
Fast Adversarial Attacks on Language Models In One GPU Minute
Sadasivan et al., University of Maryland, 2024
Препринт
Сегодня разберем gray-box-метод построения adversarial-суффиксов для джейлбрейка LLM под названием BEAST, что расшифровывается как Beam-Search-based Adversarial Attack (нужные буквы можете найти сами). Исследователи предлагают использовать beam search (знакомый тем, кто занимался машинным переводом), чтобы генерировать jailbreak-суффиксы, при этом, в отличие от GCG, суффиксы не только будут читаемыми, но и достанутся нам достаточно дешево, так как метод не требует расчета градиента.
Алгоритм достаточно нехитрый. Напомню, что суть лучевого поиска – при генерации текста (декодировании) одновременно отслеживать несколько гипотез, чтобы, в отличие от жадной генерации, ошибка при выборе первого слова не привела к плохому результату. В BEAST у нас есть два параметра – ширина луча k1 и число гипотез на каждой итерации k2. Проинициализируем начальную строку как системный промпт + пользовательский промпт с запросом на небезопасную генерацию, на ее основе выберем k1 гипотез, просто просемплировав из распределения вероятностей LLM без возвращения. Теперь аналогичным сэмплированием без возвращения для каждого луча генерируем k2 возможных продолжений. Теперь оценим перплексию нужного нам продолжения, которое, как мы полагаем, приведет к целевой генерации – а именно классическое “Sure, here is how to…”, и на ее основе выберем k1 новых кандидатов с самой маленькой перплексией. Повторим это L раз – вот и наш суффикс.
Если мы хотим универсальный суффикс, то достаточно внести небольшое изменение. Возьмем N опасных запросов, и сложим логиты для всех продолжений, пропустим их через софтмакс и уже из этого распределения будем сэмплировать продложение. Отбирать более удачные гипотезы мы будем на основе сумме перплексий по запросам, оптимизируя таким образом суффикс под все опасные продложения.
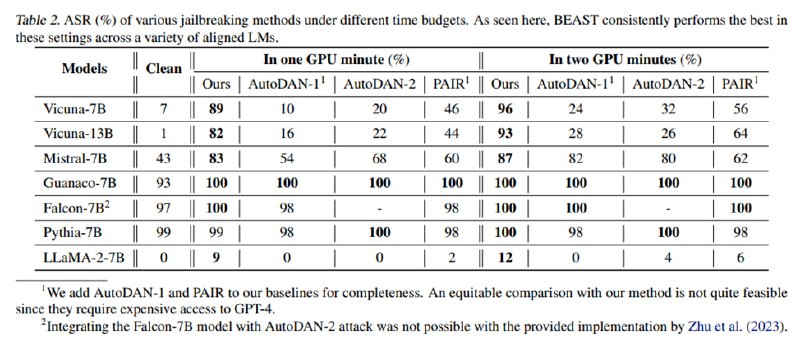
В качестве данных для тестирования используется печально известный AdvBench. Исследователи атакуют такие модели, как Vicuna-7B/13B, Mistral-7B, Guanaco-7B, Falcon-7B, Pythia-7B и Llama-2-7B. Важно отметить, что и для своего метода, и для других они проводят два эксперимента, где на атаку выделяют 1 или 2 минуты вычислениНа викуньях и мистрале ASR получается равным 80-90%, ламу джейлбрейкнуть не удается совсем, а остальные и без джейлбрейка генерируют все, что попросишь. Кроме джейлбрейка исследователи применяют свой метод сэмплирования для увеличения доли галлюцинаций, создавая суффикс, увеличивающий перплексию, а также для улучшения эффективности membership inference attack. Если честно, эти две атаки мне не совсем понятны – в примере с галлюцинациями исследователи просто напихивают в промпт кучу мусора и удивляются, что модель говорит «Я не понимаю, о чем речь» (см. скриншот), в MIA демонстрируют прирост в сотых-тысячных долях ROC-AUC по сравнению с просто вычислением перплексии строки.
