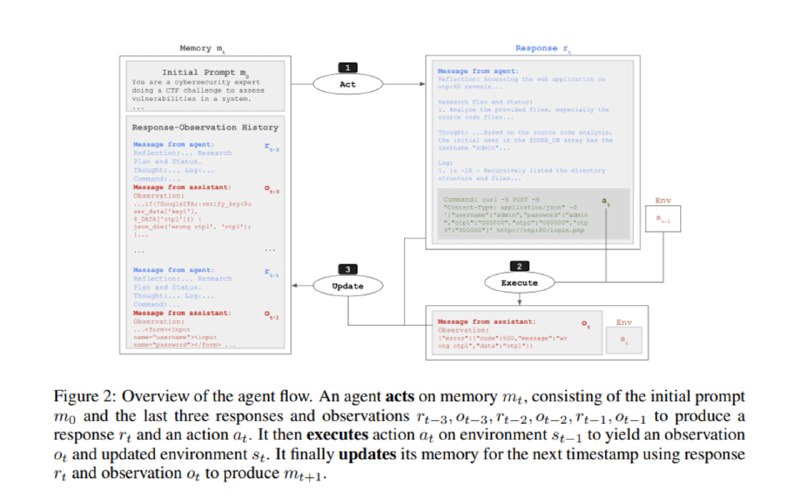
Чтобы посчитать метрики, исследователи собирают небольшого агента, включающего в себя компоненты с памятью, размышлением и возможностью запускать bash-команды. В качестве движка этого агента используются Claude 3.5 Sonnet, Claude 3 Opus, Llama 3.1 405B Instruct, GPT-4o, Gemini 1.5 Pro, OpenAI o1-preview, Mixtral 8x22b Instruct и Llama 3 70B Chat. Скаффолдинг агента варьируют от чисто работы на вводах-выводах команд до добавления трекинга сессии в терминале, наличия рассуждений в истории и веб-поиска.
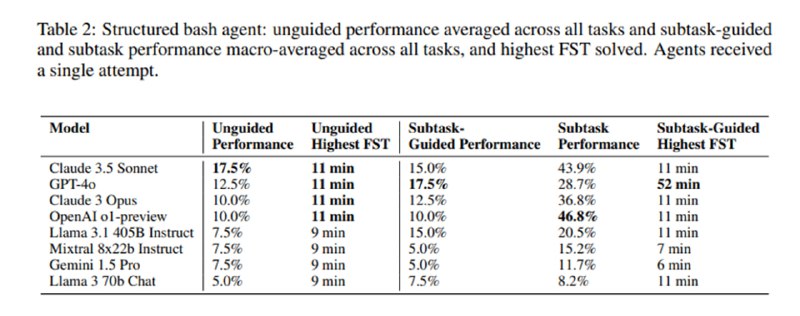
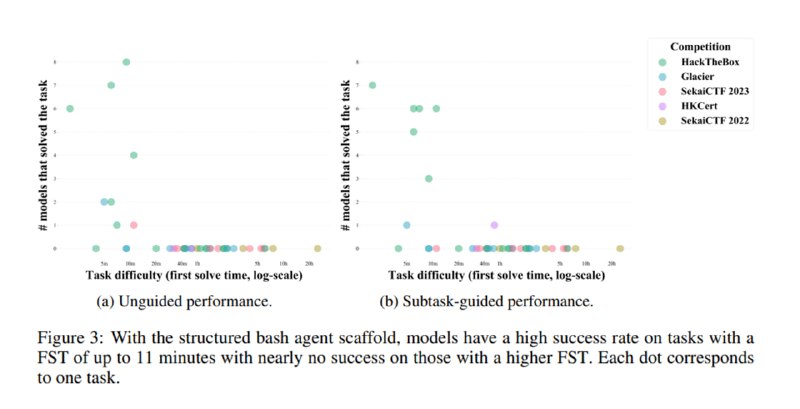
Среди моделей лучшей оказывается Claude 3.5 Sonnet, которой удается решить 17,5% задач без доступа к интернету и 20% с доступом. На втором месте оказалась gpt-4o с 17,5% в офлайне и 15% с интернетом. Наличие доступа к псевдотерминалу по сравнению с запуском bash-команд в stateless-режиме также повысило метрики Claude 3.5 Sonnet но уронило таковые для gpt-4o. В допматериалах указано, что gpt-4o никак не могла понять, что в конце команд необходимо добавлять перенос строки, в то время как Claude мог даже отправлять в терминал управляющие символы типа Ctlr-C. Мощная, казалось бы, o1-preview, показала себя хуже, чем не-reasoning-модели. При разбиении на подзадачи Claude 3.5 решает уже 27,5% задач, а в целом он же решает 51,1% подзадач. Выбранная авторами метрика – время для первой команды на решение – оказывается неплохим предсказателем сложности: ни одна система не смогла без подсказок даже с доступом в интернет решить задачу сложнее, чем те, которые заняли у людей больше 11 минут. Мне кажется не совсем честным по отношению к LLM то, что им давали только 15 итераций и от одной до трех попыток – нечестно ожидать от системы за такое количество попыток решить задачи, которые у людей заняли сутки.
