
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
Тренируем лору на персонажа для Wan 1.3b под виндой
- треним только на картинках
- в musubi tuner (с GUI)
- я тренил в 640x1024, но можно и 480x832. чем больше размер, тем больше vram
- vram от 4GB (при батче 1)
- тренировка с видео занимает намного больше vram (480x852, 85 frames, batch 1 - 17 GB). В каком разрешении треним, в таком и инференс надо делать. wan vace 1.3b натренирован в разрешении 480x832
- на 30 картинках тренил 1 час на 3090
- на 30 картинках + 14 видео тренил 15 часов (лора на действие)
- для увеличения похожести в vace подаем референсную картинку с лицом
- поддерживается t2v, vace_i2v. (хз про wan-fun, wan-phantom)
- рекомендую инференс через vace_t2v+reference, vace-i2v
Установка под виндой
ручками качаем модельки в папку \musubi-tuner-wan-gui\models\Wan\
1.3b: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/diffusion_models/wan2.1_t2v_1.3B_bf16.safetensors
vae: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/vae/wan_2.1_vae.safetensors
t5: https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P/resolve/main/models_t5_umt5-xxl-enc-bf16.pth
clip: https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P/blob/main/models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth
Если вы под виндой - надо в коде выключить libuv и оставить видимость только одной видюхи.
- в файле wan_lora_trainer_gui.py после строк импорта в строке 9 добавить строки:
- в файле hv_train_network.py после строк импорта в строке 54 добавить те же строки, что и выше.
# Датасет
30 картинок с лицом. Большинство - лицевые портреты, несколько - в полный рост. С описанием картинок я не заморачивался, ставил везде одинаковое: "Emm4w woman". Но есть вероятность, что подробное описание будет лучше.
картинки с текстовыми описниями вида image1.jpg + image1.txt сюда:
c:\DATA\SD\musubi-tuner-wan-gui\dataset\Emm4w\images\
создаем пустую папку под кэш
c:\DATA\SD\musubi-tuner-wan-gui\dataset\Emm4w\cache\
мой toml конфиг файл с описанием датасета: https://github.com/Mozer/comfy_stuff/blob/main/musubi/dataset_emm4w.toml
положите его внутрь и потом пропишите путь до него в GUI
Внутри там же есть закомментированный пример тренировки на картинках+видео.
в dataset_emm4w.toml файле слэши надо экранировать.
Батчами тренировать быстрее чем по 1 картинке.
в dataset_emm4w.toml измените максимальный размер батча под ваш размер vram. Если будет вылетать - снизьте значение batch_size. 16 для 24 GB, 8 - 12 GB. musubi группирует картинки по размеру в батчи. Если все картинки разного размера, то и батчи будут маленькие, не будут занимать много vram.
Тренить по видео пока не будем, их надо самому порезать на короткие куски длиной до 5 секунд (я тренил лору на снимание предметов одежды).
# запуск
Запускаем GUI из под конды в командной строке:
Start_Wan_GUI.bat
(кликать мышкой на бат не стоит)
В GUI установите значение "save every N epochs" - например каждую 5-ю. Если вы посреди тренировки нажмете СТОП, то принудительного сохранения не будет, потеряете какой-то промежуточный прогресс.
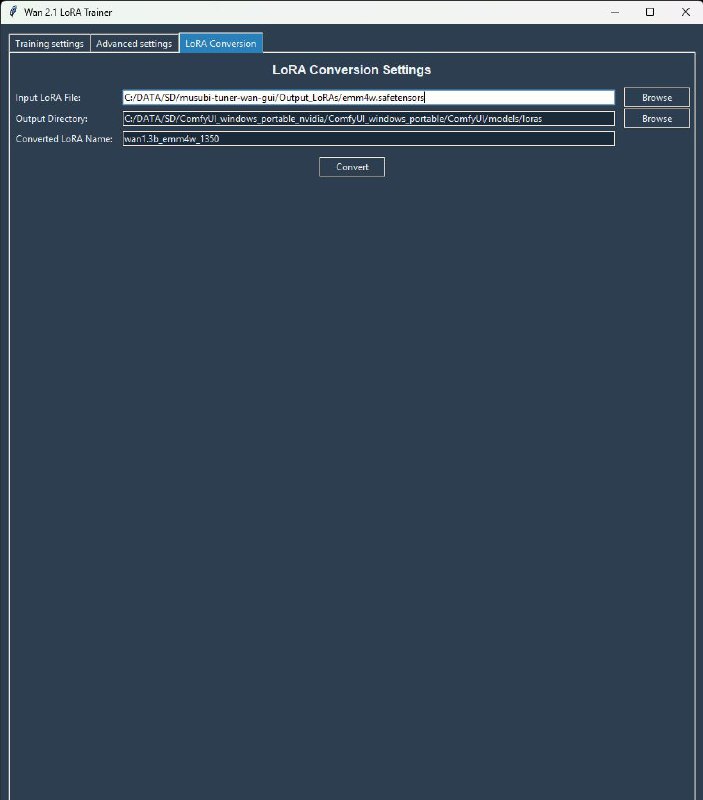
После тренировки нужно сконвертировать safetensors файл в формат для comfy на третьей вкладке GUI.
