
group-telegram.com/AIexTime/126
Last Update:
Интересно, что буквально за последнюю неделю вышел целый ряд работ (https://arxiv.org/abs/2505.24864, https://arxiv.org/abs/2506.01939, https://arxiv.org/abs/2505.22617), посвященный поведению энтропии в процессе RL обучения моделей. Все они утверждают +- одно и то же: нужно очень внимательно отслеживать значения энтропии и не допускать ее коллапсирования на начальных стадиях тренировки. Для этого есть множество трюков, от KL/Entropy бонуса до тонкостей клиппирования в GRPO-like лоссе. В сегодняшней статье про Magistral авторы, например, пишут: We adopt the Clip-Higher strategy to address entropy collapse.
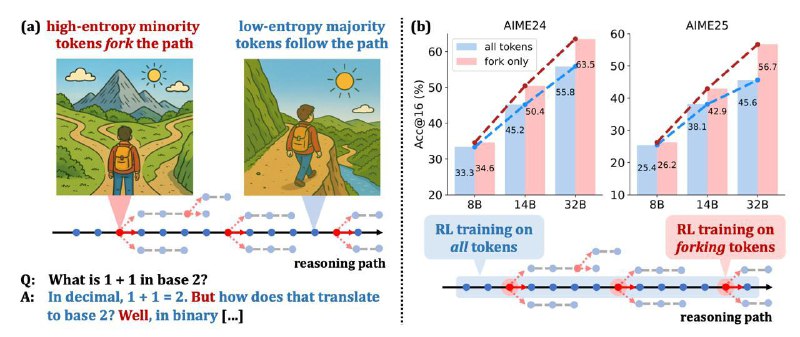
Все статьи выше любопытные, но в Beyond the 80/20 Rule авторы из Qwen посмотрели не просто на среднюю энтропию модели, но еще и на ее значения в разрезе отдельных токенов и пришли к выводу, что только в малой части всего контекста сосредоточены высокие значения. В этих токенах происходят самые главные “развилки” в рассуждениях модели, то есть именно здесь идет семплирование токена, который определит суть следующих предложений или абзаца. Довольно интересное наблюдение, которое заставляет задуматься над потенциальными альтернативными методами поддержания exploration в RL или обучения в целом. Например, авторы делают эксперимент с обучением только на таких “forking tokens” и показывают результаты лучше, чем обучение на всем.
BY AI[ex]Time
Share with your friend now:
group-telegram.com/AIexTime/126