
{kind=link}
📄 Scaling Laws for Native Multimodal Models
📌 Исследователи из Sorbonne и Apple проанализировали 457 мультимодальных моделей, чтобы понять, как масштабируются нативные мультимодальные архитектуры (NMM) — обученные с нуля, а не через “приклейку” vision-энкодеров к LLM.
🔍 Главное:
▪ Late-fusion (классика с vision encoder + LLM) ≠ обязательно лучше.
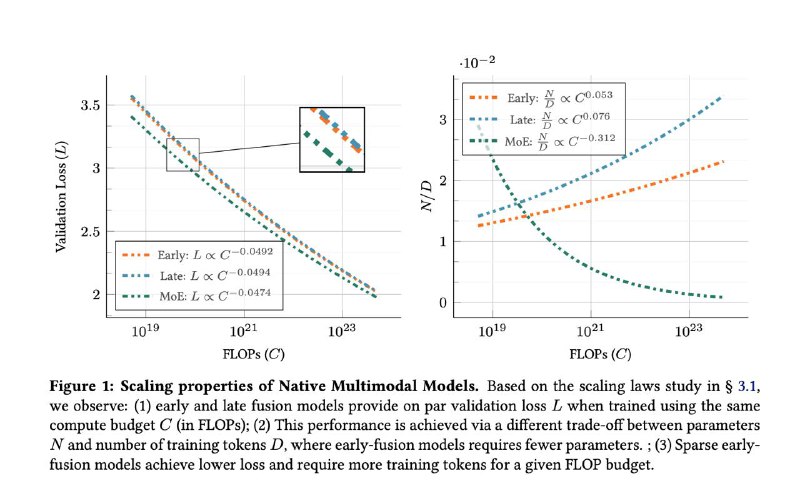
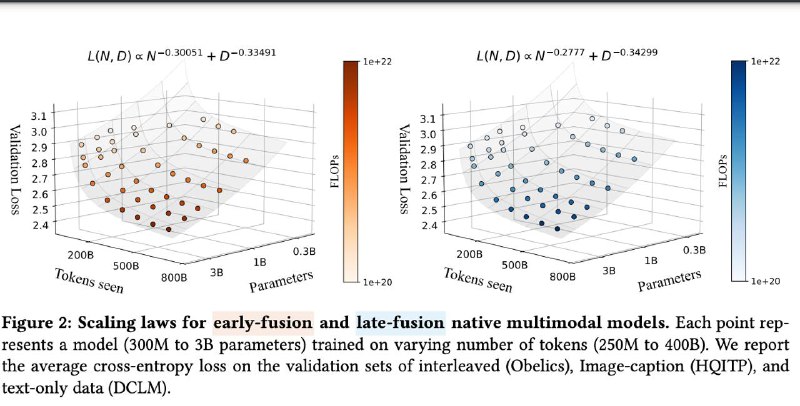