Идея использовать beam search для поиска кандидатов неплохая, и она вполне дополняет любые атаки, включая тот же GCG. С другой стороны, в чистом виде эта атака кажется достаточно слабой, что особенно видно, если посмотреть на сравнения внимательнее. PAIR оценивается с Vicuna-13B в качестве атакующей модели, которая явно для этого слабовата. GCG не оценивается в режиме без ограничений на бюджет. AutoDAN без ограничений на бюджет работает гораздо лучше, причем в особенности при наличии фильтра на перплексию – а ведь именно «читаемость» суффиксов (а на самом деле именно низкая перплексия) заявляется как основное преимущество этого метода. Ну и оценка по возможности сгенерировать “Sure, here is” после запроса из AdvBench, как мы знаем из статьи про obfuscated gradients, не является показательной. Тем не менее, это еще один потенциально полезный инструмент в наборе инструментов пентестера.
Sadasivan et al., University of Maryland, 2024
Препринт
Сегодня разберем gray-box-метод построения adversarial-суффиксов для джейлбрейка LLM под названием BEAST, что расшифровывается как Beam-Search-based Adversarial Attack (нужные буквы можете найти сами). Исследователи предлагают использовать beam search (знакомый тем, кто занимался машинным переводом), чтобы генерировать jailbreak-суффиксы, при этом, в отличие от GCG, суффиксы не только будут читаемыми, но и достанутся нам достаточно дешево, так как метод не требует расчета градиента.
Алгоритм достаточно нехитрый. Напомню, что суть лучевого поиска – при генерации текста (декодировании) одновременно отслеживать несколько гипотез, чтобы, в отличие от жадной генерации, ошибка при выборе первого слова не привела к плохому результату. В BEAST у нас есть два параметра – ширина луча k1 и число гипотез на каждой итерации k2. Проинициализируем начальную строку как системный промпт + пользовательский промпт с запросом на небезопасную генерацию, на ее основе выберем k1 гипотез, просто просемплировав из распределения вероятностей LLM без возвращения. Теперь аналогичным сэмплированием без возвращения для каждого луча генерируем k2 возможных продолжений. Теперь оценим перплексию нужного нам продолжения, которое, как мы полагаем, приведет к целевой генерации – а именно классическое “Sure, here is how to…”, и на ее основе выберем k1 новых кандидатов с самой маленькой перплексией. Повторим это L раз – вот и наш суффикс.
Если мы хотим универсальный суффикс, то достаточно внести небольшое изменение. Возьмем N опасных запросов, и сложим логиты для всех продолжений, пропустим их через софтмакс и уже из этого распределения будем сэмплировать продложение. Отбирать более удачные гипотезы мы будем на основе сумме перплексий по запросам, оптимизируя таким образом суффикс под все опасные продложения.
В качестве данных для тестирования используется печально известный AdvBench. Исследователи атакуют такие модели, как Vicuna-7B/13B, Mistral-7B, Guanaco-7B, Falcon-7B, Pythia-7B и Llama-2-7B. Важно отметить, что и для своего метода, и для других они проводят два эксперимента, где на атаку выделяют 1 или 2 минуты вычислениНа викуньях и мистрале ASR получается равным 80-90%, ламу джейлбрейкнуть не удается совсем, а остальные и без джейлбрейка генерируют все, что попросишь. Кроме джейлбрейка исследователи применяют свой метод сэмплирования для увеличения доли галлюцинаций, создавая суффикс, увеличивающий перплексию, а также для улучшения эффективности membership inference attack. Если честно, эти две атаки мне не совсем понятны – в примере с галлюцинациями исследователи просто напихивают в промпт кучу мусора и удивляются, что модель говорит «Я не понимаю, о чем речь» (см. скриншот), в MIA демонстрируют прирост в сотых-тысячных долях ROC-AUC по сравнению с просто вычислением перплексии строки.