лора на Эмму: https://huggingface.co/Ftfyhh/wan1.3b_EmmaW_lora
на раздевание: https://huggingface.co/Ftfyhh/wan_1.3b_lora_pnts_drop
workflow wan vace text2video + ref: https://github.com/Mozer/comfy_stuff/blob/main/workflows/wan_vace_1.3b_ref_and_lora.json
видео с моими лорами (nsfw): https://www.group-telegram.com/tensor_art/616
- треним только на картинках
- в musubi tuner (с GUI)
- я тренил в 640x1024, но можно и 480x832. чем больше размер, тем больше vram
- vram от 4GB (при батче 1)
- тренировка с видео занимает намного больше vram (480x852, 85 frames, batch 1 - 17 GB). В каком разрешении треним, в таком и инференс надо делать. wan vace 1.3b натренирован в разрешении 480x832
- на 30 картинках тренил 1 час на 3090
- на 30 картинках + 14 видео тренил 15 часов (лора на действие)
- для увеличения похожести в vace подаем референсную картинку с лицом
- поддерживается t2v, vace_i2v. (хз про wan-fun, wan-phantom)
- рекомендую инференс через vace_t2v+reference, vace-i2v
Установка под виндой
conda create -n musubi
conda install python=3.10
pip install torch==2.5.1 torchvision --index-url https://download.pytorch.org/whl/cu124
pip install triton-windows
pip install sageattention==1.0.6
git clone https://github.com/Kvento/musubi-tuner-wan-gui
cd musubi-tuner-wan-gui
pip install -r requirements.txt
#создаем папку \musubi-tuner-wan-gui\models\Wan\
mkdir models
cd models
mkdir models Wan
ручками качаем модельки в папку \musubi-tuner-wan-gui\models\Wan\
1.3b: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/diffusion_models/wan2.1_t2v_1.3B_bf16.safetensors
vae: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/vae/wan_2.1_vae.safetensors
t5: https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P/resolve/main/models_t5_umt5-xxl-enc-bf16.pth
clip: https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P/blob/main/models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth
Если вы под виндой - надо в коде выключить libuv и оставить видимость только одной видюхи.
- в файле wan_lora_trainer_gui.py после строк импорта в строке 9 добавить строки:
os.environ["USE_LIBUV"] = "0" # Force-disable libuv for windows
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # id of cuda device, starting from 0
- в файле hv_train_network.py после строк импорта в строке 54 добавить те же строки, что и выше.
# Датасет
30 картинок с лицом. Большинство - лицевые портреты, несколько - в полный рост. С описанием картинок я не заморачивался, ставил везде одинаковое: "Emm4w woman". Но есть вероятность, что подробное описание будет лучше.
картинки с текстовыми описниями вида image1.jpg + image1.txt сюда:
c:\DATA\SD\musubi-tuner-wan-gui\dataset\Emm4w\images\
создаем пустую папку под кэш
c:\DATA\SD\musubi-tuner-wan-gui\dataset\Emm4w\cache\
мой toml конфиг файл с описанием датасета: https://github.com/Mozer/comfy_stuff/blob/main/musubi/dataset_emm4w.toml
положите его внутрь и потом пропишите путь до него в GUI
Внутри там же есть закомментированный пример тренировки на картинках+видео.
в dataset_emm4w.toml файле слэши надо экранировать.
Батчами тренировать быстрее чем по 1 картинке.
в dataset_emm4w.toml измените максимальный размер батча под ваш размер vram. Если будет вылетать - снизьте значение batch_size. 16 для 24 GB, 8 - 12 GB. musubi группирует картинки по размеру в батчи. Если все картинки разного размера, то и батчи будут маленькие, не будут занимать много vram.
Тренить по видео пока не будем, их надо самому порезать на короткие куски длиной до 5 секунд (я тренил лору на снимание предметов одежды).
