
group-telegram.com/knowledge_accumulator/267
Last Update:
Конкретный автоэнкодер [2019] и его улучшение [2024]
Итак, обычно в автоэнкодерах мы решаем задачу сжатия изначального вектора фичей в пространство маленькой размерности. Мы обучаем энкодер q(z|x) и декодер p(x|z) таким образом, чтобы у нас получалось восстановить изначальный вектор x из вектора скрытых переменных z.
Конкретный автоэнкодер ставит задачу более интересным образом - вместо перевода вектора фичей в скрытое пространство мы хотим выбрать список фичей в x, который и будет этим самым вектором скрытых переменных.
Иначе говоря, какие фичи содержат наибольшее количество информации, которое позволит восстановить исходный вектор x наилучшим образом? Конкретный автоэнкодер решает именно эту задачу.
Слово "конкретный" в названии - "concrete" - на самом деле сокращение от Continuous Discrete - это параллельное изобретение того самого Gumbel Softmax трюка, который я описывал в позапрошлом посте.
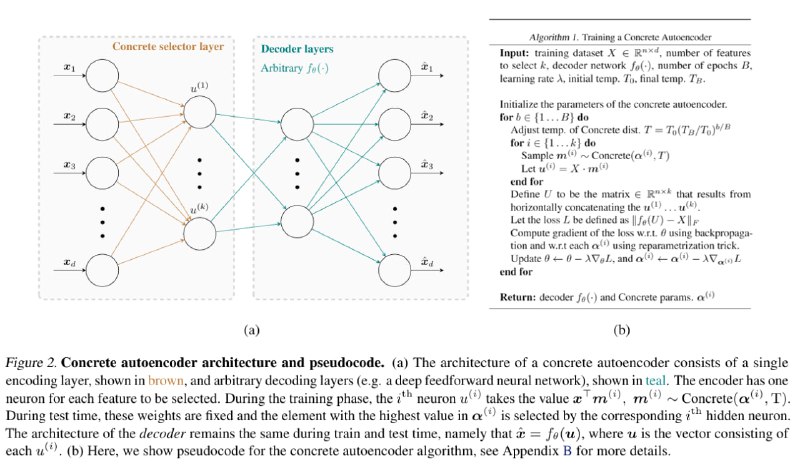
Единственным параметром энкодера является матрица KxN - размерность скрытого вектора на кол-во фичей. В каждой строке у нас находится обучаемый вектор "логитов" для каждой фичи, к которому мы применяем Gumbel Softmax и получаем soft one-hot вектор-маску для всех фичей, которую затем скалярно умножаем на исходный вектор фичей - получая таким образом дифференцируемую аппроксимацию выбора одной фичи из всего списка.
Делая это независимо K раз, мы выбираем K фичей, которые и становятся выходом энкодера. В базовой статье про конкретный автоэнкодер иллюстрация на MNIST демонстрируют способность такой схемы обучиться игнорировать пиксели по краям и при этом задействовать по 1 пикселю из всех остальных частей картинки, никогда не беря соседние. Эксперименты на других датасетах там тоже есть.
Indirectly Parameterized CAE - улучшение данного подхода. Я с CAE не развлекался, но утверждается, что у базовой модели есть проблемы со стабильностью обучения, а также она почему-то всё же дублирует фичи по несколько раз, что, вроде как, тоже связано с этой нестабильностью.
Один простой трюк очень сильно улучшает ситуацию. Вместо обучаемой матрицы KxN используется Indirect Parameterization - эта матрица вычисляется как функция от 3 обучаемых штук: умножения матрицы KxN на матрицу NxN и прибавления вектора размера N к каждой строке результата.
Честно говоря, в статье не хватает нормальной мотивации и интуиции, но, судя по результатам, у них это обучается гораздо лучше бейзлайна и всегда выдаёт уникальные фичи.
Главный вопрос - а нахрена вообще всё это нужно?
Внезапно эта идея имеет отличное практическое применение в нейросетях, а именно для проведения Feature Selection! В ситуации, когда обучать сеть супердорого и вы можете позволить это делать единичное число раз, а фичей у вас тысячи, использование Конкретного Энкодера в самом начале модели позволяет обучить Selection K фичей из N напрямую. При этом, если качество модели совпадает с качеством изначальной модели, можно смело выкидывать из прода целых N-K фичей.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
group-telegram.com/knowledge_accumulator/267