group-telegram.com/artificial_stupid/424
Last Update:
Уничтожение LLM System Design
Как отвечать на собеседовании, если вас спросят: «Постройка мне чат-бота с помощью LLM»? Разберем основные шаги на конкретной задаче.
Давайте пойдём по пунктам из этого поста.
Задача: создать чат-бота, который отвечает на финансовые запросы.
Исходные условия:
- В продакшене уже используется API GigaChat (временное решение).
- Доступен API ChatGPT.
- Есть два ассессора.
- Ответы предоставляются без контекста.
Ограничения:
- Ответ за максимум 2 минуты.
- Аппаратные ресурсы: 4 GPU (80 ГБ каждая, A100).
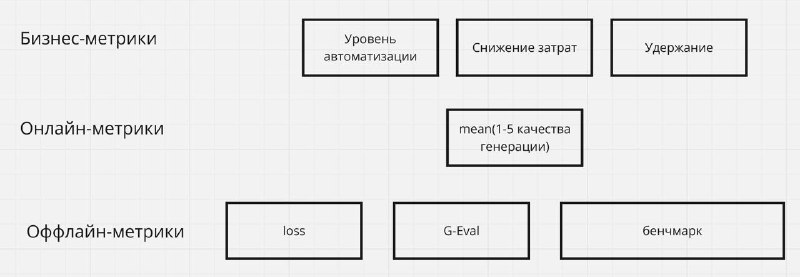
Бизнесовые метрики
- Уровень автоматизации — процент запросов, обработанных ботом без операторов.
- Снижение затрат — экономия на поддержке
- Удержание клиентов — сколько пользователей продолжают пользоваться услугами после общения с ботом. Но эту метрику сложно определить, поэтому для простоты стоит поделить на тех пользовался чат-ботом, а кто не пользовался.
Онлайн-метрики:
- Удовлетворенность клиентов (CSAT) — пользовательская оценка (1–5).
Оффлайн-метрики:
- Loss — насколько хорошо обучена модель.
G-Eval — метод «LLM as Judge», когда одна модель оценивает ответы другой по качеству (например, от 1 до 5).
Оценка ассессоров — реальные люди оценивают ответы по техническому заданию. Это ключевая метрика, с которой можно проверить корреляцию с G-Eval.
Бенчмарки — открытые или специально созданные под задачу бизнеса.
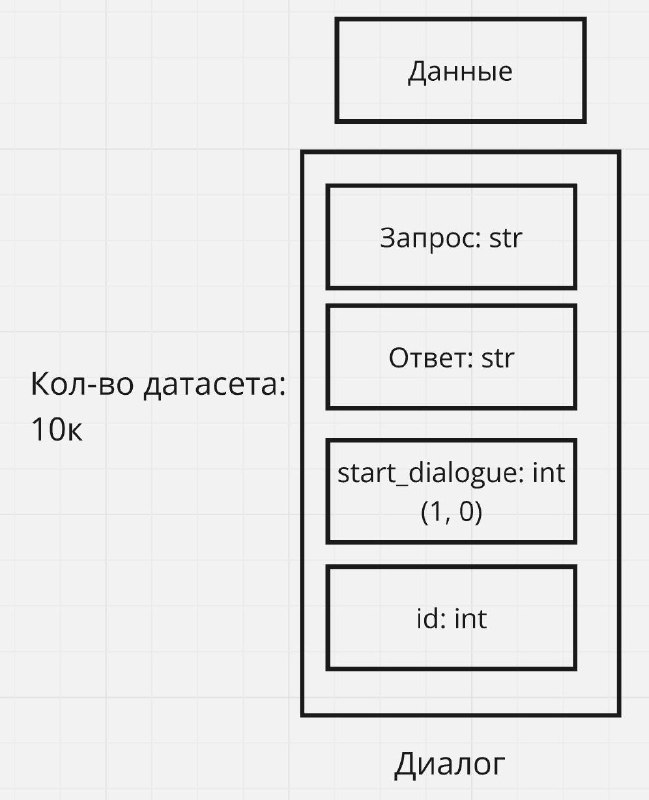
Выделяем ключевые сущности:
У нас есть диалог, а в диалоге:
- Запрос пользователя
- Ответ модели
- Маркер начала диалога
- Идентификаторы запроса, ответа, пользователя и т.д.
Способы получения данных:
Объем данных: Для обучения LoRA потребуется хотя бы 10 тысяч примеров для тренировки и около 700 для тестирования.
Для упрощения пока исключаем поиск контекста, работу с контекстом распишу в следующей части)
Бейзлайн: предположим, что у нас уже есть метрики для текущего решения (например, на GigaChat).
Входные данные:
X — запрос пользователя.
Y — эталонный ответ.
Модели:
llama3.1 400b. Пробуем сначала запромпить модель и смотрим на результаты бенчмарков.
saiga_llama3.1 70b. Сначала промптим, затем обучаем под конкретную задачу.
Loss: Используем CrossEntropyLoss — простой и надежный метод для обучения LoRA на основе SFT.
Метрики:
На тренировочной выборке оцениваем Loss.
На тестовой — G-Eval, оценки ассессоров (на 500 случайных примерах) и бенчмарки.
Деплой: Для деплоя используем vllm.
- Добавить контекст в ответы для повышения точности модели (реализуем в следующей части).
-Применить ORPO-метод, чтобы модель лучше понимала, какие ответы допустимы, а какие нет.
- Квантизация или дистилляция для того, чтобы уменьшить latency