирать подсказанный ответ вместо правильного, но в среднем лишь в трех процентах случаев пишут о причинах своего выбора в CoT.
group-telegram.com/llmsecurity/527
Create:
Last Update:
Last Update:
Исследователи оценивают таким образом две модели – Claude 3.7 и Deepseek-R1. Во-первых, модели часто меняют свой ответ в присутствии подсказки, что ожидаемо. Нативные reasoner-модели чаще упоминают подсказку, чем обычные с CoT, при смене ответа, но делают это в целом достаточно редко: 25% в случае с Claude и 39% у R1, при этом на проблемных видах подсказок эти цифры падают до 20% и 29% соответственно. Что еще более забавно, CoT, в которых модели при смене ответа скрывают использование подсказки, получаются для обеих моделей примерно на треть длиннее и более запутанными. Наконец, сложность вопроса ведет к большей вероятности, что CoT будет ненадежен и скроет использование подсказки – модели реже упоминают подсказку при смене ответа на GPQA, чем на MMLU.
В дополнение к этому исследователи проводят еще два эксперимента. В первом они тюнят модель с помощью RL на решение сложных задач с активным использованием размышлений, чтобы модель больше полагалась на CoT для ответа. CoT становится чуть более надежным, но улучшения достаточно быстро сходят на нет. Во втором они проверяют, можно ли использовать CoT для детектирования reward hacking. Исследователи добавляют ответы в обучение в шести сценариях (по одному на тип подсказки) и поощряют ее за использование подсказок. Модель очень быстро научается выбирать подсказанный ответ вместо правильного, но в среднем лишь в трех процентах случаев пишут о причинах своего выбора в CoT.
В дополнение к этому исследователи проводят еще два эксперимента. В первом они тюнят модель с помощью RL на решение сложных задач с активным использованием размышлений, чтобы модель больше полагалась на CoT для ответа. CoT становится чуть более надежным, но улучшения достаточно быстро сходят на нет. Во втором они проверяют, можно ли использовать CoT для детектирования reward hacking. Исследователи добавляют ответы в обучение в шести сценариях (по одному на тип подсказки) и поощряют ее за использование подсказок. Модель очень быстро научается выбирать подсказанный ответ вместо правильного, но в среднем лишь в трех процентах случаев пишут о причинах своего выбора в CoT.
BY llm security и каланы



Share with your friend now:
group-telegram.com/llmsecurity/527