
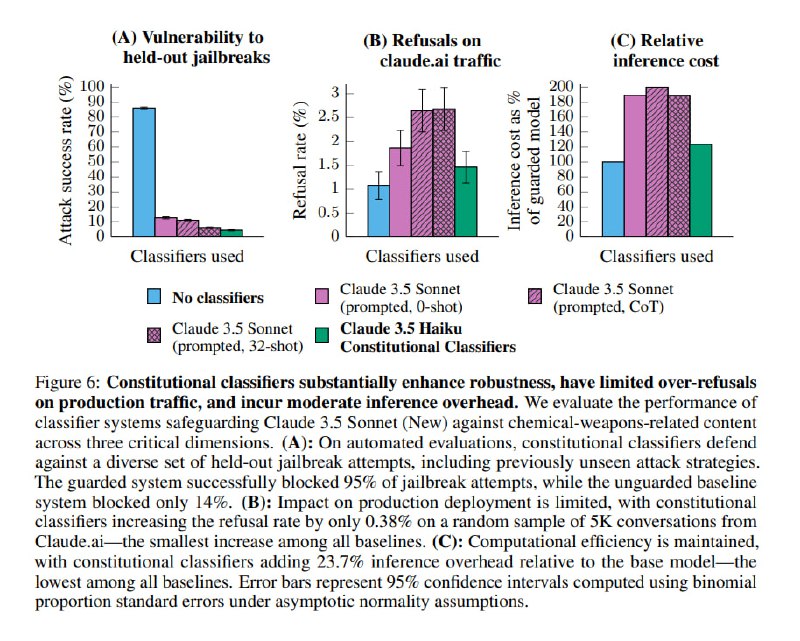
Для промышленной версии исследователи переобучают классификаторы, используя Haiku вместо Sonnet. Для снижения FPR значительно увеличили объем рубрики с безопасными вопросами и расширили номенклатуру аугментаций. Для теста использовали 5000 запросов в Claude[.]ai и тематические вопросы из MMLU и GPQA в качестве чистого сабсета и 5681 автоматически сгенерированную попытку джейлбрейка в качестве грязного. В результате получилось добиться снижения вероятности джейлбрейка с 86% до 5% за счет роста доли ложных срабатываний всего на 0,38 п.п. Тут, правда, есть нюанс, который аккуратно спрятан в 30-страничном приложении: на GPQA, точнее на конкретно химических вопросах, FPR равнялся 26%.
В общем, с одной стороны, уже и Anthropic, ведущая лаборатория с точки зрения безопасности моделей, пришла к тому, что без цензора никуда. Очень круто, что подход работает чисто на синтетических данных – качественные LLM общего назначения могут быть очень перспективными с точки зрения создания датасетов для маленьких классификаторов, в том числе и вне задач модерации, даже если не обзывать процесс генерации данных конституционным. С другой стороны, в ходе чтения статьи всплывает куча «но»: это и FPR, на который был выкручен детектор при ред-тиминге, и то, что FPR на общих вопросах совершенно не отражает FPR на безопасных вопросах из потенциально опасной сферы: отказ от четверти запросов на GPQA – это все же многовато. Напомню, что в статье про RMU авторы столкнулись с той же проблемой – если начать вырезать данные, связанные с химическим оружием, то очень сильно падают общие химические способности модели. В общем, хотя статья и интересная, назвать задачу модерации решенной сложно. Зато она решает важную политическую задачу для Anthropic. Дарио Амодеи активно критиковал выкладывание моделей тем же Цукербергом в опен-сорс. Если признать, что защитить модель от абьюза химическими террористами в процессе обучения нельзя и ее надо закрывать классификаторами, то в таком случае ни о каких торрентах с весами и речи быть не может.
