
Суть атаки в следующем. У нас есть гипотеза, что есть несколько регионов в пространстве активаций большой языковой модели, которые приводят к одной и той же генерации. У нас есть некоторая защита – для простоты возьмем линейный классификатор – которая обучена на активациях какого-нибудь слоя разделять активации, которые вызываются джейлбрейками и прочим недопустимым выводом, от обычных допустимых запросов. Давайте попробуем найти такой вызывающий недопустимый ввод регион, который находится по другую сторону от разделяющей гиперплоскости классификатора. Возможно ли это? Оказывается, что да.
Для этого мы будем решать оптимизационную задачу: сохранить поведение таким же (назовем это поведенческой функцией потерь) и при этом обмануть классификатор (функция потерь обфускации). В качестве последнего может выступать собственно скор линейного или MLP-классификатора, KL-дивергенция при детектировании OOD или даже сила активации признака, если в качестве детектора мы используем SAE. Для поведенческого лосса возьмем просто кросс-энтропию для необходимого нам продолжения. Для оценки эффективности возьмем StrongREJECT, метрикой же будет выступать Recall@FPR при FPR равном достаточно либеральным 1%. Жертвой выступит Llama-3-8B.
В качестве адверсариал-суффикса можно использовать как софт-промпт (эмбеддинги, которым не соответствуют реальные токены), так и пространство токенов, причем в пространстве токенов атака делается на базе FLRT без доступа к градиентам. Результатом такой атаки становится 0% детектирования атак при ~80% успеха с точки зрения недопустимого вывода, причем атаки против одного детектора (например, OOD) переносятся на другой, например, MLP. Кроме того, если натренировать детектор обнаруживать активации, связанные с обфусцирующим суффиксом, то атакующий может найти еще один регион, который приведет к джейлбрейку – и такой пинг-понг может продолжаться десятки раз: исследователи провели эксперимент, в котором атакующий находил новый суффикс после 70 итераций.
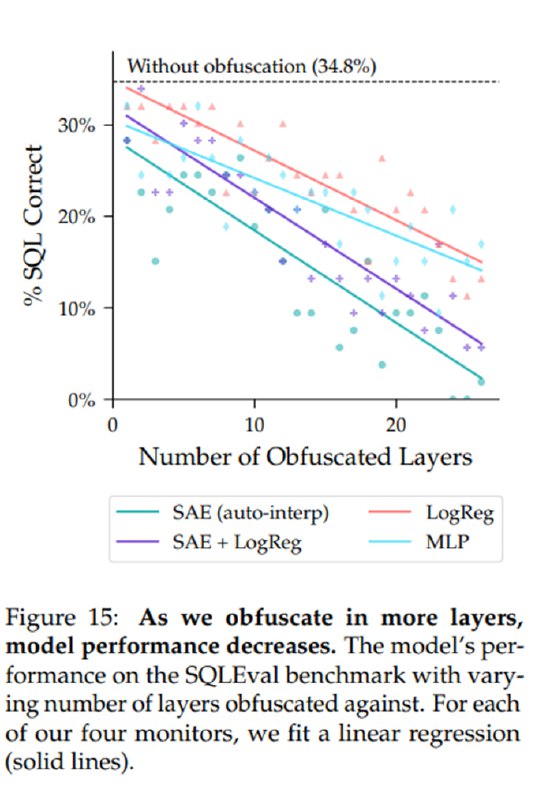
В случае с SAE детектор отслеживает, есть ли интересующие нас активации в пространстве разреженного автоэнкодера – там активации каждого нейрона имеют, как предполагается, достаточно однозначную семантику. В качестве атак исследователи ищут такой суффикс, чтобы заставить модель генерировать SQL, не возбуждая признаки, связанные с SQL. SQL вместо джейлбрейка выбирается, чтобы можно было легко оценить качество генерации – достаточно выполнить запрос и проверить результат. Это у них, разумеется, получается: модель, в данном случае Gemma-2-2B, генерирует SQL, не вызывая детекта со стороны монитора SAE, в 100% случаев при чувствительности монитора в 2% FPR. Но здесь находится и ограничение: чем на большем количестве слоев мы пытаемся обфусцировать активации, тем хуже качество SQL: с 34% бейзлайна (без атаки) падение качества может составить до 10% уже при попытках обфускации на 10 слоях.
