
group-telegram.com/fckndh/144
Last Update:
5 коллекций данных для цифрового гуманитария
Интернет набит данными, но очень немногие датасеты сделаны гуманитариями и для гуманитариев. Собрал пять чисто гуманитарных источников данных, которые хорошо использовать в курсе анализа данных или программирования на DH-программах.
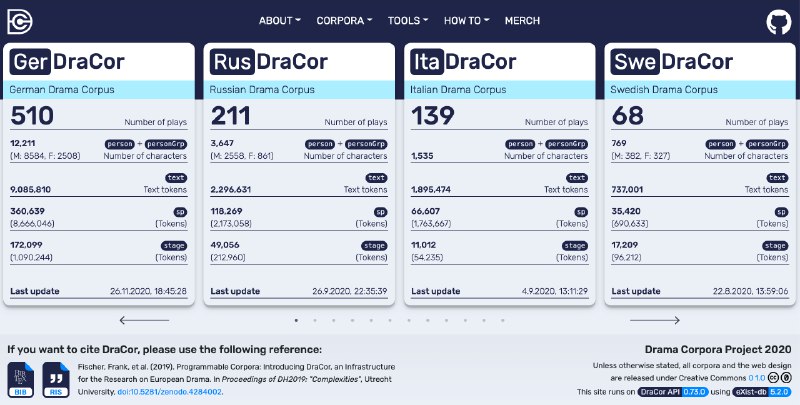
🎭 1. DraCor — корпуса и датасеты вокруг драматических текстов (с уклоном в network analysis, но не только). Один из очень немногих проектов, сумевших на базе “гуманитарного” стандарта TEI построить классную экосистему гуманитарных данных. Самые приятные данные дракора — это метаданные для каждого корпуса, которые вы можете скачать прямо на страничке корпуса, например, вот табличка для русского корпуса: https://dracor.org/api/v1/corpora/rus/metadata/csv Тут и классические метаданые вроде дат написания и публикации, и сетевые вроде плотности социальной сети в пьесе, и например соотношение мужской и женской речи…
Еще для каждой отдельной пьесы можно скачать сетевые данные (в gexf/csv/gml), речь персонажей, сценические ремарки… Ну и полную разметку в TEI, из которой все эти данные произрастают.
✒️ 2. Репозиторий открытых данных по русской литературе и фольклору — проект Цифровой лабы Пушкинского дома (ИРЛИ РАН), где цифровые филологи и не только публикуют датасеты и (иногда) код к своим исследованиям. Своего рода гуманитарный papers with code. Вот, например, данные и код к статье Кирилла Маслинского о том, какие животные чаще встречаются в каких жанрах детской литературе.
А еще там публикует новые датасеты сам ПушДом. Многие из них называются очень романтично. Скажем, Забытые романы русских писателей из фондов Пушкинского Дома (1857–1917)… Датасет с таким названием нужно обрабатывать под звуки романса “Отцвели уж давно хризантемы в саду”🍂
📚 3. European Literary Text Collection (ELTeC) — корпуса европейских романов, собранные с прицелом на репрезентативность и сопоставимость друг с другом. Целью было найти для каждой европейской литературы по 100 романов в диапазоне 1840-1920, чтобы они покрывали период более-менее равномерно, чтобы были представлены не только писатели-мужчины, чтобы бли длиной не менее 10000 слов и т.д. Не для всех корпусов это удалось, а русский корпус там совсем странный, но тем не менее — одна из немногих попыток сделать датасет, пригодный для “компаративистики” by design.
🏛 4. Госкаталог Музейного фонда РФ — свалка датасет по всему, что оцифровано во всех музеях России. Не так часто в нашей области можно найти наборы данных, где записей не тысячи, но миллионы. Качество очень разное, репрезентативность тоже под вопросом, но жемчужин в этом океане данных тоже море. Одну я здесь уже описывал.
🗺 5. Геоданные DHCLOUD. Тут лежат литературные карты в geojson, сделанные студентами гуманитарного факультета Вышки под руководством Бориса Орехова. Картографированы самые разные тексты: от маршрута Афанасия Никитина и до Приключений Капитана Врунгеля ⛵🐳
BY Цифровой филолог (Даня Скоринкин)
Share with your friend now:
group-telegram.com/fckndh/144