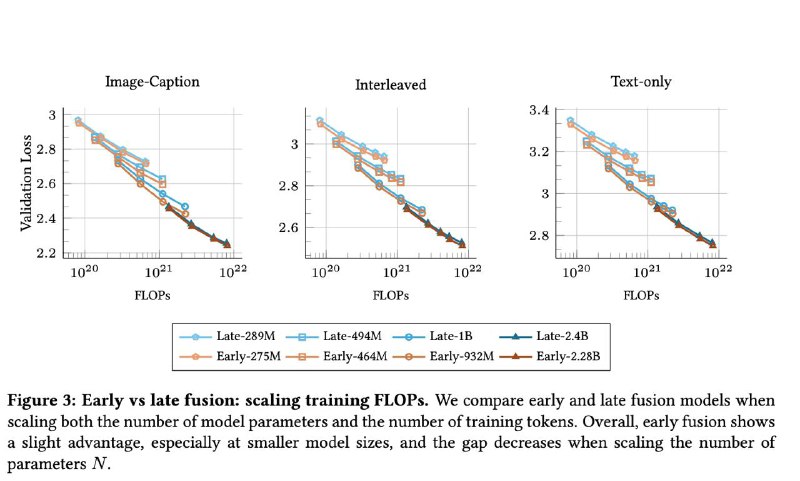
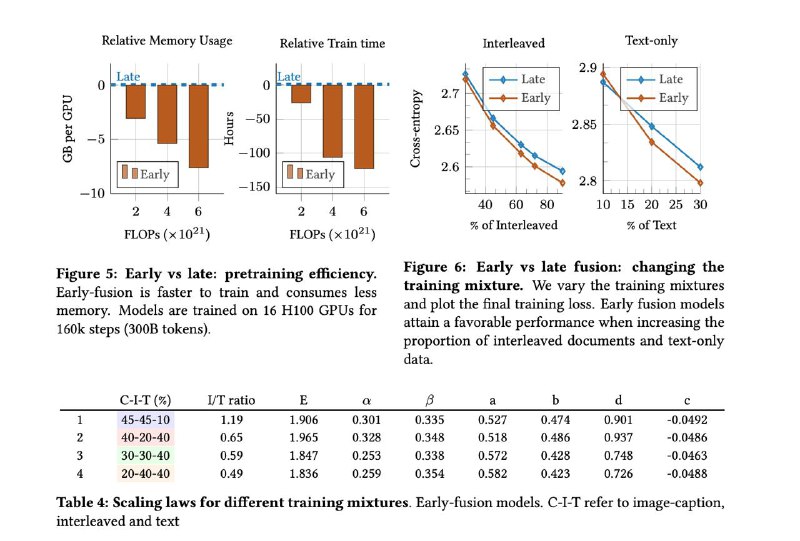
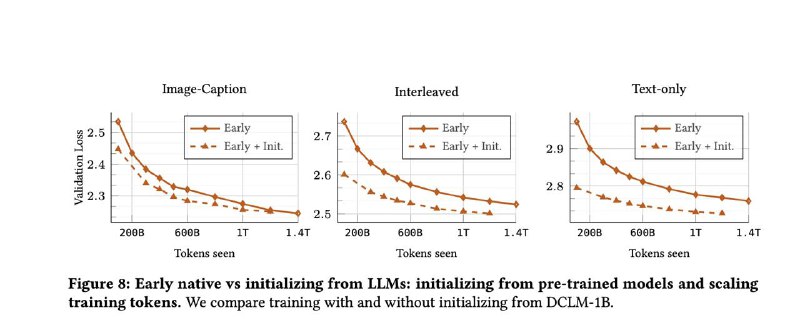
▪ Early-fusion модели, в которых всё учится совместно с нуля — обгоняют по качеству при меньшем количестве параметров, обучаются быстрее и проще в продакшене.
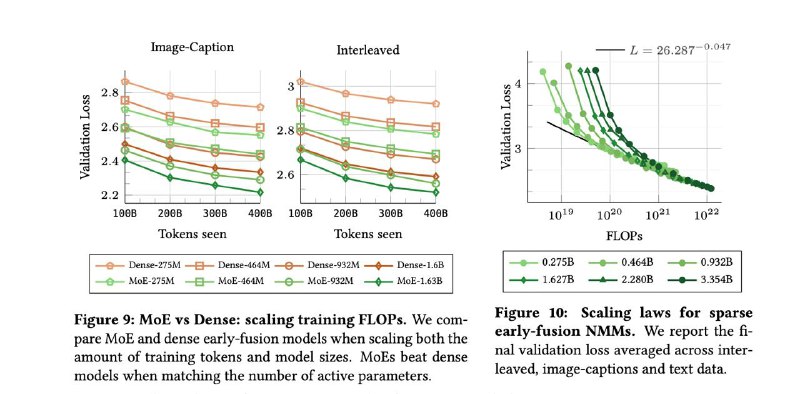
▪ Добавление Mixture of Experts (MoE) даёт прирост — модели учат модальность-специфичные веса, сохраняя ту же цену инференса.
