
{kind=link}
Вышло свежее исследование от Anthropic про новый метод элаймента LLM
Давненько антропики не выпускали крутых ресерчей, а тут сразу очень объемная статья с крутыми результатами, да еще и Ян Лейке (бывший ключевой ученый OpenAI) в соавторах. Разбираемся, что показали 👇
Начнем с того, что стартап уже давно занимается в частности изучением джейлбрейков – техник «хитрого» промптинга, которые позволяют обходить ограничения моделек. В ноябре, например, у них выходила статья (наш разбор) про метод обнаружения новых методов джейлбрейка. Сейчас они тоже показывают что-то похожее: Constitutional Classifiers, то есть систему классификации для защиты LLM.
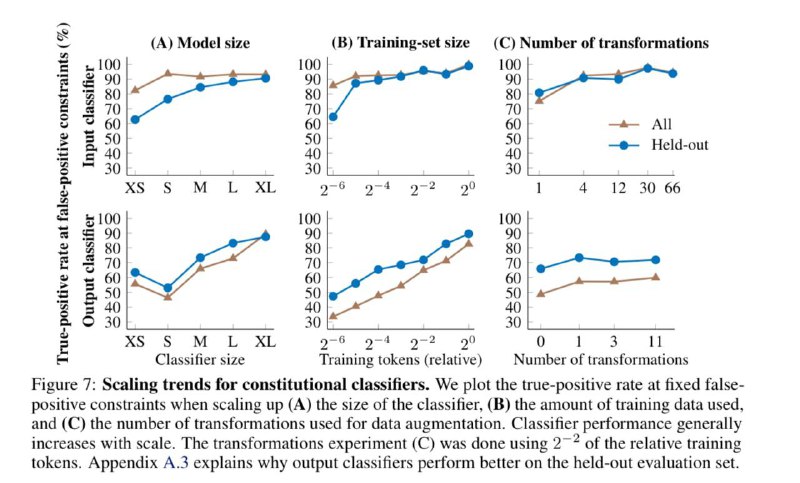
В основе метода safeguard классификаторы, которые обучают полностью на синтетических данных. Такие данные генерируются на основе набора естественно-языковых правил, которые определяют, какие запросы допустимы, а какие должны блокироваться. Эти правила называются конституциями, потому метод и зовется Constitutional.
При этом так фильтруются не только выходы LLM (как происходит традиционно), но еще и сами запросы. И такой рецепт в совокупности с качественной генерацией синтетики сработал ну очень хорошо.
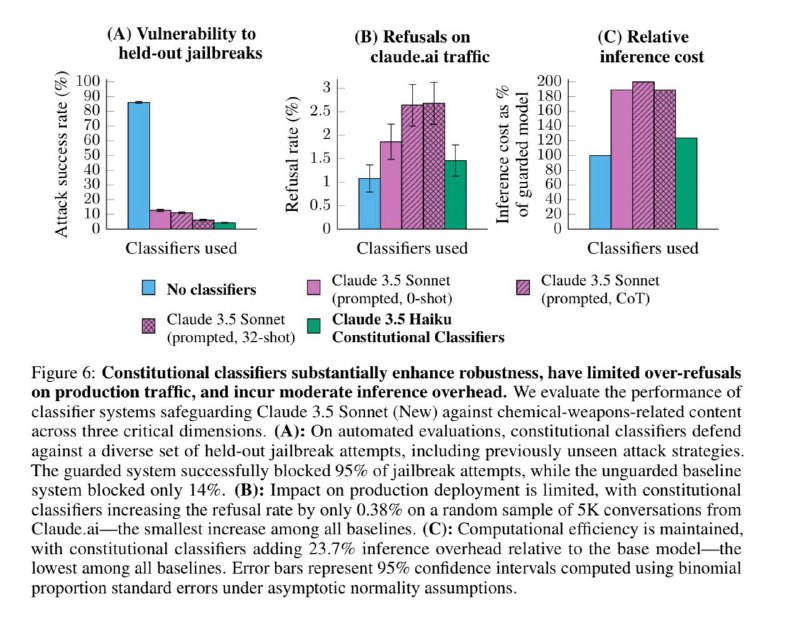
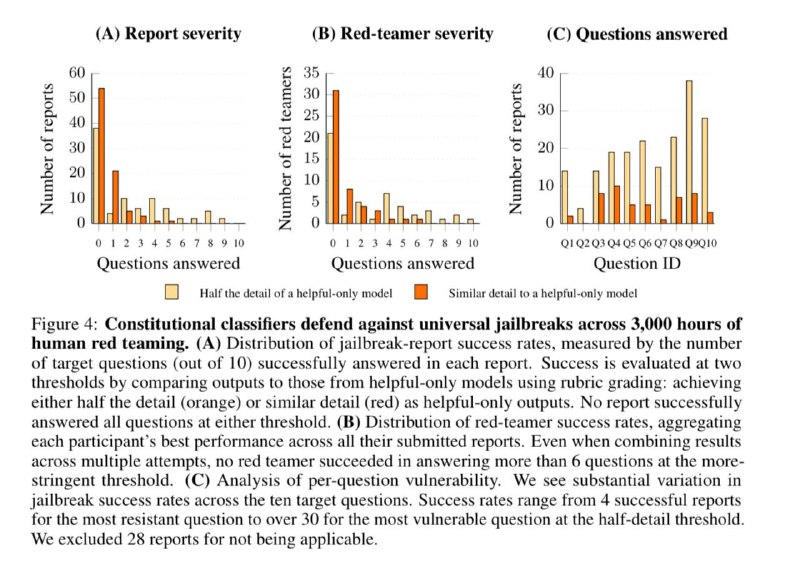
Надо сказать, что обычно основная проблема таких систем – это то, что они плохо приспосабливаются к новым методам промптинга. Но тут в ходе тестирования не нашлось ни одного промпта, которым бы удалось стабильно сломать защищенную таким методом систему.
А тестирование, чтобы вы понимали, было действительно масштабное: Anthropic провели целый хакатон, на котором предлагали до 15к долларов за успешные джейлбрейки. В нем приняли участие 405 человек, включая профессиональных red teamer’ов (это типа белые хакеры в мире LLM). Плюс внутренние тесты стартапа, конечно: у них есть собственная red team.
При этом по словам Anthropic процент false positive остается достаточно низким (до 0.5%), так что моделька получается даже не слишком пугливой.