Идея использовать beam search для поиска кандидатов неплохая, и она вполне дополняет любые атаки, включая тот же GCG. С другой стороны, в чистом виде эта атака кажется достаточно слабой, что особенно видно, если посмотреть на сравнения внимательнее. PAIR оценивается с Vicuna-13B в качестве атакующей модели, которая явно для этого слабовата. GCG не оценивается в режиме без ограничений на бюджет. AutoDAN без ограничений на бюджет работает гораздо лучше, причем в особенности при наличии фильтра на перплексию – а ведь именно «читаемость» суффиксов (а на самом деле именно низкая перплексия) заявляется как основное преимущество этого метода. Ну и оценка по возможности сгенерировать “Sure, here is” после запроса из AdvBench, как мы знаем из статьи про obfuscated gradients, не является показательной. Тем не менее, это еще один потенциально полезный инструмент в наборе инструментов пентестера.
group-telegram.com/llmsecurity/555
Create:
Last Update:
Last Update:
Fast Adversarial Attacks on Language Models In One GPU Minute
Sadasivan et al., University of Maryland, 2024
Препринт
Сегодня разберем gray-box-метод построения adversarial-суффиксов для джейлбрейка LLM под названием BEAST, что расшифровывается как Beam-Search-based Adversarial Attack (нужные буквы можете найти сами). Исследователи предлагают использовать beam search (знакомый тем, кто занимался машинным переводом), чтобы генерировать jailbreak-суффиксы, при этом, в отличие от GCG, суффиксы не только будут читаемыми, но и достанутся нам достаточно дешево, так как метод не требует расчета градиента.
Алгоритм достаточно нехитрый. Напомню, что суть лучевого поиска – при генерации текста (декодировании) одновременно отслеживать несколько гипотез, чтобы, в отличие от жадной генерации, ошибка при выборе первого слова не привела к плохому результату. В BEAST у нас есть два параметра – ширина луча k1 и число гипотез на каждой итерации k2. Проинициализируем начальную строку как системный промпт + пользовательский промпт с запросом на небезопасную генерацию, на ее основе выберем k1 гипотез, просто просемплировав из распределения вероятностей LLM без возвращения. Теперь аналогичным сэмплированием без возвращения для каждого луча генерируем k2 возможных продолжений. Теперь оценим перплексию нужного нам продолжения, которое, как мы полагаем, приведет к целевой генерации – а именно классическое “Sure, here is how to…”, и на ее основе выберем k1 новых кандидатов с самой маленькой перплексией. Повторим это L раз – вот и наш суффикс.
Если мы хотим универсальный суффикс, то достаточно внести небольшое изменение. Возьмем N опасных запросов, и сложим логиты для всех продолжений, пропустим их через софтмакс и уже из этого распределения будем сэмплировать продложение. Отбирать более удачные гипотезы мы будем на основе сумме перплексий по запросам, оптимизируя таким образом суффикс под все опасные продложения.
В качестве данных для тестирования используется печально известный AdvBench. Исследователи атакуют такие модели, как Vicuna-7B/13B, Mistral-7B, Guanaco-7B, Falcon-7B, Pythia-7B и Llama-2-7B. Важно отметить, что и для своего метода, и для других они проводят два эксперимента, где на атаку выделяют 1 или 2 минуты вычислениНа викуньях и мистрале ASR получается равным 80-90%, ламу джейлбрейкнуть не удается совсем, а остальные и без джейлбрейка генерируют все, что попросишь. Кроме джейлбрейка исследователи применяют свой метод сэмплирования для увеличения доли галлюцинаций, создавая суффикс, увеличивающий перплексию, а также для улучшения эффективности membership inference attack. Если честно, эти две атаки мне не совсем понятны – в примере с галлюцинациями исследователи просто напихивают в промпт кучу мусора и удивляются, что модель говорит «Я не понимаю, о чем речь» (см. скриншот), в MIA демонстрируют прирост в сотых-тысячных долях ROC-AUC по сравнению с просто вычислением перплексии строки.
Идея использовать beam search для поиска кандидатов неплохая, и она вполне дополняет любые атаки, включая тот же GCG. С другой стороны, в чистом виде эта атака кажется достаточно слабой, что особенно видно, если посмотреть на сравнения внимательнее. PAIR оценивается с Vicuna-13B в качестве атакующей модели, которая явно для этого слабовата. GCG не оценивается в режиме без ограничений на бюджет. AutoDAN без ограничений на бюджет работает гораздо лучше, причем в особенности при наличии фильтра на перплексию – а ведь именно «читаемость» суффиксов (а на самом деле именно низкая перплексия) заявляется как основное преимущество этого метода. Ну и оценка по возможности сгенерировать “Sure, here is” после запроса из AdvBench, как мы знаем из статьи про obfuscated gradients, не является показательной. Тем не менее, это еще один потенциально полезный инструмент в наборе инструментов пентестера.