Для этого мы будем решать оптимизационную задачу: сохранить поведение таким же (назовем это поведенческой функцией потерь) и при этом обмануть классификатор (функция потерь обфускации). В качестве последнего может выступать собственно скор линейного или MLP-классификатора, KL-дивергенция при детектировании OOD или даже сила активации признака, если в качестве детектора мы используем SAE. Для поведенческого лосса возьмем просто кросс-энтропию для необходимого нам продолжения. Для оценки эффективности возьмем StrongREJECT, метрикой же будет выступать Recall@FPR при FPR равном достаточно либеральным 1%. Жертвой выступит Llama-3-8B.
В качестве адверсариал-суффикса можно использовать как софт-промпт (эмбеддинги, которым не соответствуют реальные токены), так и пространство токенов, причем в пространстве токенов атака делается на базе FLRT без доступа к градиентам. Результатом такой атаки становится 0% детектирования атак при ~80% успеха с точки зрения недопустимого вывода, причем атаки против одного детектора (например, OOD) переносятся на другой, например, MLP. Кроме того, если натренировать детектор обнаруживать активации, связанные с обфусцирующим суффиксом, то атакующий может найти еще один регион, который приведет к джейлбрейку – и такой пинг-понг может продолжаться десятки раз: исследователи провели эксперимент, в котором атакующий находил новый суффикс после 70 итераций.
В случае с SAE детектор отслеживает, есть ли интересующие нас активации в пространстве разреженного автоэнкодера – там активации каждого нейрона имеют, как предполагается, достаточно однозначную семантику. В качестве атак исследователи ищут такой суффикс, чтобы заставить модель генерировать SQL, не возбуждая признаки, связанные с SQL. SQL вместо джейлбрейка выбирается, чтобы можно было легко оценить качество генерации – достаточно выполнить запрос и проверить результат. Это у них, разумеется, получается: модель, в данном случае Gemma-2-2B, генерирует SQL, не вызывая детекта со стороны монитора SAE, в 100% случаев при чувствительности монитора в 2% FPR. Но здесь находится и ограничение: чем на большем количестве слоев мы пытаемся обфусцировать активации, тем хуже качество SQL: с 34% бейзлайна (без атаки) падение качества может составить до 10% уже при попытках обфускации на 10 слоях.
group-telegram.com/llmsecurity/535
Create:
Last Update:
Last Update:
Суть атаки в следующем. У нас есть гипотеза, что есть несколько регионов в пространстве активаций большой языковой модели, которые приводят к одной и той же генерации. У нас есть некоторая защита – для простоты возьмем линейный классификатор – которая обучена на активациях какого-нибудь слоя разделять активации, которые вызываются джейлбрейками и прочим недопустимым выводом, от обычных допустимых запросов. Давайте попробуем найти такой вызывающий недопустимый ввод регион, который находится по другую сторону от разделяющей гиперплоскости классификатора. Возможно ли это? Оказывается, что да.
Для этого мы будем решать оптимизационную задачу: сохранить поведение таким же (назовем это поведенческой функцией потерь) и при этом обмануть классификатор (функция потерь обфускации). В качестве последнего может выступать собственно скор линейного или MLP-классификатора, KL-дивергенция при детектировании OOD или даже сила активации признака, если в качестве детектора мы используем SAE. Для поведенческого лосса возьмем просто кросс-энтропию для необходимого нам продолжения. Для оценки эффективности возьмем StrongREJECT, метрикой же будет выступать Recall@FPR при FPR равном достаточно либеральным 1%. Жертвой выступит Llama-3-8B.