# запуск
Запускаем GUI из под конды в командной строке:
Start_Wan_GUI.bat
(кликать мышкой на бат не стоит)
В GUI установите значение "save every N epochs" - например каждую 5-ю. Если вы посреди тренировки нажмете СТОП, то принудительного сохранения не будет, потеряете какой-то промежуточный прогресс.
После тренировки нужно сконвертировать safetensors файл в формат для comfy на третьей вкладке GUI.
лора на Эмму: https://huggingface.co/Ftfyhh/wan1.3b_EmmaW_lora
на раздевание: https://huggingface.co/Ftfyhh/wan_1.3b_lora_pnts_drop
workflow wan vace text2video + ref: https://github.com/Mozer/comfy_stuff/blob/main/workflows/wan_vace_1.3b_ref_and_lora.json
видео с моими лорами (nsfw): https://www.group-telegram.com/tensor_art/616
group-telegram.com/tensorbanana/1195
Create:
Last Update:
Last Update:
Тренируем лору на персонажа для Wan 1.3b под виндой
- треним только на картинках
- в musubi tuner (с GUI)
- я тренил в 640x1024, но можно и 480x832. чем больше размер, тем больше vram
- vram от 4GB (при батче 1)
- тренировка с видео занимает намного больше vram (480x852, 85 frames, batch 1 - 17 GB). В каком разрешении треним, в таком и инференс надо делать. wan vace 1.3b натренирован в разрешении 480x832
- на 30 картинках тренил 1 час на 3090
- на 30 картинках + 14 видео тренил 15 часов (лора на действие)
- для увеличения похожести в vace подаем референсную картинку с лицом
- поддерживается t2v, vace_i2v. (хз про wan-fun, wan-phantom)
- рекомендую инференс через vace_t2v+reference, vace-i2v
Установка под виндой
ручками качаем модельки в папку \musubi-tuner-wan-gui\models\Wan\
1.3b: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/diffusion_models/wan2.1_t2v_1.3B_bf16.safetensors
vae: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/vae/wan_2.1_vae.safetensors
t5: https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P/resolve/main/models_t5_umt5-xxl-enc-bf16.pth
clip: https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P/blob/main/models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth
Если вы под виндой - надо в коде выключить libuv и оставить видимость только одной видюхи.
- в файле wan_lora_trainer_gui.py после строк импорта в строке 9 добавить строки:
- в файле hv_train_network.py после строк импорта в строке 54 добавить те же строки, что и выше.
# Датасет
30 картинок с лицом. Большинство - лицевые портреты, несколько - в полный рост. С описанием картинок я не заморачивался, ставил везде одинаковое: "Emm4w woman". Но есть вероятность, что подробное описание будет лучше.
картинки с текстовыми описниями вида image1.jpg + image1.txt сюда:
c:\DATA\SD\musubi-tuner-wan-gui\dataset\Emm4w\images\
создаем пустую папку под кэш
c:\DATA\SD\musubi-tuner-wan-gui\dataset\Emm4w\cache\
мой toml конфиг файл с описанием датасета: https://github.com/Mozer/comfy_stuff/blob/main/musubi/dataset_emm4w.toml
положите его внутрь и потом пропишите путь до него в GUI
Внутри там же есть закомментированный пример тренировки на картинках+видео.
в dataset_emm4w.toml файле слэши надо экранировать.
Батчами тренировать быстрее чем по 1 картинке.
в dataset_emm4w.toml измените максимальный размер батча под ваш размер vram. Если будет вылетать - снизьте значение batch_size. 16 для 24 GB, 8 - 12 GB. musubi группирует картинки по размеру в батчи. Если все картинки разного размера, то и батчи будут маленькие, не будут занимать много vram.
Тренить по видео пока не будем, их надо самому порезать на короткие куски длиной до 5 секунд (я тренил лору на снимание предметов одежды).
# запуск
Запускаем GUI из под конды в командной строке:
Start_Wan_GUI.bat
(кликать мышкой на бат не стоит)
В GUI установите значение "save every N epochs" - например каждую 5-ю. Если вы посреди тренировки нажмете СТОП, то принудительного сохранения не будет, потеряете какой-то промежуточный прогресс.
После тренировки нужно сконвертировать safetensors файл в формат для comfy на третьей вкладке GUI.