В общем результаты крутые, правда. Полностью статью читайте тут: arxiv.org/abs/2501.18837
Давненько антропики не выпускали крутых ресерчей, а тут сразу очень объемная статья с крутыми результатами, да еще и Ян Лейке (бывший ключевой ученый OpenAI) в соавторах. Разбираемся, что показали 👇
Начнем с того, что стартап уже давно занимается в частности изучением джейлбрейков – техник «хитрого» промптинга, которые позволяют обходить ограничения моделек. В ноябре, например, у них выходила статья (наш разбор) про метод обнаружения новых методов джейлбрейка. Сейчас они тоже показывают что-то похожее: Constitutional Classifiers, то есть систему классификации для защиты LLM.
В основе метода safeguard классификаторы, которые обучают полностью на синтетических данных. Такие данные генерируются на основе набора естественно-языковых правил, которые определяют, какие запросы допустимы, а какие должны блокироваться. Эти правила называются конституциями, потому метод и зовется Constitutional.
При этом так фильтруются не только выходы LLM (как происходит традиционно), но еще и сами запросы. И такой рецепт в совокупности с качественной генерацией синтетики сработал ну очень хорошо.
Надо сказать, что обычно основная проблема таких систем – это то, что они плохо приспосабливаются к новым методам промптинга. Но тут в ходе тестирования не нашлось ни одного промпта, которым бы удалось стабильно сломать защищенную таким методом систему.
А тестирование, чтобы вы понимали, было действительно масштабное: Anthropic провели целый хакатон, на котором предлагали до 15к долларов за успешные джейлбрейки. В нем приняли участие 405 человек, включая профессиональных red teamer’ов (это типа белые хакеры в мире LLM). Плюс внутренние тесты стартапа, конечно: у них есть собственная red team.
При этом по словам Anthropic процент false positive остается достаточно низким (до 0.5%), так что моделька получается даже не слишком пугливой.
