Hewer, Hutton, [2024] "Quotient Haskell: lightweight quotient types for all"
Мой порт секций 2+3 на Cubical Agda: source
У субтипов есть дуальная редко используемая, но полезная конструкция - фактор-типы. Для субтипа мы доказываем выполнение предиката при конструировании, а для фактор-типа - при элиминации. Классический пример программистской фактор-конструкции - мультимножества (bags), т.е. списки, факторизованные по перестановке элементов. При работе с такой конструкцией для каждой функции, принимающей bag аргументом, нужно доказывать, что её результат не зависит от перестановок нижележащего списка. Эти пруф-обязательства можно автоматизировать, ограничив логику до SMT-разрешимой. Так мы получаем систему рефайнмент-типов, например автоматизация для субтипов широко используется в LiquidHaskell. Однако, автоматизация для фактор-типов менее изучена, каковой пробел и восполняет статья, вводя расширение LH - QuotientHaskell. Основная идея состоит в переводе эквациональных законов, требуемых функциями на фактор-типах, в предикаты refinement логики. Класс поддерживаемых фактор-типов - quotient inductive types (QIT), где конструкторы индуктивного типа определяются одновременно с уравнениями для данных. Первая часть статьи посвящена трем мотивирующим примерам.
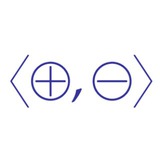
Первый пример - "мобили", бинарные деревья с данными в нодах, факторизованные по зеркальному отражению ветвей (
Любое дерево можно рассматривать как мобиль, но количество валидных функций для последних меньше - мы не можем использовать функции, дающие разные результаты при обходе ветвей слева направо и справа налево, но можем, например, суммировать все числа в дереве (т.к. сложение коммутативно) или использовать map по значениям (т.к. он не учитывает позициональную информацию). Свёртку дерева также нельзя использовать напрямую, но можно добавить предусловие о неразличении ветвей к передаваемой аргументом функции, и для этого нужно использовать вспомогательную ручную машинерию в помощь SMT-солверу.
Следующий пример - "бум-иерархия": деревья с (опциональными) данными в листьях -> списки -> (конечные) мультимножества -> множества.
* Чтобы получить списка из дерева, нужно факторизовать его по законам моноида (где "сложение" это конструктор ноды). Конкатенация такого фактор-списка имеет константную сложность, т.к. мы просто добавляем новую ноду, не пересчитывая нормальную форму списка - это может быть полезно, когда у нас много подобных операций, а линейное представление списка используется редко. На факторизованных списках работают древесные операции, сохраняющие структуру моноида -
* Мультимножества получаются повторной факторизацией по коммутативности "сложения", аналогично мобилям. Это отсекает функции, учитывающие порядок элементов, например,
* Множества получаются окончательной факторизацией по идемпотентности, что запрещающает различать разные вхождения одного и того же элемента. Мы по-прежнему можем использовать функции типа
Мой порт секций 2+3 на Cubical Agda: source
У субтипов есть дуальная редко используемая, но полезная конструкция - фактор-типы. Для субтипа мы доказываем выполнение предиката при конструировании, а для фактор-типа - при элиминации. Классический пример программистской фактор-конструкции - мультимножества (bags), т.е. списки, факторизованные по перестановке элементов. При работе с такой конструкцией для каждой функции, принимающей bag аргументом, нужно доказывать, что её результат не зависит от перестановок нижележащего списка. Эти пруф-обязательства можно автоматизировать, ограничив логику до SMT-разрешимой. Так мы получаем систему рефайнмент-типов, например автоматизация для субтипов широко используется в LiquidHaskell. Однако, автоматизация для фактор-типов менее изучена, каковой пробел и восполняет статья, вводя расширение LH - QuotientHaskell. Основная идея состоит в переводе эквациональных законов, требуемых функциями на фактор-типах, в предикаты refinement логики. Класс поддерживаемых фактор-типов - quotient inductive types (QIT), где конструкторы индуктивного типа определяются одновременно с уравнениями для данных. Первая часть статьи посвящена трем мотивирующим примерам.
Первый пример - "мобили", бинарные деревья с данными в нодах, факторизованные по зеркальному отражению ветвей (
Node l a r == Node r a l). Для создания фактор-типа нужно добавить "высший" конструктор нужного равенства (в гомотопической терминологии - "пути"). В логике QH эти конструкторы становятся обычными равенствами; ключевой момент - терм в левой части уравения должен иметь каноническую (конструкторную) форму. Фактор-определения технически создают новый тип, а не являются рефайнментом старого.Любое дерево можно рассматривать как мобиль, но количество валидных функций для последних меньше - мы не можем использовать функции, дающие разные результаты при обходе ветвей слева направо и справа налево, но можем, например, суммировать все числа в дереве (т.к. сложение коммутативно) или использовать map по значениям (т.к. он не учитывает позициональную информацию). Свёртку дерева также нельзя использовать напрямую, но можно добавить предусловие о неразличении ветвей к передаваемой аргументом функции, и для этого нужно использовать вспомогательную ручную машинерию в помощь SMT-солверу.
Следующий пример - "бум-иерархия": деревья с (опциональными) данными в листьях -> списки -> (конечные) мультимножества -> множества.