лора на Эмму: https://huggingface.co/Ftfyhh/wan1.3b_EmmaW_lora
на раздевание: https://huggingface.co/Ftfyhh/wan_1.3b_lora_pnts_drop
workflow wan vace text2video + ref: https://github.com/Mozer/comfy_stuff/blob/main/workflows/wan_vace_1.3b_ref_and_lora.json
видео с моими лорами (nsfw): https://www.group-telegram.com/tensor_art/616
- треним только на картинках
- в musubi tuner (с GUI)
- я тренил в 640x1024, но можно и 480x832. чем больше размер, тем больше vram
- vram от 4GB (при батче 1)
- тренировка с видео занимает намного больше vram (480x852, 85 frames, batch 1 - 17 GB). В каком разрешении треним, в таком и инференс надо делать. wan vace 1.3b натренирован в разрешении 480x832
- на 30 картинках тренил 1 час на 3090
- на 30 картинках + 14 видео тренил 15 часов (лора на действие)
- для увеличения похожести в vace подаем референсную картинку с лицом
- поддерживается t2v, vace_i2v. (хз про wan-fun, wan-phantom)
- рекомендую инференс через vace_t2v+reference, vace-i2v
Установка под виндой
conda create -n musubi
conda install python=3.10
pip install torch==2.5.1 torchvision --index-url https://download.pytorch.org/whl/cu124
pip install triton-windows
pip install sageattention==1.0.6
git clone https://github.com/Kvento/musubi-tuner-wan-gui
cd musubi-tuner-wan-gui
pip install -r requirements.txt
#создаем папку \musubi-tuner-wan-gui\models\Wan\
mkdir models
cd models
mkdir models Wan
ручками качаем модельки в папку \musubi-tuner-wan-gui\models\Wan\
1.3b: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/diffusion_models/wan2.1_t2v_1.3B_bf16.safetensors
vae: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/vae/wan_2.1_vae.safetensors
t5: https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P/resolve/main/models_t5_umt5-xxl-enc-bf16.pth
clip: https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P/blob/main/models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth
Если вы под виндой - надо в коде выключить libuv и оставить видимость только одной видюхи.
- в файле wan_lora_trainer_gui.py после строк импорта в строке 9 добавить строки:
os.environ["USE_LIBUV"] = "0" # Force-disable libuv for windows
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # id of cuda device, starting from 0
- в файле hv_train_network.py после строк импорта в строке 54 добавить те же строки, что и выше.
# Датасет
30 картинок с лицом. Большинство - лицевые портреты, несколько - в полный рост. С описанием картинок я не заморачивался, ставил везде одинаковое: "Emm4w woman". Но есть вероятность, что подробное описание будет лучше.
картинки с текстовыми описниями вида image1.jpg + image1.txt сюда:
c:\DATA\SD\musubi-tuner-wan-gui\dataset\Emm4w\images\
создаем пустую папку под кэш
c:\DATA\SD\musubi-tuner-wan-gui\dataset\Emm4w\cache\
мой toml конфиг файл с описанием датасета: https://github.com/Mozer/comfy_stuff/blob/main/musubi/dataset_emm4w.toml
положите его внутрь и потом пропишите путь до него в GUI
Внутри там же есть закомментированный пример тренировки на картинках+видео.
в dataset_emm4w.toml файле слэши надо экранировать.
Батчами тренировать быстрее чем по 1 картинке.
в dataset_emm4w.toml измените максимальный размер батча под ваш размер vram. Если будет вылетать - снизьте значение batch_size. 16 для 24 GB, 8 - 12 GB. musubi группирует картинки по размеру в батчи. Если все картинки разного размера, то и батчи будут маленькие, не будут занимать много vram.
Тренить по видео пока не будем, их надо самому порезать на короткие куски длиной до 5 секунд (я тренил лору на снимание предметов одежды).
# запуск
Запускаем GUI из под конды в командной строке:
Start_Wan_GUI.bat
(кликать мышкой на бат не стоит)
В GUI установите значение "save every N epochs" - например каждую 5-ю. Если вы посреди тренировки нажмете СТОП, то принудительного сохранения не будет, потеряете какой-то промежуточный прогресс.
После тренировки нужно сконвертировать safetensors файл в формат для comfy на третьей вкладке GUI.
лора на Эмму: https://huggingface.co/Ftfyhh/wan1.3b_EmmaW_lora
на раздевание: https://huggingface.co/Ftfyhh/wan_1.3b_lora_pnts_drop
workflow wan vace text2video + ref: https://github.com/Mozer/comfy_stuff/blob/main/workflows/wan_vace_1.3b_ref_and_lora.json
видео с моими лорами (nsfw): https://www.group-telegram.com/tensor_art/616
BY Tensor Banana


Share with your friend now:
group-telegram.com/tensorbanana/1195