group-telegram.com/machinelearning_ru/2231
Last Update:
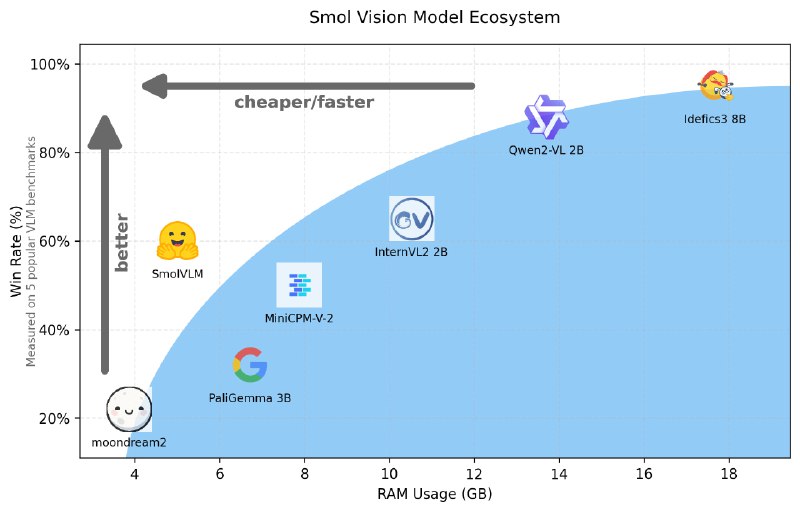
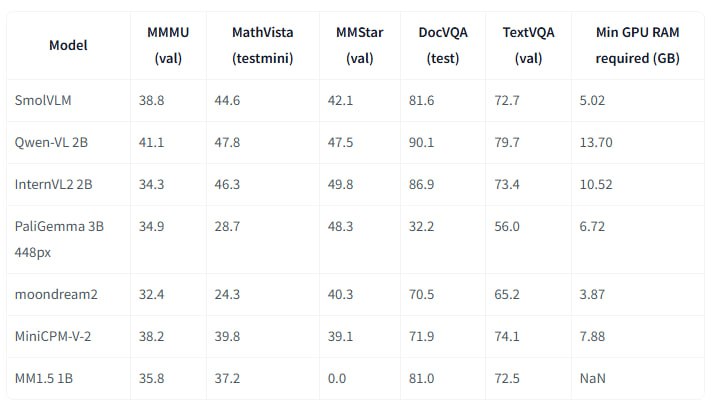
SmolVLM - серия компактных VLM с 2 млрд. параметров, отличающихся высокой эффективностью использования памяти и могут быть развернуты на локальных устройствах с ограниченными ресурсами.
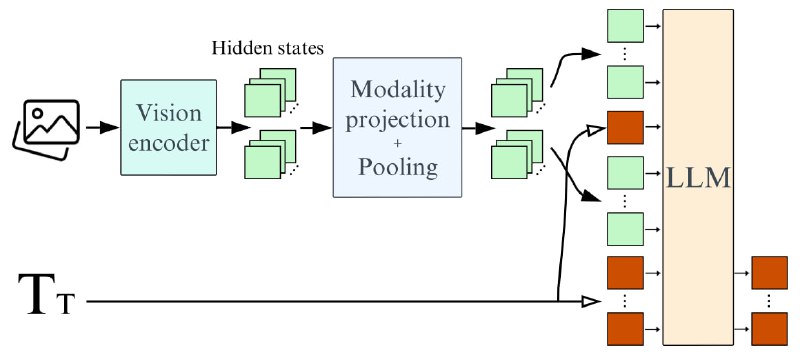
Архитектура SmolVLM основана на Idefics3, с несколькими отличиями:
Модель кодирует каждый патч изображения 384x384 в 81 токен, что позволяет ей обрабатывать тестовые запросы и изображения с использованием всего 1.2 тыс. токенов, в то время как Qwen2-VL использует 16 тыс. токенов. Это преимущество приводит к значительно более высокой скорости предварительной обработки (в 3,3-4,5 раза) и генерации (в 7,5-16 раз) по сравнению с Qwen2-VL.
Для самостоятельной тонкой настройки SmolVLM можно использовать transformers и TRL. Разработчиками представлен блокнот для файнтюна на VQAv2 с использованием LoRA, QLoRA или полной тонкой настройки. SmolVLM интегрирован с TRL для DPO через CLI.
⚠️ При batch sizes=4 и 8-битной загрузке QLoRA файнтюн потребляет около ~16 GB VRAM
@ai_machinelearning_big_data
#AI #ML #SmallVLM #Huggingface