* Чтобы получить списка из дерева, нужно факторизовать его по законам моноида (где "сложение" это конструктор ноды). Конкатенация такого фактор-списка имеет константную сложность, т.к. мы просто добавляем новую ноду, не пересчитывая нормальную форму списка - это может быть полезно, когда у нас много подобных операций, а линейное представление списка используется редко. На факторизованных списках работают древесные операции, сохраняющие структуру моноида -
sum, map, filter. * Мультимножества получаются повторной факторизацией по коммутативности "сложения", аналогично мобилям. Это отсекает функции, учитывающие порядок элементов, например,
toList.* Множества получаются окончательной факторизацией по идемпотентности, что запрещающает различать разные вхождения одного и того же элемента. Мы по-прежнему можем использовать функции типа
contains, но уже не имеем права подсчитывать количество вхождений.Последний классический пример фактор-конструкции это рациональные числа, получаемые факторизацией пар целых чисел по равенству перекрестных произведений числителя на знаменатель. Такой подход позволяет не скрывать внутреннюю структуру типа в целях сохранения инварианта. В определении также используется рефайнмент знаменателя до ненулевых чисел. Важно выбрать удобное определение спецификации для факторизации - вместо произведения можно использовать GCD, но тогда в доказательствах придется рассуждать о его свойствах, что потенциально менее автоматизируемо. Для извлечения числителя и знаменателя нужно сначала определить функцию
Ядром QH является λQ, лямбда-исчисление с паттернами (термами первого порядка, построенными из конструкторов и переменных) - расширение λL, ядра жидких типов. К контекстам добавляются факторы и guard-предикаты (высказывания, соответствующие истинным предположениям внутри if-веток). Фактор - это набор квантифицированных переменных и тройка из refinement предиката, паттерна (левая часть равенства) и терма общего вида (правая часть). Для факторов нужна подстановка, также факторы могут применяться одновременно, но должны быть попарно независимы. Для корректности необходимо вычислять most general unifiers (MGU) для паттернов. Стоит также отметить, что система не поддерживает расширение фактор-типов до GADT, т.наз. quotient inductive families. Наконец, показывается, что конгруэтность функций (
Также, для удобства пользователя, λQ вводит на фактор-типах порядок субтипизации, что позволяет напрямую использовать "менее" факторизованные типы в функциях на "более" факторизованных (т.е., контравариантность).
Система вводит два класса равенств - пропозициональное равенство из рефайнмент логики, и расширенное judgemental равенство в системе типов, более слабое. Это второе равенство позволяет конструировать из системы факторов в контексте набор уравнений, который далее будет передан SMT-солверу. Правила для манипуляции расширенными равенствами выстроены таким образом, чтобы получить завершающийся тайпчекинг и соблюсти все хорошие свойства, ожидаемые от равенства. Потенциально проблематичным, однако, является наивный полный перебор всех комбинаций из n факторов в контексте, т.е. n! вариантов; авторы утверждают, что на практике это число достаточно мало.
QH построен как расширение LiquidHaskell, он вносит изменения в парсер (фактор-выражения и вспомогательные доказательства соблюдения фактор-равенств), AST, процесс генерации равенств и тайпчекинг для case-выражений. Используемый язык паттернов это урезанная версия хаскельных паттернов (нет wildcards, irrefutable patterns, as-patterns). Тайпчекинг фактор-типов включает в себя ряд этапов: проверка грамматической корректности, лифтинг равенств (генерация уравнений для солвера), проверка соблюдения фактор-условий при элиминации факторизованных данных (на этой фазе важно иметь термы в нормальной форме, из чего вытекает требование включения PLE по умолчанию), процедуру разрешимости для субтипизации фактортипов. Для быстродействия вычисленные отношения субтипизации кэшируются, и производятся оптимизации для тривиальных теорем.
В качестве схожих работ авторы приводят Cubical Agda (чьими фактор-типами они явно вдохновлялись), аксиоматизацию факторов в Lean, разрешимые факторы в Coq/Mathcomp, ряд реализаций в Isabelle и реализацию в NuPRL. Последние два пункта идеологически близки, поскольку предполагают сопутствующую автоматизацию, однако реализации в Isabelle имеют более низкий уровень автоматизации, а NuPRL требует принятия аксиомы выбора.
reduce, вычисляющую нормальную форму дроби через всё тот же GCD. Авторы отмечают, что для корректной работы QH нужно включенное по умолчанию расширение PLE (алгоритм поиска доказательств из набора уравнений в контексте).Ядром QH является λQ, лямбда-исчисление с паттернами (термами первого порядка, построенными из конструкторов и переменных) - расширение λL, ядра жидких типов. К контекстам добавляются факторы и guard-предикаты (высказывания, соответствующие истинным предположениям внутри if-веток). Фактор - это набор квантифицированных переменных и тройка из refinement предиката, паттерна (левая часть равенства) и терма общего вида (правая часть). Для факторов нужна подстановка, также факторы могут применяться одновременно, но должны быть попарно независимы. Для корректности необходимо вычислять most general unifiers (MGU) для паттернов. Стоит также отметить, что система не поддерживает расширение фактор-типов до GADT, т.наз. quotient inductive families. Наконец, показывается, что конгруэтность функций (
a = b -> f a = f b) сохраняется для факторизованных равенств. Также, для удобства пользователя, λQ вводит на фактор-типах порядок субтипизации, что позволяет напрямую использовать "менее" факторизованные типы в функциях на "более" факторизованных (т.е., контравариантность).