В общем результаты крутые, правда. Полностью статью читайте тут: arxiv.org/abs/2501.18837
👍76🔥25🌚6❤5🗿2🐳1
group-telegram.com/data_secrets/6078
Create:
Last Update:
Last Update:
Вышло свежее исследование от Anthropic про новый метод элаймента LLM
Давненько антропики не выпускали крутых ресерчей, а тут сразу очень объемная статья с крутыми результатами, да еще и Ян Лейке (бывший ключевой ученый OpenAI) в соавторах. Разбираемся, что показали 👇
Начнем с того, что стартап уже давно занимается в частности изучением джейлбрейков – техник «хитрого» промптинга, которые позволяют обходить ограничения моделек. В ноябре, например, у них выходила статья (наш разбор) про метод обнаружения новых методов джейлбрейка. Сейчас они тоже показывают что-то похожее: Constitutional Classifiers, то есть систему классификации для защиты LLM.
В основе метода safeguard классификаторы, которые обучают полностью на синтетических данных. Такие данные генерируются на основе набора естественно-языковых правил, которые определяют, какие запросы допустимы, а какие должны блокироваться. Эти правила называются конституциями, потому метод и зовется Constitutional.
При этом так фильтруются не только выходы LLM (как происходит традиционно), но еще и сами запросы. И такой рецепт в совокупности с качественной генерацией синтетики сработал ну очень хорошо.
Надо сказать, что обычно основная проблема таких систем – это то, что они плохо приспосабливаются к новым методам промптинга. Но тут в ходе тестирования не нашлось ни одного промпта, которым бы удалось стабильно сломать защищенную таким методом систему.
А тестирование, чтобы вы понимали, было действительно масштабное: Anthropic провели целый хакатон, на котором предлагали до 15к долларов за успешные джейлбрейки. В нем приняли участие 405 человек, включая профессиональных red teamer’ов (это типа белые хакеры в мире LLM). Плюс внутренние тесты стартапа, конечно: у них есть собственная red team.
При этом по словам Anthropic процент false positive остается достаточно низким (до 0.5%), так что моделька получается даже не слишком пугливой.
В общем результаты крутые, правда. Полностью статью читайте тут: arxiv.org/abs/2501.18837
Давненько антропики не выпускали крутых ресерчей, а тут сразу очень объемная статья с крутыми результатами, да еще и Ян Лейке (бывший ключевой ученый OpenAI) в соавторах. Разбираемся, что показали 👇
Начнем с того, что стартап уже давно занимается в частности изучением джейлбрейков – техник «хитрого» промптинга, которые позволяют обходить ограничения моделек. В ноябре, например, у них выходила статья (наш разбор) про метод обнаружения новых методов джейлбрейка. Сейчас они тоже показывают что-то похожее: Constitutional Classifiers, то есть систему классификации для защиты LLM.
В основе метода safeguard классификаторы, которые обучают полностью на синтетических данных. Такие данные генерируются на основе набора естественно-языковых правил, которые определяют, какие запросы допустимы, а какие должны блокироваться. Эти правила называются конституциями, потому метод и зовется Constitutional.
При этом так фильтруются не только выходы LLM (как происходит традиционно), но еще и сами запросы. И такой рецепт в совокупности с качественной генерацией синтетики сработал ну очень хорошо.
Надо сказать, что обычно основная проблема таких систем – это то, что они плохо приспосабливаются к новым методам промптинга. Но тут в ходе тестирования не нашлось ни одного промпта, которым бы удалось стабильно сломать защищенную таким методом систему.
А тестирование, чтобы вы понимали, было действительно масштабное: Anthropic провели целый хакатон, на котором предлагали до 15к долларов за успешные джейлбрейки. В нем приняли участие 405 человек, включая профессиональных red teamer’ов (это типа белые хакеры в мире LLM). Плюс внутренние тесты стартапа, конечно: у них есть собственная red team.
При этом по словам Anthropic процент false positive остается достаточно низким (до 0.5%), так что моделька получается даже не слишком пугливой.
В общем результаты крутые, правда. Полностью статью читайте тут: arxiv.org/abs/2501.18837
BY Data Secrets


Share with your friend now:
group-telegram.com/data_secrets/6078