group-telegram.com/ai_machinelearning_big_data/5871
Last Update:
Архитектура Transformer доминирует в моделировании последовательностей уже несколько лет, демонстрируя отличные результаты в задачах NLP, машинного перевода и генерации текста. Главный недостаток Transformer — они долго считают длинные последовательности. А если вычислительных ресурсов мало, то реализация занимает либо много времени, либо требует их увеличения.
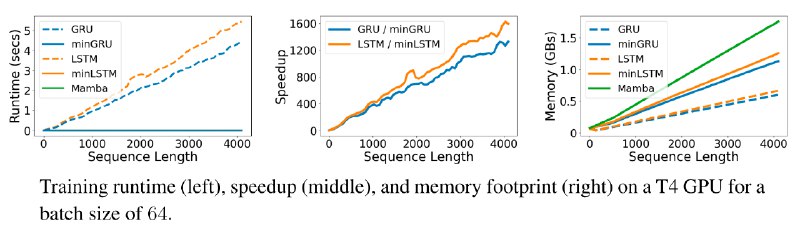
Авторы исследования предлагают вернуться к RNN, ведь они быстрее считают и параллельно учитывают контекст. Чтобы отвязаться от обратного распространения ошибки (BPTT), которая требует линейного времени обучения, применяется алгоритм параллельного сканирования за счет устранения зависимости от срытых состояний из гейтов LSTM и GRU.
В предлагаемом методе представлены "уменьшенные" LTSM и GRU - minLSTM и minGRU. Они не только обучаются параллельно, но и используют значительно меньше параметров, чем их старшие аналоги.
Минимализм версий достигается следующим образом:
В minLSTM и minGRU input, forget и update gate зависят только от входных данных, а не от предыдущих скрытых состояний.
В традиционных LSTM и GRU функция гиперболического тангенса используется для ограничения диапазона значений скрытых состояний. В minLSTM и minGRU это ограничение снимается.
Для minLSTM выполняется нормализация forget и input гейтов, чтобы гарантировать, что масштаб состояния ячейки не зависит от времени.
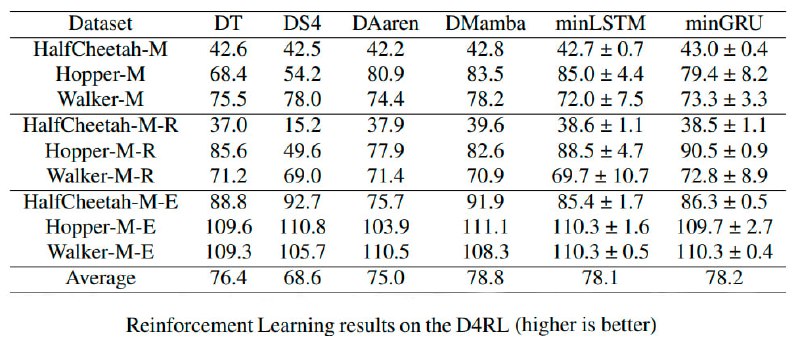
Результаты экспериментов:
Прикладная реализация численно-устойчивой в логарифмическом пространстве версии метода minGRU на Pytorch представлена в репозитории на Github.
# Install miniGRU-pytorch
pip install minGRU-pytorch
# Usage
import torch
from minGRU_pytorch import minGRU
min_gru = minGRU(512)
x = torch.randn(2, 1024, 512)
out = min_gru(x)
assert x.shape == out.shape
# Sanity check
import torch
from minGRU_pytorch import minGRU
min_gru = minGRU(dim = 512, expansion_factor = 1.5)
x = torch.randn(1, 2048, 512)
# parallel
parallel_out = min_gru(x)[:, -1:]
# sequential
prev_hidden = None
for token in x.unbind(dim = 1):
sequential_out, prev_hidden = min_gru(token[:, None, :], prev_hidden, return_next_prev_hidden = True)
assert torch.allclose(parallel_out, sequential_out, atol = 1e-4)
@ai_machinelearning_big_data
#AI #ML #RNN #miniGRU