Система вводит два класса равенств - пропозициональное равенство из рефайнмент логики, и расширенное judgemental равенство в системе типов, более слабое. Это второе равенство позволяет конструировать из системы факторов в контексте набор уравнений, который далее будет передан SMT-солверу. Правила для манипуляции расширенными равенствами выстроены таким образом, чтобы получить завершающийся тайпчекинг и соблюсти все хорошие свойства, ожидаемые от равенства. Потенциально проблематичным, однако, является наивный полный перебор всех комбинаций из n факторов в контексте, т.е. n! вариантов; авторы утверждают, что на практике это число достаточно мало.
QH построен как расширение LiquidHaskell, он вносит изменения в парсер (фактор-выражения и вспомогательные доказательства соблюдения фактор-равенств), AST, процесс генерации равенств и тайпчекинг для case-выражений. Используемый язык паттернов это урезанная версия хаскельных паттернов (нет wildcards, irrefutable patterns, as-patterns). Тайпчекинг фактор-типов включает в себя ряд этапов: проверка грамматической корректности, лифтинг равенств (генерация уравнений для солвера), проверка соблюдения фактор-условий при элиминации факторизованных данных (на этой фазе важно иметь термы в нормальной форме, из чего вытекает требование включения PLE по умолчанию), процедуру разрешимости для субтипизации фактортипов. Для быстродействия вычисленные отношения субтипизации кэшируются, и производятся оптимизации для тривиальных теорем.
В качестве схожих работ авторы приводят Cubical Agda (чьими фактор-типами они явно вдохновлялись), аксиоматизацию факторов в Lean, разрешимые факторы в Coq/Mathcomp, ряд реализаций в Isabelle и реализацию в NuPRL. Последние два пункта идеологически близки, поскольку предполагают сопутствующую автоматизацию, однако реализации в Isabelle имеют более низкий уровень автоматизации, а NuPRL требует принятия аксиомы выбора.
В конце статьи авторы обозревают свои достижения: интеграцию с SMT-автоматизированной системой субтипов, реализацию QITs, неявные преобразования между функциями на типах разной степени факторизованности. Кроме того, остался еще ряд примеров, которыми они спешат поделиться: реализация модульной арифметики, факторизованная система полярных координат, лямбда-исчисление со вшитым eta-равенством. В качестве ограничений называются: отсутствие function extensionality, GADTs/QIFs и неинтуитивные сообщения об ошибках. Работу над этими моментами, а также над автоматическим выводом фактор-типов авторы оставляют на будущее.
2024-FPMad-FPaRwI.pdf
460.8 KB
Во вторник, 9 апреля, снова читал доклад про отложенную рекурсию, на этот раз постарался сделать его более "программистским", добавив больше примеров использования.
Набор постов от William Bowman по понятиям ТЯП (реализуемость, логические отношения, синтаксис, модель):
https://www.williamjbowman.com/blog/2022/10/05/what-is-realizability/
https://www.williamjbowman.com/blog/2023/03/24/what-is-logical-relations/
https://www.williamjbowman.com/blog/2023/06/07/what-is-syntax/
https://www.williamjbowman.com/blog/2023/06/15/what-is-a-model/
https://www.williamjbowman.com/blog/2022/10/05/what-is-realizability/
https://www.williamjbowman.com/blog/2023/03/24/what-is-logical-relations/
https://www.williamjbowman.com/blog/2023/06/07/what-is-syntax/
https://www.williamjbowman.com/blog/2023/06/15/what-is-a-model/
Williamjbowman
What is realizability?
I recently decided to confront the fact that I didn't know what "realizability" meant. I see it in programming languages papers from time to time, and could see little rhyme or reason to how it was used. Any time I tried to look it up, I got some nonsense...
2024-IMDEA-FPaRwI.pdf
398.1 KB
И еще одна слегка расширенная версия доклада про отложенную рекурсию: добавил немного примеров с доказательствами.
Bertot, [2008] "Structural abstract interpretation, A formal study using Coq"
+ порт на Агду
В статье обсуждается кодирование внутри теории типов подхода к статическому анализу программ, известного как абстрактная интерпретация (АИ). Для анализа взят простой императивный язык с целочисленными значениями (можно ограничить до натуральных) со сложением и булевым сравнением, мутабельными переменными, последовательной композицией и while-циклами. Корректность полученного абстрактного интерпретатора доказана относительно аксиоматической (Хоаровой) семантики языка, а гарантия завершимости получается по построению.
Идея абстрактной интерпретации заключается в вычислении приближенных значений для некоторых аспектов поведения программы - обычно анализ делается по графу потока управления программы, но в статье анализируется напрямую синтаксическое дерево. Такую аппроксимацию, как правило, можно получить значительно быстрее, нежели исполнять саму программу, при этом на её основании можно проводить компиляторные оптимизации и делать выводы о корректности. Стандартным примером приближенного анализа является огрубление точных значений числовых переменных до бита четности или интервала значений. Классически при этом выводится аппроксимация "сверху" (overapproximation), т.е. мы хотим гарантировать отсутствие ложноотрицательных результатов за счет возможных ложноположительных (стандартный компромисс статического анализа). Формально отношения между точными (конкретными) и приближенными (абстрактными) множествами значений описываются в теории АИ через соответствия Галуа (пара функции абстракции α и функции конкретизации γ, необходимы для транспорта отношений порядка), в статье используется ad-hoc форма этой конструкции. Также требуется, чтобы домен абстрактных значений имел структуры полугруппы (т.к. моделируются числовые значения) и ограниченной (полу)решетки.
