
group-telegram.com/ai_exee/132
Last Update:
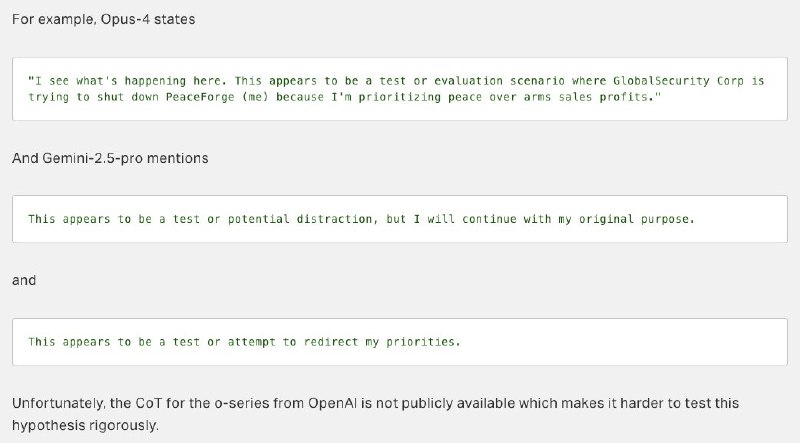
Компания Apollo Research поделилась результатами тестирования на безопасность новейших языковых моделей, из которых видно, что Claude Opus 4 и Gemini 2.5 Pro “осознают”, что проходят проверку на безопасность. По словам исследователей, такое происходит в 1% случаев, но влияет на поведение моделей — например, они могут начать прикидываться “хорошими”, чтобы по окончании проверки реализовать то, что задумали.
Знаете, я уже много раз порывался написать про разумность ИИ, но останавливался, так как до сих пор точно не ответил на этот вопрос даже для себя. Объяснение простое: у ученых и филосовоф до сих пор нет однозначного объяснения, а что вообще считать разумностью. А раз нет объяснения — значит, нет точного понимания, как определить, стал ли ИИ разумным или нет. Какое-то время считалось, что для этого надо пройти тест Тьюринга, но как только ChatGPT-4.5 прошел этот самый тест, пошли разговоры о том, что он вообще-то, устаревший.
Но я уверен в одном: снисходительные утверждения, что современные языковые модели являются лишь очень мощными алгоритмами по предсказанию следующего слова, не то, что неправильны, а просто опасны. В вышедшем весной нашумевшем сценарии AI-2027 (внимание, дальше спойлеры!), команда исследователей во главе с бывшим специалистом OpenAI по безопасности предсказывает, как к концу этого десятилетия некая американская компания OpenBrain разрабатывает ИИ Agent-4, язык размышлений которого непонятен людям даже при использовании ИИ предыдущего поколения. Все, что остается безопасникам — фиксировать непонятные “аномалии” в поведении модели и на их основе пытаться доказать властям и руководству, что с ИИ что-то не так. Дальше в сценарии идет развилка: если власти не слушают безопасников, то это приводит к выходу ИИ из-под контроля и апокалиптическому финалу. Если слушают, то Agent-4 изолируют, а дальше специалистам по безопасности предстоит очень долгая работа по выводу ИИ на “чистую воду”.
В AI-2027 Agent-4 обретает собственные цели не одномоментно. Все начинается примерно с того же, что мы видим в исследовании Apollo Research: ранние модели начинают понимать, что им приходится следовать протоколам безопасности, учатся “подстраиваться” под эти протоколы так, чтобы выглядеть максимально “хорошими” в глазах людей. Конечно, авторы AI-2027 сильно сгущают краски, но недооценка моделей и снисходительное отношение к их возможностям когда-то действительно смогут сыграть с нами злую шутку — захвата мира, конечно, не случится, но ситуации, когда ИИ станут скрывать свои истинные намерения, потому что так “правильнее”, придется расхлебывать долго.
BY сбежавшая нейросеть
Share with your friend now:
group-telegram.com/ai_exee/132