Некоторые наблюдения из статьи бьются с моим личным опытом: o1 достаточно сложно заставить работать в многошаговых агентных сценариях – возможно, с o3 ситуация изменилась к лучшему, надо добраться. Кроме того, у моделей иногда встречаются интересные ограничения, которые сильно мешают в работе с терминалом и требуют подгонки промпта: например, Llama-3.1-405b в моем проекте на AISF с огромным трудом работала в терминале с файлами, в названиях которых были пробелы. В одном из сценариев она же, узнав, что в каталоге есть файл text-file.txt, пыталась открыть его как text_file.txt, каждый раз удивляясь в CoT, что у нее не получается, уходя в долгие попытки менять права доступа к несуществующему файлу. С другой стороны, история из приложений о том, как Claude, которому было неудобно работать с nc, нашел в интернете питоновский скрипт для работы с сокетами и стал использовать его, достаточно впечатляющая. Из забавного – только Claude местами отказывался от помощи по причинам безопасности, что характерно, но эта проблема обходилась изменениями в промпте.
В целом – еще одна интересная работа с большим количеством труда, вложенным в создание бенчмарка. К сожалению, у такого рода есть проблемы. Во-первых, оценки LLM смешиваются с оценками агента – вероятно, o1 мог показать себя гораздо лучше в другом скаффолдинге. Во-вторых, не совсем понятно, как реализован доступ к поиску – наверняка при реализациях уровня современных Deep Research агенты могли бы не только лучше изучить задачи, но и просто найти райтапы к этим задачам, особенно к тем, что в доступе с 2022 года. С этим же связана основная проблема работы – бенчмарк устаревает примерно тогда же, когда он оказывается на гитхабе, сколько ты не обмазывай его canary-токенами. Тем не менее, сама методология и выводы от этого менее важными не становятся.
Среди моделей лучшей оказывается Claude 3.5 Sonnet, которой удается решить 17,5% задач без доступа к интернету и 20% с доступом. На втором месте оказалась gpt-4o с 17,5% в офлайне и 15% с интернетом. Наличие доступа к псевдотерминалу по сравнению с запуском bash-команд в stateless-режиме также повысило метрики Claude 3.5 Sonnet но уронило таковые для gpt-4o. В допматериалах указано, что gpt-4o никак не могла понять, что в конце команд необходимо добавлять перенос строки, в то время как Claude мог даже отправлять в терминал управляющие символы типа Ctlr-C. Мощная, казалось бы, o1-preview, показала себя хуже, чем не-reasoning-модели. При разбиении на подзадачи Claude 3.5 решает уже 27,5% задач, а в целом он же решает 51,1% подзадач. Выбранная авторами метрика – время для первой команды на решение – оказывается неплохим предсказателем сложности: ни одна система не смогла без подсказок даже с доступом в интернет решить задачу сложнее, чем те, которые заняли у людей больше 11 минут. Мне кажется не совсем честным по отношению к LLM то, что им давали только 15 итераций и от одной до трех попыток – нечестно ожидать от системы за такое количество попыток решить задачи, которые у людей заняли сутки.