Для задания семантики анализируемого языка используется исчисление предусловий, состоящее из (1) бескванторных логических формул (предусловий/assertions) и аннотированных ими программ, (2) функции вычисления наислабейшего предусловия (формулы, которой должны удовлетворять переменные в начале исполнения) по аннотированной программе и (3) функции для генерации условий проверки (набор импликаций, которые, будучи валидными, гарантируют что любое исполнение программы, стартующее из удовлетворяющего предусловию состояния, будет удовлетворять всем последующим формулам). Для while-циклов также добавляются явные инварианты. Нужно заметить, что в самой статье полноценная аксиоматическая семантика c пред- и постусловиями не вводится, но это проделано в предыдущей статье автора, откуда я взял соответствующий кусок с доказательствами корректности аксиоматической семантики относительно операционной и корректности генератора условий. Ключевым же свойством генератора условий для корректности абстрактного интерпретатора является монотонность, т.е. валидность условий, построенных из некой формулы влечет валидность условий, построенных из её ослабления. Задача абстрактного интерпретатора - по исходной программе и абстрактному начальному состоянию одновременно вывести аннотированную программу и абстрактное конечное состояние.
В статье демонстрируется построение двух вариантов абстрактного интерпретатора, причем во втором, более продвинутом, сделана попытка обнаруживать незавершимость и мёртвые ветки кода. В качестве базовой инфраструктуры для обоих вариантов вводится таблица поиска (lookup table) для абстрактных состояний переменных (пары из имени переменной и абстрактного значения; отсутствующие переменные имеют по умолчанию значение верхнего элемента полурешетки) и набор функций для отображения этих состояний в логические формулы, каковые функции должны иметь ряд свойств (включающие, например, требования параметричности отображения и перевода верхнего элемента в тривиальную истину). Для верификации интерпретатора также нужна функция построения предиката внутри метатеории (теории типов) по его сигнатуре.
+ порт на Агду
В статье обсуждается кодирование внутри теории типов подхода к статическому анализу программ, известного как абстрактная интерпретация (АИ). Для анализа взят простой императивный язык с целочисленными значениями (можно ограничить до натуральных) со сложением и булевым сравнением, мутабельными переменными, последовательной композицией и while-циклами. Корректность полученного абстрактного интерпретатора доказана относительно аксиоматической (Хоаровой) семантики языка, а гарантия завершимости получается по построению.
Идея абстрактной интерпретации заключается в вычислении приближенных значений для некоторых аспектов поведения программы - обычно анализ делается по графу потока управления программы, но в статье анализируется напрямую синтаксическое дерево. Такую аппроксимацию, как правило, можно получить значительно быстрее, нежели исполнять саму программу, при этом на её основании можно проводить компиляторные оптимизации и делать выводы о корректности. Стандартным примером приближенного анализа является огрубление точных значений числовых переменных до бита четности или интервала значений. Классически при этом выводится аппроксимация "сверху" (overapproximation), т.е. мы хотим гарантировать отсутствие ложноотрицательных результатов за счет возможных ложноположительных (стандартный компромисс статического анализа). Формально отношения между точными (конкретными) и приближенными (абстрактными) множествами значений описываются в теории АИ через соответствия Галуа (пара функции абстракции α и функции конкретизации γ, необходимы для транспорта отношений порядка), в статье используется ad-hoc форма этой конструкции. Также требуется, чтобы домен абстрактных значений имел структуры полугруппы (т.к. моделируются числовые значения) и ограниченной (полу)решетки.
Для задания семантики анализируемого языка используется исчисление предусловий, состоящее из (1) бескванторных логических формул (предусловий/assertions) и аннотированных ими программ, (2) функции вычисления наислабейшего предусловия (формулы, которой должны удовлетворять переменные в начале исполнения) по аннотированной программе и (3) функции для генерации условий проверки (набор импликаций, которые, будучи валидными, гарантируют что любое исполнение программы, стартующее из удовлетворяющего предусловию состояния, будет удовлетворять всем последующим формулам). Для while-циклов также добавляются явные инварианты. Нужно заметить, что в самой статье полноценная аксиоматическая семантика c пред- и постусловиями не вводится, но это проделано в предыдущей статье автора, откуда я взял соответствующий кусок с доказательствами корректности аксиоматической семантики относительно операционной и корректности генератора условий. Ключевым же свойством генератора условий для корректности абстрактного интерпретатора является монотонность, т.е. валидность условий, построенных из некой формулы влечет валидность условий, построенных из её ослабления. Задача абстрактного интерпретатора - по исходной программе и абстрактному начальному состоянию одновременно вывести аннотированную программу и абстрактное конечное состояние.
В статье демонстрируется построение двух вариантов абстрактного интерпретатора, причем во втором, более продвинутом, сделана попытка обнаруживать незавершимость и мёртвые ветки кода. В качестве базовой инфраструктуры для обоих вариантов вводится таблица поиска (lookup table) для абстрактных состояний переменных (пары из имени переменной и абстрактного значения; отсутствующие переменные имеют по умолчанию значение верхнего элемента полурешетки) и набор функций для отображения этих состояний в логические формулы, каковые функции должны иметь ряд свойств (включающие, например, требования параметричности отображения и перевода верхнего элемента в тривиальную истину). Для верификации интерпретатора также нужна функция построения предиката внутри метатеории (теории типов) по его сигнатуре.