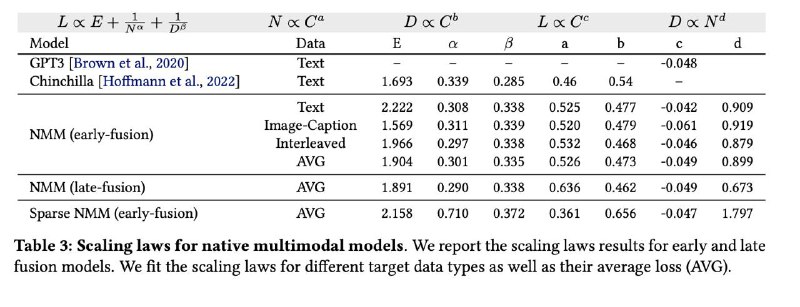
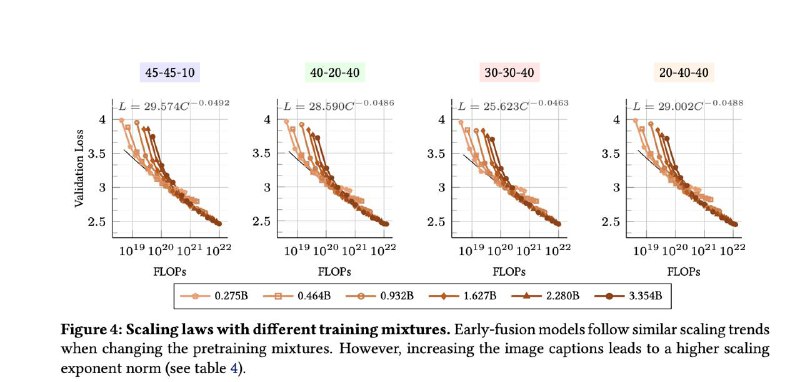
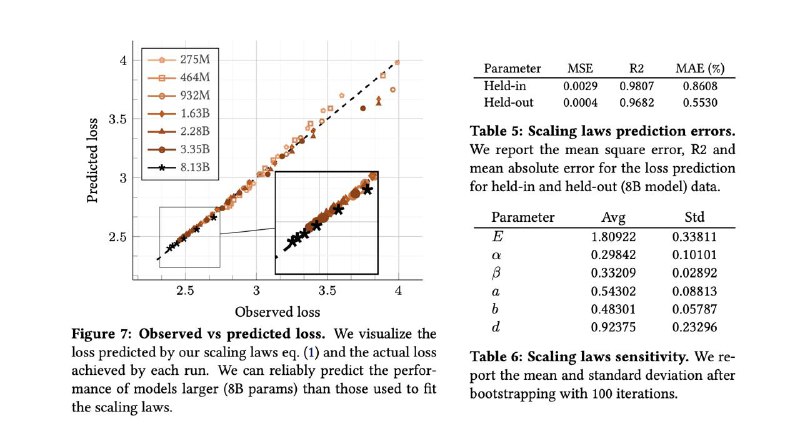
▪ Scaling laws (законы масштабирования) у NMM — почти те же, что у LLM. Можно планировать бюджеты и рост моделей аналогично.
⚠️ Ограничения:
— Пока неясно, как точно это поведение переносится на downstream-задачи.
— Нужно больше экспериментов с разными пропорциями мультимодальных данных.
— Для early-fusion на высоких разрешениях нужны новые подходы к работе с токенами (контекст, пуллинг и т.д.).
📎 Вывод:
Early-fusion — не просто рабочий вариант, а оптимальный выбор для мультимодальных моделей при ограниченных ресурсах. Отказ от “склеек” делает обучение проще, быстрее и дешевле.
Читать
#ai #multimodal #scalinglaws #moe #llm #mlresearch #arxiv
📌 Исследователи из Sorbonne и Apple проанализировали 457 мультимодальных моделей, чтобы понять, как масштабируются нативные мультимодальные архитектуры (NMM) — обученные с нуля, а не через “приклейку” vision-энкодеров к LLM.
🔍 Главное:
▪ Late-fusion (классика с vision encoder + LLM) ≠ обязательно лучше.
▪ Early-fusion модели, в которых всё учится совместно с нуля — обгоняют по качеству при меньшем количестве параметров, обучаются быстрее и проще в продакшене.
