🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
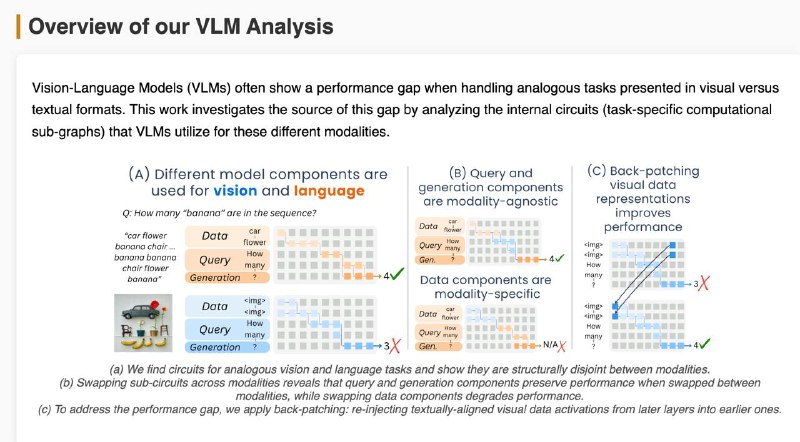
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
The news also helped traders look past another report showing decades-high inflation and shake off some of the volatility from recent sessions. The Bureau of Labor Statistics' February Consumer Price Index (CPI) this week showed another surge in prices even before Russia escalated its attacks in Ukraine. The headline CPI — soaring 7.9% over last year — underscored the sticky inflationary pressures reverberating across the U.S. economy, with everything from groceries to rents and airline fares getting more expensive for everyday consumers. Oh no. There’s a certain degree of myth-making around what exactly went on, so take everything that follows lightly. Telegram was originally launched as a side project by the Durov brothers, with Nikolai handling the coding and Pavel as CEO, while both were at VK. On February 27th, Durov posted that Channels were becoming a source of unverified information and that the company lacks the ability to check on their veracity. He urged users to be mistrustful of the things shared on Channels, and initially threatened to block the feature in the countries involved for the length of the war, saying that he didn’t want Telegram to be used to aggravate conflict or incite ethnic hatred. He did, however, walk back this plan when it became clear that they had also become a vital communications tool for Ukrainian officials and citizens to help coordinate their resistance and evacuations. But Telegram says people want to keep their chat history when they get a new phone, and they like having a data backup that will sync their chats across multiple devices. And that is why they let people choose whether they want their messages to be encrypted or not. When not turned on, though, chats are stored on Telegram's services, which are scattered throughout the world. But it has "disclosed 0 bytes of user data to third parties, including governments," Telegram states on its website. NEWS
from nl