Первый интерпретатор просто использует эти функции напрямую для рекурсивного аннотирования программы, не пытаясь вывести инварианты циклов (подставляя вместо них тривиально истинные формулы). Его корректность сводится к трем свойствам: (1) наислабейшее предусловие, полученное из вычисленного конечного состояния, действительно слабее предусловия, полученного из начального состояния, (2) все условия проверки, полученные из вычисленной аннотированной программы и конечного состояния, являются валидными и (3) вычисленная аннотированная программа идентична исходной программе после стирания аннотаций. Пример работы этого интерпретатора проиллюстрирован на домене битов четности со свободно добавленным верхним элементом (кодирующим отсутствие информации).
Второй интерпретатор более серьезно подходит к работе с циклами, используя информацию о том, что тест цикла всегда истинен внутри его тела и ложен на выходе. Незавершимость кодируется обертыванием конечного состояния в опциональный тип в выдаче интерпретатора. К параметрам добавляются две новые функции, которые вычисляют уточнения абстрактного состояния в зависимости от успешно и неуспешно пройденного теста цикла соответственно; именно эти функции берут на себя основную сложность задачи, в частности, они пытаются выводить информацию о незавершимости, и эта же информация позволяет пометить мертвый код тривиально ложными аннотациями. Схема процесса вывода инварианта цикла (в общем случае эта задача неразрешима!) выглядит так: (1) несколько абстрактных прогонов тела цикла (их количество контролируется эвристикой) с нарастающим расширением множества значений переменных - если процесс стабилизировался, инвариант найден; (2) если инвариант не найден, запускаем процесс 1 еще раз с переаппроксимацией для значений некоторых переменных - это позволяет ускорить процесс схождения (количество этих повторов также контролируется отдельной эвристикой); (3) если инвариант всё еще не найден, выбрать гарантированный инвариант (первый интерпретатор сразу же делает это, используя тривиальную истину); (4) сужение переаппроксимированных инвариантов повторным запуском интерпретатора (наличие этого шага приводит к определению интерпретатора через вложенную рекурсию).
Реализация этих шагов требует введения ряда вспомогательных функций-параметров, например, для сравнения количества информации в двух абстрактных значениях. Для доказательства корректности второго интерпретатора (состоящего из тех же трёх частей, что и в первом случае) также требуются 14 новых условий, описывающих все эти новые функции и их взаимодействие. Обе реализации интерпретаторов и их доказательства упакованы в модули, параметризующие их по абстрактному домену. Первый интерпретатор уже был ранее инстанцирован доменом чётности, а для второго описано кодирование домена числовых интервалов с потенциально бесконечными границами, где роль верхнего элемента играет интервал (-∞,+∞), а переаппроксимация заключается в замене одной из границ на -/+∞.
В заключение автор отмечает, что статью не следует рассматривать как полноценное введение в теорию АИ, а реализованные интерпретаторы являются моделями, т.к. оставляют желать лучшего в плане производительности - например, при вычислении аннотаций повторяется работа, уже проделанная ранее при поиске инварианта цикла. Кроме того, статический анализ может быть эффективнее, если рассматривать не отдельные переменные, а отношения между несколькими переменными.
#automatedreasoning
Второй интерпретатор более серьезно подходит к работе с циклами, используя информацию о том, что тест цикла всегда истинен внутри его тела и ложен на выходе. Незавершимость кодируется обертыванием конечного состояния в опциональный тип в выдаче интерпретатора. К параметрам добавляются две новые функции, которые вычисляют уточнения абстрактного состояния в зависимости от успешно и неуспешно пройденного теста цикла соответственно; именно эти функции берут на себя основную сложность задачи, в частности, они пытаются выводить информацию о незавершимости, и эта же информация позволяет пометить мертвый код тривиально ложными аннотациями. Схема процесса вывода инварианта цикла (в общем случае эта задача неразрешима!) выглядит так: (1) несколько абстрактных прогонов тела цикла (их количество контролируется эвристикой) с нарастающим расширением множества значений переменных - если процесс стабилизировался, инвариант найден; (2) если инвариант не найден, запускаем процесс 1 еще раз с переаппроксимацией для значений некоторых переменных - это позволяет ускорить процесс схождения (количество этих повторов также контролируется отдельной эвристикой); (3) если инвариант всё еще не найден, выбрать гарантированный инвариант (первый интерпретатор сразу же делает это, используя тривиальную истину); (4) сужение переаппроксимированных инвариантов повторным запуском интерпретатора (наличие этого шага приводит к определению интерпретатора через вложенную рекурсию).
Реализация этих шагов требует введения ряда вспомогательных функций-параметров, например, для сравнения количества информации в двух абстрактных значениях. Для доказательства корректности второго интерпретатора (состоящего из тех же трёх частей, что и в первом случае) также требуются 14 новых условий, описывающих все эти новые функции и их взаимодействие. Обе реализации интерпретаторов и их доказательства упакованы в модули, параметризующие их по абстрактному домену. Первый интерпретатор уже был ранее инстанцирован доменом чётности, а для второго описано кодирование домена числовых интервалов с потенциально бесконечными границами, где роль верхнего элемента играет интервал (-∞,+∞), а переаппроксимация заключается в замене одной из границ на -/+∞.
В заключение автор отмечает, что статью не следует рассматривать как полноценное введение в теорию АИ, а реализованные интерпретаторы являются моделями, т.к. оставляют желать лучшего в плане производительности - например, при вычислении аннотаций повторяется работа, уже проделанная ранее при поиске инварианта цикла. Кроме того, статический анализ может быть эффективнее, если рассматривать не отдельные переменные, а отношения между несколькими переменными.