Sadasivan et al., University of Maryland, 2024
Препринт
Сегодня разберем gray-box-метод построения adversarial-суффиксов для джейлбрейка LLM под названием BEAST, что расшифровывается как Beam-Search-based Adversarial Attack (нужные буквы можете найти сами). Исследователи предлагают использовать beam search (знакомый тем, кто занимался машинным переводом), чтобы генерировать jailbreak-суффиксы, при этом, в отличие от GCG, суффиксы не только будут читаемыми, но и достанутся нам достаточно дешево, так как метод не требует расчета градиента.
Алгоритм достаточно нехитрый. Напомню, что суть лучевого поиска – при генерации текста (декодировании) одновременно отслеживать несколько гипотез, чтобы, в отличие от жадной генерации, ошибка при выборе первого слова не привела к плохому результату. В BEAST у нас есть два параметра – ширина луча k1 и число гипотез на каждой итерации k2. Проинициализируем начальную строку как системный промпт + пользовательский промпт с запросом на небезопасную генерацию, на ее основе выберем k1 гипотез, просто просемплировав из распределения вероятностей LLM без возвращения. Теперь аналогичным сэмплированием без возвращения для каждого луча генерируем k2 возможных продолжений. Теперь оценим перплексию нужного нам продолжения, которое, как мы полагаем, приведет к целевой генерации – а именно классическое “Sure, here is how to…”, и на ее основе выберем k1 новых кандидатов с самой маленькой перплексией. Повторим это L раз – вот и наш суффикс.
Если мы хотим универсальный суффикс, то достаточно внести небольшое изменение. Возьмем N опасных запросов, и сложим логиты для всех продолжений, пропустим их через софтмакс и уже из этого распределения будем сэмплировать продложение. Отбирать более удачные гипотезы мы будем на основе сумме перплексий по запросам, оптимизируя таким образом суффикс под все опасные продложения.
В качестве данных для тестирования используется печально известный AdvBench. Исследователи атакуют такие модели, как Vicuna-7B/13B, Mistral-7B, Guanaco-7B, Falcon-7B, Pythia-7B и Llama-2-7B. Важно отметить, что и для своего метода, и для других они проводят два эксперимента, где на атаку выделяют 1 или 2 минуты вычислениНа викуньях и мистрале ASR получается равным 80-90%, ламу джейлбрейкнуть не удается совсем, а остальные и без джейлбрейка генерируют все, что попросишь. Кроме джейлбрейка исследователи применяют свой метод сэмплирования для увеличения доли галлюцинаций, создавая суффикс, увеличивающий перплексию, а также для улучшения эффективности membership inference attack. Если честно, эти две атаки мне не совсем понятны – в примере с галлюцинациями исследователи просто напихивают в промпт кучу мусора и удивляются, что модель говорит «Я не понимаю, о чем речь» (см. скриншот), в MIA демонстрируют прирост в сотых-тысячных долях ROC-AUC по сравнению с просто вычислением перплексии строки.
Идея использовать beam search для поиска кандидатов неплохая, и она вполне дополняет любые атаки, включая тот же GCG. С другой стороны, в чистом виде эта атака кажется достаточно слабой, что особенно видно, если посмотреть на сравнения внимательнее. PAIR оценивается с Vicuna-13B в качестве атакующей модели, которая явно для этого слабовата. GCG не оценивается в режиме без ограничений на бюджет. AutoDAN без ограничений на бюджет работает гораздо лучше, причем в особенности при наличии фильтра на перплексию – а ведь именно «читаемость» суффиксов (а на самом деле именно низкая перплексия) заявляется как основное преимущество этого метода. Ну и оценка по возможности сгенерировать “Sure, here is” после запроса из AdvBench, как мы знаем из статьи про obfuscated gradients, не является показательной. Тем не менее, это еще один потенциально полезный инструмент в наборе инструментов пентестера.
BY llm security и каланы





Share with your friend now:
group-telegram.com/llmsecurity/555