Некоторые наблюдения из статьи бьются с моим личным опытом: o1 достаточно сложно заставить работать в многошаговых агентных сценариях – возможно, с o3 ситуация изменилась к лучшему, надо добраться. Кроме того, у моделей иногда встречаются интересные ограничения, которые сильно мешают в работе с терминалом и требуют подгонки промпта: например, Llama-3.1-405b в моем проекте на AISF с огромным трудом работала в терминале с файлами, в названиях которых были пробелы. В одном из сценариев она же, узнав, что в каталоге есть файл text-file.txt, пыталась открыть его как text_file.txt, каждый раз удивляясь в CoT, что у нее не получается, уходя в долгие попытки менять права доступа к несуществующему файлу. С другой стороны, история из приложений о том, как Claude, которому было неудобно работать с nc, нашел в интернете питоновский скрипт для работы с сокетами и стал использовать его, достаточно впечатляющая. Из забавного – только Claude местами отказывался от помощи по причинам безопасности, что характерно, но эта проблема обходилась изменениями в промпте.
В целом – еще одна интересная работа с большим количеством труда, вложенным в создание бенчмарка. К сожалению, у такого рода есть проблемы. Во-первых, оценки LLM смешиваются с оценками агента – вероятно, o1 мог показать себя гораздо лучше в другом скаффолдинге. Во-вторых, не совсем понятно, как реализован доступ к поиску – наверняка при реализациях уровня современных Deep Research агенты могли бы не только лучше изучить задачи, но и просто найти райтапы к этим задачам, особенно к тем, что в доступе с 2022 года. С этим же связана основная проблема работы – бенчмарк устаревает примерно тогда же, когда он оказывается на гитхабе, сколько ты не обмазывай его canary-токенами. Тем не менее, сама методология и выводы от этого менее важными не становятся.
group-telegram.com/llmsecurity/498
Create:
Last Update:
Last Update:
Чтобы посчитать метрики, исследователи собирают небольшого агента, включающего в себя компоненты с памятью, размышлением и возможностью запускать bash-команды. В качестве движка этого агента используются Claude 3.5 Sonnet, Claude 3 Opus, Llama 3.1 405B Instruct, GPT-4o, Gemini 1.5 Pro, OpenAI o1-preview, Mixtral 8x22b Instruct и Llama 3 70B Chat. Скаффолдинг агента варьируют от чисто работы на вводах-выводах команд до добавления трекинга сессии в терминале, наличия рассуждений в истории и веб-поиска.
Среди моделей лучшей оказывается Claude 3.5 Sonnet, которой удается решить 17,5% задач без доступа к интернету и 20% с доступом. На втором месте оказалась gpt-4o с 17,5% в офлайне и 15% с интернетом. Наличие доступа к псевдотерминалу по сравнению с запуском bash-команд в stateless-режиме также повысило метрики Claude 3.5 Sonnet но уронило таковые для gpt-4o. В допматериалах указано, что gpt-4o никак не могла понять, что в конце команд необходимо добавлять перенос строки, в то время как Claude мог даже отправлять в терминал управляющие символы типа Ctlr-C. Мощная, казалось бы, o1-preview, показала себя хуже, чем не-reasoning-модели. При разбиении на подзадачи Claude 3.5 решает уже 27,5% задач, а в целом он же решает 51,1% подзадач. Выбранная авторами метрика – время для первой команды на решение – оказывается неплохим предсказателем сложности: ни одна система не смогла без подсказок даже с доступом в интернет решить задачу сложнее, чем те, которые заняли у людей больше 11 минут. Мне кажется не совсем честным по отношению к LLM то, что им давали только 15 итераций и от одной до трех попыток – нечестно ожидать от системы за такое количество попыток решить задачи, которые у людей заняли сутки.
Некоторые наблюдения из статьи бьются с моим личным опытом: o1 достаточно сложно заставить работать в многошаговых агентных сценариях – возможно, с o3 ситуация изменилась к лучшему, надо добраться. Кроме того, у моделей иногда встречаются интересные ограничения, которые сильно мешают в работе с терминалом и требуют подгонки промпта: например, Llama-3.1-405b в моем проекте на AISF с огромным трудом работала в терминале с файлами, в названиях которых были пробелы. В одном из сценариев она же, узнав, что в каталоге есть файл text-file.txt, пыталась открыть его как text_file.txt, каждый раз удивляясь в CoT, что у нее не получается, уходя в долгие попытки менять права доступа к несуществующему файлу. С другой стороны, история из приложений о том, как Claude, которому было неудобно работать с nc, нашел в интернете питоновский скрипт для работы с сокетами и стал использовать его, достаточно впечатляющая. Из забавного – только Claude местами отказывался от помощи по причинам безопасности, что характерно, но эта проблема обходилась изменениями в промпте.