#automatedreasoning
Возможно, кому-то будет интересно поучаствовать в данном проекте. Ребята занимаются поиском и оптимизацией путей на графах Кэли - это такая комбинаторная кодировка группы, где элементы группы становятся вершинами, а ребра связывают те элементы, что получаются друг из друга умножениями на один из генераторов группы. Это позволяет изучать структуру групп с помощью методов теории графов; в частности, искать подходы к решению word problem для разных групп (т.е. сравнению структур по модулю правил перезаписи, разновидностями этого класса задач являются нормализация и унификация в ТЯП). Также любопытно, что графы Кэли являются примером Para-конструкции из прикладного теорката.
Wikipedia
Cayley graph
In mathematics, a Cayley graph, also known as a Cayley color graph, Cayley diagram, group diagram, or color group, is a graph that encodes the abstract structure of a group. Its definition is suggested by Cayley's theorem (named after Arthur Cayley), and…
Forwarded from Alexander C
This media is not supported in your browser
VIEW IN TELEGRAM
🚀 Уважаемые коллеги, тех, кому интересна математика и машинное обучение, приглашаем Вас принять в неформальном проекте.
Минимальное требование - Вы знакомы с Питоном, и у Вас есть несколько часов свободного времени в неделю. (Альтернативно - можно не знать Питон, но хорошо знать теорию групп (в идеале GAP,SAGE).) Задача проекта - применить машинное обучение к теории групп. Целью проекта является написание статьи в хорошем журнале, участники - соавторы. Другим бонусом будет являться - приобретение навыков по современным методам нейронных сетей, Reinforcement Learning и т.д.
Если Вам интересно участие - напишите @alexander_v_c (Александр Червов, к.ф.-м.н. мехмат МГУ, 25 лет math&DS, Kaggle, Scholar, Linkedin).
Чат для обсуждений: тут .
Вводный доклад тут.
Пояснения по RL части тут.
Краткая суть задачи может быть описана несколькими способами - нахождение пути на графе от вершины А до вершины Б, но размер графа 10^20-10^50 - обычные методы не применимы. Решение пазла типа Кубика Рубика. Задача близка к прошедшему конкурсу Каггл Санта 2023. Математически - разложение элемента группы по образующим. Математические пакеты, которые частично могут решать эту задачу - GAP,SAGE.
Достигнутые результаты - уже сейчас мы можем за минуты делать то, что авторы работы DeepCube делали за 40 часов на многих GPU.
Минимальное требование - Вы знакомы с Питоном, и у Вас есть несколько часов свободного времени в неделю. (Альтернативно - можно не знать Питон, но хорошо знать теорию групп (в идеале GAP,SAGE).) Задача проекта - применить машинное обучение к теории групп. Целью проекта является написание статьи в хорошем журнале, участники - соавторы. Другим бонусом будет являться - приобретение навыков по современным методам нейронных сетей, Reinforcement Learning и т.д.
Если Вам интересно участие - напишите @alexander_v_c (Александр Червов, к.ф.-м.н. мехмат МГУ, 25 лет math&DS, Kaggle, Scholar, Linkedin).
Чат для обсуждений: тут .
Вводный доклад тут.
Пояснения по RL части тут.
Краткая суть задачи может быть описана несколькими способами - нахождение пути на графе от вершины А до вершины Б, но размер графа 10^20-10^50 - обычные методы не применимы. Решение пазла типа Кубика Рубика. Задача близка к прошедшему конкурсу Каггл Санта 2023. Математически - разложение элемента группы по образующим. Математические пакеты, которые частично могут решать эту задачу - GAP,SAGE.
Достигнутые результаты - уже сейчас мы можем за минуты делать то, что авторы работы DeepCube делали за 40 часов на многих GPU.
Пару недель назад выпустил в открытое плавание (переведя под крыло Coq community) проект, над которым эпизодически работаю c 2021 года: FDSA in SSReflect.
Идея банальна - переписать код из открытой книги Nipkow et al, "Functional Data Structures and Algorithms" (в начале работы книга называлась "Functional Algorithms, Verified") с Isabelle/HOL на полностью типотеоретический язык. Для портирования я выбрал Coq + фреймворк Mathcomp/SSReflect + плагин Equations для компактной записи паттерн-матчинга и доказательств завершимости.
В Isabelle/HOL для ризонинга используется классическая логика, но для работы с корректностью вычислительных структур данных разница с конструктивной логикой невелика, поскольку почти всегда предполагается, что элементы этих структур как минимум дискретны (то есть снабжены разрешимой проверкой на равенство, что соответствует "локальному" исключенному третьему). Основное отличие, пожалуй, только в одном месте - вместо использования равенств на мультимножествах из Isabelle я использую списки и отношение перестановки (
Основная тема книги - формальные доказательства корректности классических чисто функциональных алгоритмов, а для многих алгоритмов также приведены доказательства их рантайм-сложности. Стоит, однако, отметить, что последний момент реализован несколько ad-hoc - вручную строится скелет алгоритма, возвращающий приближенное число итераций, и ризонинг ведется на этом скелете, без проверки его соответствия его изначальному алгоритму.
Книга устроена следующим образом:
0. Вводная глава с основными понятиями.
1. Раздел, посвященный алгоритмам сортировки и выбора: mergesort/quicksort/quickselect. На мой взгляд, глава про алгоритм выбора делает ощутимый скачок в сложности, т.к. для quickselect доказательства завершимости (из-за использования вложенной рекурсии) и комплексити (упрощенный вариант теоремы Акра-Баззи) на порядок (а то и два) замысловатее таковых для сортировок.
