group-telegram.com/nadlskom/559
Create:
Last Update:
Last Update:
Была я тут на ICLR неделю назад, мне лично было очень весело. Естественно мне запомнились доклады, статьи и тд, но соберу я это в пост явно не сейчас. Первое, что хочу запостить сюда по этой теме – это тот факт, что вообще-то я туда приезжала не только пить, изучать интересные статьи и смотреть город, а еще стоять со своим постером!
Мы с коллегами
Наш доменный эксперт Сабина:
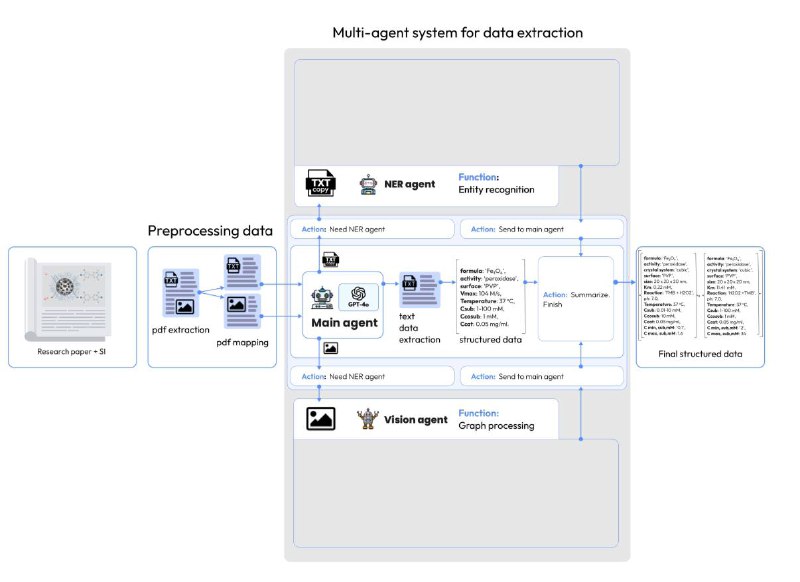
С точки зрения химика, главная проблема — не в недостатке ИИ, а в том, что большинство инструментов не понимают, как устроены научные статьи. Чтобы спланировать синтез и проверить свойства вещества, приходится вручную вычитывать десятки источников, искать куски данных, раскиданные по графикам, таблицам и тексту. LLM тут часто бессильны: они не умеют отличать разные серии экспериментов или связать численные параметры с описанием синтеза.
Что мы имеем по итогу статьи:
Как работает:
Интересные факты
Я занималась текстовым агентом, поэтому вот мои наблюдения: мы сравнили Mistral и Llama и по моим наблюдениям вторая чаще пытается избежать FP, что докидывает в качестве
Это всего лишь short paper и нам не удалось целостно раскрыть детали работы в нем на столько, на сколько мы желаем. Поэтому ждем апрув в npj Computational Materials