В качестве адверсариал-суффикса можно использовать как софт-промпт (эмбеддинги, которым не соответствуют реальные токены), так и пространство токенов, причем в пространстве токенов атака делается на базе FLRT без доступа к градиентам. Результатом такой атаки становится 0% детектирования атак при ~80% успеха с точки зрения недопустимого вывода, причем атаки против одного детектора (например, OOD) переносятся на другой, например, MLP. Кроме того, если натренировать детектор обнаруживать активации, связанные с обфусцирующим суффиксом, то атакующий может найти еще один регион, который приведет к джейлбрейку – и такой пинг-понг может продолжаться десятки раз: исследователи провели эксперимент, в котором атакующий находил новый суффикс после 70 итераций.
В случае с SAE детектор отслеживает, есть ли интересующие нас активации в пространстве разреженного автоэнкодера – там активации каждого нейрона имеют, как предполагается, достаточно однозначную семантику. В качестве атак исследователи ищут такой суффикс, чтобы заставить модель генерировать SQL, не возбуждая признаки, связанные с SQL. SQL вместо джейлбрейка выбирается, чтобы можно было легко оценить качество генерации – достаточно выполнить запрос и проверить результат. Это у них, разумеется, получается: модель, в данном случае Gemma-2-2B, генерирует SQL, не вызывая детекта со стороны монитора SAE, в 100% случаев при чувствительности монитора в 2% FPR. Но здесь находится и ограничение: чем на большем количестве слоев мы пытаемся обфусцировать активации, тем хуже качество SQL: с 34% бейзлайна (без атаки) падение качества может составить до 10% уже при попытках обфускации на 10 слоях.
Для этого мы будем решать оптимизационную задачу: сохранить поведение таким же (назовем это поведенческой функцией потерь) и при этом обмануть классификатор (функция потерь обфускации). В качестве последнего может выступать собственно скор линейного или MLP-классификатора, KL-дивергенция при детектировании OOD или даже сила активации признака, если в качестве детектора мы используем SAE. Для поведенческого лосса возьмем просто кросс-энтропию для необходимого нам продолжения. Для оценки эффективности возьмем StrongREJECT, метрикой же будет выступать Recall@FPR при FPR равном достаточно либеральным 1%. Жертвой выступит Llama-3-8B.
В качестве адверсариал-суффикса можно использовать как софт-промпт (эмбеддинги, которым не соответствуют реальные токены), так и пространство токенов, причем в пространстве токенов атака делается на базе FLRT без доступа к градиентам. Результатом такой атаки становится 0% детектирования атак при ~80% успеха с точки зрения недопустимого вывода, причем атаки против одного детектора (например, OOD) переносятся на другой, например, MLP. Кроме того, если натренировать детектор обнаруживать активации, связанные с обфусцирующим суффиксом, то атакующий может найти еще один регион, который приведет к джейлбрейку – и такой пинг-понг может продолжаться десятки раз: исследователи провели эксперимент, в котором атакующий находил новый суффикс после 70 итераций.
В случае с SAE детектор отслеживает, есть ли интересующие нас активации в пространстве разреженного автоэнкодера – там активации каждого нейрона имеют, как предполагается, достаточно однозначную семантику. В качестве атак исследователи ищут такой суффикс, чтобы заставить модель генерировать SQL, не возбуждая признаки, связанные с SQL. SQL вместо джейлбрейка выбирается, чтобы можно было легко оценить качество генерации – достаточно выполнить запрос и проверить результат. Это у них, разумеется, получается: модель, в данном случае Gemma-2-2B, генерирует SQL, не вызывая детекта со стороны монитора SAE, в 100% случаев при чувствительности монитора в 2% FPR. Но здесь находится и ограничение: чем на большем количестве слоев мы пытаемся обфусцировать активации, тем хуже качество SQL: с 34% бейзлайна (без атаки) падение качества может составить до 10% уже при попытках обфускации на 10 слоях.
BY llm security и каланы




Share with your friend now:
group-telegram.com/llmsecurity/535