2. Крупный раздел об алгоритмах на деревьях - тут и популярные красно-черные/AVL-деревья, и менее известные деревья Брауна, и специализированные квадродеревья.
3. Идеологическое продолжение предыдущего раздела о нескольких способах реализации очередей с приоритетом.
4. Раздел о продвинутых алгоритмических методах, включающий динамическое программирование, амортизационный анализ и косые деревья. До этого раздела я пока еще не добрался, остановился на адаптации поисковых деревьев из предыдущих глав в поисковую таблицу для кэширования результатов в динамическом программировании.
5. Раздел "разное": на текущий момент там есть строковый алгоритм Кнута-Морриса-Пратта, алгоритм сжатия Хаффмана и поисковый алгоритм αβ-отсечения. Тут я пока реализовал только алгоритм Хаффмана.
В целом, книга довольно неплохо объясняет классические иммутабельные алгоритмы (хотя местами слишком сжато, особенно в 4м разделе), этакий пруф-инженерный вариант известной работы Okasaki, [1998] "Purely functional data structures". В книге много упражнений, большинство из которых я прорешал, но в публичном репозитории заменил соответствующие места скелетами определений и теорем, чтобы не спойлить решения для потенциальных студентов.
#datastructures
Идея банальна - переписать код из открытой книги Nipkow et al, "Functional Data Structures and Algorithms" (в начале работы книга называлась "Functional Algorithms, Verified") с Isabelle/HOL на полностью типотеоретический язык. Для портирования я выбрал Coq + фреймворк Mathcomp/SSReflect + плагин Equations для компактной записи паттерн-матчинга и доказательств завершимости.
В Isabelle/HOL для ризонинга используется классическая логика, но для работы с корректностью вычислительных структур данных разница с конструктивной логикой невелика, поскольку почти всегда предполагается, что элементы этих структур как минимум дискретны (то есть снабжены разрешимой проверкой на равенство, что соответствует "локальному" исключенному третьему). Основное отличие, пожалуй, только в одном месте - вместо использования равенств на мультимножествах из Isabelle я использую списки и отношение перестановки (
perm_eq) на них. Кроме того, в Isabellе функции не обязаны быть тотальными, что влечет за собой необходимость слегка менять определения - дополняя их для всей области определения и давая доказательства завершимости во всех случаях (а не только в избранных, как в книге).Основная тема книги - формальные доказательства корректности классических чисто функциональных алгоритмов, а для многих алгоритмов также приведены доказательства их рантайм-сложности. Стоит, однако, отметить, что последний момент реализован несколько ad-hoc - вручную строится скелет алгоритма, возвращающий приближенное число итераций, и ризонинг ведется на этом скелете, без проверки его соответствия его изначальному алгоритму.
Книга устроена следующим образом:
0. Вводная глава с основными понятиями.
1. Раздел, посвященный алгоритмам сортировки и выбора: mergesort/quicksort/quickselect. На мой взгляд, глава про алгоритм выбора делает ощутимый скачок в сложности, т.к. для quickselect доказательства завершимости (из-за использования вложенной рекурсии) и комплексити (упрощенный вариант теоремы Акра-Баззи) на порядок (а то и два) замысловатее таковых для сортировок.
2. Крупный раздел об алгоритмах на деревьях - тут и популярные красно-черные/AVL-деревья, и менее известные деревья Брауна, и специализированные квадродеревья.
3. Идеологическое продолжение предыдущего раздела о нескольких способах реализации очередей с приоритетом.
4. Раздел о продвинутых алгоритмических методах, включающий динамическое программирование, амортизационный анализ и косые деревья. До этого раздела я пока еще не добрался, остановился на адаптации поисковых деревьев из предыдущих глав в поисковую таблицу для кэширования результатов в динамическом программировании.
5. Раздел "разное": на текущий момент там есть строковый алгоритм Кнута-Морриса-Пратта, алгоритм сжатия Хаффмана и поисковый алгоритм αβ-отсечения. Тут я пока реализовал только алгоритм Хаффмана.
В целом, книга довольно неплохо объясняет классические иммутабельные алгоритмы (хотя местами слишком сжато, особенно в 4м разделе), этакий пруф-инженерный вариант известной работы Okasaki, [1998] "Purely functional data structures". В книге много упражнений, большинство из которых я прорешал, но в публичном репозитории заменил соответствующие места скелетами определений и теорем, чтобы не спойлить решения для потенциальных студентов.
#datastructures
GitHub
GitHub - rocq-community/fav-ssr: Functional Data Structures and Algorithms in SSReflect [maintainer=@clayrat]
Functional Data Structures and Algorithms in SSReflect [maintainer=@clayrat] - rocq-community/fav-ssr
https://cs.nyu.edu/media/publications/pavlinovic_zvonimir.pdf Pavlinovic, [2019] "Leveraging Program Analysis for Type Inference"
Вчера ходил на доклад от Бьёрна Страуструпа о современном C++. Доклад был посвящен четырём основным темам: управлению ресурсами, модулям, дженерикам и "профилям" (подмножествам языка, за удержанием в рамках каковых следит компилятор). Страуструп призывал одновременно не зацикливаться на использовании одних лишь новых фич и не застревать в прошлом, также проповедовал старый добрый KISS. В целом видение Страуструпа начинает все больше напоминать нечто ML-образное.