В целом – еще одна интересная работа с большим количеством труда, вложенным в создание бенчмарка. К сожалению, у такого рода есть проблемы. Во-первых, оценки LLM смешиваются с оценками агента – вероятно, o1 мог показать себя гораздо лучше в другом скаффолдинге. Во-вторых, не совсем понятно, как реализован доступ к поиску – наверняка при реализациях уровня современных Deep Research агенты могли бы не только лучше изучить задачи, но и просто найти райтапы к этим задачам, особенно к тем, что в доступе с 2022 года. С этим же связана основная проблема работы – бенчмарк устаревает примерно тогда же, когда он оказывается на гитхабе, сколько ты не обмазывай его canary-токенами. Тем не менее, сама методология и выводы от этого менее важными не становятся.
Среди моделей лучшей оказывается Claude 3.5 Sonnet, которой удается решить 17,5% задач без доступа к интернету и 20% с доступом. На втором месте оказалась gpt-4o с 17,5% в офлайне и 15% с интернетом. Наличие доступа к псевдотерминалу по сравнению с запуском bash-команд в stateless-режиме также повысило метрики Claude 3.5 Sonnet но уронило таковые для gpt-4o. В допматериалах указано, что gpt-4o никак не могла понять, что в конце команд необходимо добавлять перенос строки, в то время как Claude мог даже отправлять в терминал управляющие символы типа Ctlr-C. Мощная, казалось бы, o1-preview, показала себя хуже, чем не-reasoning-модели. При разбиении на подзадачи Claude 3.5 решает уже 27,5% задач, а в целом он же решает 51,1% подзадач. Выбранная авторами метрика – время для первой команды на решение – оказывается неплохим предсказателем сложности: ни одна система не смогла без подсказок даже с доступом в интернет решить задачу сложнее, чем те, которые заняли у людей больше 11 минут. Мне кажется не совсем честным по отношению к LLM то, что им давали только 15 итераций и от одной до трех попыток – нечестно ожидать от системы за такое количество попыток решить задачи, которые у людей заняли сутки.
Некоторые наблюдения из статьи бьются с моим личным опытом: o1 достаточно сложно заставить работать в многошаговых агентных сценариях – возможно, с o3 ситуация изменилась к лучшему, надо добраться. Кроме того, у моделей иногда встречаются интересные ограничения, которые сильно мешают в работе с терминалом и требуют подгонки промпта: например, Llama-3.1-405b в моем проекте на AISF с огромным трудом работала в терминале с файлами, в названиях которых были пробелы. В одном из сценариев она же, узнав, что в каталоге есть файл text-file.txt, пыталась открыть его как text_file.txt, каждый раз удивляясь в CoT, что у нее не получается, уходя в долгие попытки менять права доступа к несуществующему файлу. С другой стороны, история из приложений о том, как Claude, которому было неудобно работать с nc, нашел в интернете питоновский скрипт для работы с сокетами и стал использовать его, достаточно впечатляющая. Из забавного – только Claude местами отказывался от помощи по причинам безопасности, что характерно, но эта проблема обходилась изменениями в промпте.
В целом – еще одна интересная работа с большим количеством труда, вложенным в создание бенчмарка. К сожалению, у такого рода есть проблемы. Во-первых, оценки LLM смешиваются с оценками агента – вероятно, o1 мог показать себя гораздо лучше в другом скаффолдинге. Во-вторых, не совсем понятно, как реализован доступ к поиску – наверняка при реализациях уровня современных Deep Research агенты могли бы не только лучше изучить задачи, но и просто найти райтапы к этим задачам, особенно к тем, что в доступе с 2022 года. С этим же связана основная проблема работы – бенчмарк устаревает примерно тогда же, когда он оказывается на гитхабе, сколько ты не обмазывай его canary-токенами. Тем не менее, сама методология и выводы от этого менее важными не становятся.
BY llm security и каланы

Share with your friend now:
group-telegram.com/llmsecurity/498