▪ Добавление Mixture of Experts (MoE) даёт прирост — модели учат модальность-специфичные веса, сохраняя ту же цену инференса.
▪ Scaling laws (законы масштабирования) у NMM — почти те же, что у LLM. Можно планировать бюджеты и рост моделей аналогично.
⚠️ Ограничения:
— Пока неясно, как точно это поведение переносится на downstream-задачи.
— Нужно больше экспериментов с разными пропорциями мультимодальных данных.
— Для early-fusion на высоких разрешениях нужны новые подходы к работе с токенами (контекст, пуллинг и т.д.).
📎 Вывод:
Early-fusion — не просто рабочий вариант, а оптимальный выбор для мультимодальных моделей при ограниченных ресурсах. Отказ от “склеек” делает обучение проще, быстрее и дешевле.
Читать
#ai #multimodal #scalinglaws #moe #llm #mlresearch #arxiv
group-telegram.com/machinelearning_interview/1720
Create:
Last Update:
Last Update:
📄 Scaling Laws for Native Multimodal Models
📌 Исследователи из Sorbonne и Apple проанализировали 457 мультимодальных моделей, чтобы понять, как масштабируются нативные мультимодальные архитектуры (NMM) — обученные с нуля, а не через “приклейку” vision-энкодеров к LLM.
🔍 Главное:
▪ Late-fusion (классика с vision encoder + LLM) ≠ обязательно лучше.
▪ Early-fusion модели, в которых всё учится совместно с нуля — обгоняют по качеству при меньшем количестве параметров, обучаются быстрее и проще в продакшене.
▪ Добавление Mixture of Experts (MoE) даёт прирост — модели учат модальность-специфичные веса, сохраняя ту же цену инференса.
▪ Scaling laws (законы масштабирования) у NMM — почти те же, что у LLM. Можно планировать бюджеты и рост моделей аналогично.
⚠️ Ограничения:
— Пока неясно, как точно это поведение переносится на downstream-задачи.
— Нужно больше экспериментов с разными пропорциями мультимодальных данных.
— Для early-fusion на высоких разрешениях нужны новые подходы к работе с токенами (контекст, пуллинг и т.д.).
📎 Вывод:
Early-fusion — не просто рабочий вариант, а оптимальный выбор для мультимодальных моделей при ограниченных ресурсах. Отказ от “склеек” делает обучение проще, быстрее и дешевле.
Читать
#ai #multimodal #scalinglaws #moe #llm #mlresearch #arxiv
📌 Исследователи из Sorbonne и Apple проанализировали 457 мультимодальных моделей, чтобы понять, как масштабируются нативные мультимодальные архитектуры (NMM) — обученные с нуля, а не через “приклейку” vision-энкодеров к LLM.
🔍 Главное:
▪ Late-fusion (классика с vision encoder + LLM) ≠ обязательно лучше.
▪ Early-fusion модели, в которых всё учится совместно с нуля — обгоняют по качеству при меньшем количестве параметров, обучаются быстрее и проще в продакшене.
▪ Добавление Mixture of Experts (MoE) даёт прирост — модели учат модальность-специфичные веса, сохраняя ту же цену инференса.
▪ Scaling laws (законы масштабирования) у NMM — почти те же, что у LLM. Можно планировать бюджеты и рост моделей аналогично.
⚠️ Ограничения:
— Пока неясно, как точно это поведение переносится на downstream-задачи.
— Нужно больше экспериментов с разными пропорциями мультимодальных данных.
— Для early-fusion на высоких разрешениях нужны новые подходы к работе с токенами (контекст, пуллинг и т.д.).
📎 Вывод:
Early-fusion — не просто рабочий вариант, а оптимальный выбор для мультимодальных моделей при ограниченных ресурсах. Отказ от “склеек” делает обучение проще, быстрее и дешевле.
Читать
#ai #multimodal #scalinglaws #moe #llm #mlresearch #arxiv
BY Machine learning Interview

Share with your friend now:
group-telegram.com/machinelearning_interview/1720