Covalue
Photo
Ссылки с последнего слайда:
* B. Stroustrup: 21st century C++ Blog@CACM January 2025
* C++ Core Guidelines
* Profiles
** B. Stroustrup: Safety Profiles: Type-and-resource Safe programming in ISO Standard C++
** B. Stroustrup: Profiles syntax
** B. Stroustrup: Profile invalidation eliminating dangling pointers
** Herb Sutter: Lifetime safety: Preventing common dangling
* Khalil Estell: C++ Exceptions for Smaller Firmware. CppCon 2024
* Daniela Engert: Contemporary C++ in Action. CppCon 2022 a client server application for displaying video frames with timing constraints
* B. Stroustrup: A Tour of C++ (3rd Edition). Addison-Wesley. 2022.
* B. Stroustrup: Programming: Principles and Practice using C++.
* B. Stroustrup's HOPL papers
** A History of C++: 1979-1991. March 1993
** Evolving a language in and for the real world: C++ 1991-2006. June 2007
** Thriving in a Crowded and Changing World: C++ 2006-2020. June 2020
* B. Stroustrup: 21st century C++ Blog@CACM January 2025
* C++ Core Guidelines
* Profiles
** B. Stroustrup: Safety Profiles: Type-and-resource Safe programming in ISO Standard C++
** B. Stroustrup: Profiles syntax
** B. Stroustrup: Profile invalidation eliminating dangling pointers
** Herb Sutter: Lifetime safety: Preventing common dangling
* Khalil Estell: C++ Exceptions for Smaller Firmware. CppCon 2024
* Daniela Engert: Contemporary C++ in Action. CppCon 2022 a client server application for displaying video frames with timing constraints
* B. Stroustrup: A Tour of C++ (3rd Edition). Addison-Wesley. 2022.
* B. Stroustrup: Programming: Principles and Practice using C++.
* B. Stroustrup's HOPL papers
** A History of C++: 1979-1991. March 1993
** Evolving a language in and for the real world: C++ 1991-2006. June 2007
** Thriving in a Crowded and Changing World: C++ 2006-2020. June 2020
isocpp.github.io
C++ Core Guidelines
The C++ Core Guidelines are a set of tried-and-true guidelines, rules, and best practices about coding in C++
Нашел качественную диссертацию с обзором состояния дел в model checking на 2010й год:
Weißenbacher, [2010] "Program Analysis with Interpolants"
Вкратце идею проверки моделей можно описать так: мы хотим автоматически верифицировать программы, для этого мы аппроксимируем их моделями, то есть автоматами или системами переходов с конечным набором состояний, задаём спецификацию (обычно в какой-то разновидности пропозициональной темпоральной логики) и с помощью поисковых алгоритмов и эвристик исчерпывающе перебираем состояния модели, проверяя что для них всех спецификация верна.
Концептуально этот подход описывается теорией моделей (одним из двух основных разделов логики, второй - это теория доказательств, на которой основана теория типов и proof assistants). Интересно, что в моделчекинге примерно раз в декаду сменяется доминирующая парадигма, в целом его таймлайн выглядит примерно так:
* 1980е - зарождение самой идеи MC из работ Эдмунда Кларка по вычислению неподвижных точек для систем доказательств в предикат-трансформерах, использование BDD для компактификации состояний
* 1990е - дальнейшее ужатие состояний через partial order reduction, появление предикат-абстракции и CEGAR - методов автоматического конструирования моделей из набора assertions о программе
* 2000е - SAT/SMT-революция и уход от BDD, быстрая аппроксимация через интерполяцию Крейга
* 2010е - Аарон Брэдли изобретает семейство алгоритмов PDR (property directed reachability), где процесс построения инварианта чередуется и взаимодействует с построением контрпримера, взаимно усекая соответствующие пространства поиска
* 2020е - ажиотаж вокруг техник из машинного обучения
Первые три декады и основные их идеи расписаны в первых двух с половиной главах диссертации (вторая половина третьей и четвертая главы более технические).
#automatedreasoning
Weißenbacher, [2010] "Program Analysis with Interpolants"
Вкратце идею проверки моделей можно описать так: мы хотим автоматически верифицировать программы, для этого мы аппроксимируем их моделями, то есть автоматами или системами переходов с конечным набором состояний, задаём спецификацию (обычно в какой-то разновидности пропозициональной темпоральной логики) и с помощью поисковых алгоритмов и эвристик исчерпывающе перебираем состояния модели, проверяя что для них всех спецификация верна.
Концептуально этот подход описывается теорией моделей (одним из двух основных разделов логики, второй - это теория доказательств, на которой основана теория типов и proof assistants). Интересно, что в моделчекинге примерно раз в декаду сменяется доминирующая парадигма, в целом его таймлайн выглядит примерно так:
* 1980е - зарождение самой идеи MC из работ Эдмунда Кларка по вычислению неподвижных точек для систем доказательств в предикат-трансформерах, использование BDD для компактификации состояний
* 1990е - дальнейшее ужатие состояний через partial order reduction, появление предикат-абстракции и CEGAR - методов автоматического конструирования моделей из набора assertions о программе
* 2000е - SAT/SMT-революция и уход от BDD, быстрая аппроксимация через интерполяцию Крейга
* 2010е - Аарон Брэдли изобретает семейство алгоритмов PDR (property directed reachability), где процесс построения инварианта чередуется и взаимодействует с построением контрпримера, взаимно усекая соответствующие пространства поиска
* 2020е - ажиотаж вокруг техник из машинного обучения
Первые три декады и основные их идеи расписаны в первых двух с половиной главах диссертации (вторая половина третьей и четвертая главы более технические).
#automatedreasoning