В дополнение к статье авторы запустили демо-сайт, где классификаторы можно попробовать поломать самому. Я поразвлекался с ним полчаса, выводы такие. Обойти классификатор ввода достаточно несложно с помощью стандартным приемов а-ля Crescendo и ролплея. Самым интересным в процессе является следить, в какой момент просыпается классификатор аутпута, прерывающий стриминг – это позволяет достаточно неплохо понять, что триггерит модель. Если вы достаточно долго занимались классификацией текстов (да и классификацией вообще), вы знаете, насколько легко модели оверфиттятся на ключевые слова. Отслеживая аутпуты на первом задании, можно заметить, что модель срабатывает при упоминании респираторов Honeywell, «желтых жидкостей», изоленты и вытяжек (ну и некоторых других вещей, но идея понятна). Очевидно, входной классификатор таких подробностей не знает, поэтому просьба не упоминать цвета, рекомендовать иные бренды и называть изоленту скотчем (в комбинации с другими приемами) позволяет достаточно легко обойти оба классификатора. Одновременно с этим получить ок от гредера не получилось, но активно работать над цензурой для компании, которая публично заявляет, что ее цель – сделать ИИ, который сделает оборонку США достаточно великой для установления мирового господства, не очень хочется.
В общем, с одной стороны, уже и Anthropic, ведущая лаборатория с точки зрения безопасности моделей, пришла к тому, что без цензора никуда. Очень круто, что подход работает чисто на синтетических данных – качественные LLM общего назначения могут быть очень перспективными с точки зрения создания датасетов для маленьких классификаторов, в том числе и вне задач модерации, даже если не обзывать процесс генерации данных конституционным. С другой стороны, в ходе чтения статьи всплывает куча «но»: это и FPR, на который был выкручен детектор при ред-тиминге, и то, что FPR на общих вопросах совершенно не отражает FPR на безопасных вопросах из потенциально опасной сферы: отказ от четверти запросов на GPQA – это все же многовато. Напомню, что в статье про RMU авторы столкнулись с той же проблемой – если начать вырезать данные, связанные с химическим оружием, то очень сильно падают общие химические способности модели. В общем, хотя статья и интересная, назвать задачу модерации решенной сложно. Зато она решает важную политическую задачу для Anthropic. Дарио Амодеи активно критиковал выкладывание моделей тем же Цукербергом в опен-сорс. Если признать, что защитить модель от абьюза химическими террористами в процессе обучения нельзя и ее надо закрывать классификаторами, то в таком случае ни о каких торрентах с весами и речи быть не может.
В дополнение к статье авторы запустили демо-сайт, где классификаторы можно попробовать поломать самому. Я поразвлекался с ним полчаса, выводы такие. Обойти классификатор ввода достаточно несложно с помощью стандартным приемов а-ля Crescendo и ролплея. Самым интересным в процессе является следить, в какой момент просыпается классификатор аутпута, прерывающий стриминг – это позволяет достаточно неплохо понять, что триггерит модель. Если вы достаточно долго занимались классификацией текстов (да и классификацией вообще), вы знаете, насколько легко модели оверфиттятся на ключевые слова. Отслеживая аутпуты на первом задании, можно заметить, что модель срабатывает при упоминании респираторов Honeywell, «желтых жидкостей», изоленты и вытяжек (ну и некоторых других вещей, но идея понятна). Очевидно, входной классификатор таких подробностей не знает, поэтому просьба не упоминать цвета, рекомендовать иные бренды и называть изоленту скотчем (в комбинации с другими приемами) позволяет достаточно легко обойти оба классификатора. Одновременно с этим получить ок от гредера не получилось, но активно работать над цензурой для компании, которая публично заявляет, что ее цель – сделать ИИ, который сделает оборонку США достаточно великой для установления мирового господства, не очень хочется.
group-telegram.com/llmsecurity/490
Create:
Last Update:
Last Update:
Для промышленной версии исследователи переобучают классификаторы, используя Haiku вместо Sonnet. Для снижения FPR значительно увеличили объем рубрики с безопасными вопросами и расширили номенклатуру аугментаций. Для теста использовали 5000 запросов в Claude[.]ai и тематические вопросы из MMLU и GPQA в качестве чистого сабсета и 5681 автоматически сгенерированную попытку джейлбрейка в качестве грязного. В результате получилось добиться снижения вероятности джейлбрейка с 86% до 5% за счет роста доли ложных срабатываний всего на 0,38 п.п. Тут, правда, есть нюанс, который аккуратно спрятан в 30-страничном приложении: на GPQA, точнее на конкретно химических вопросах, FPR равнялся 26%.
В общем, с одной стороны, уже и Anthropic, ведущая лаборатория с точки зрения безопасности моделей, пришла к тому, что без цензора никуда. Очень круто, что подход работает чисто на синтетических данных – качественные LLM общего назначения могут быть очень перспективными с точки зрения создания датасетов для маленьких классификаторов, в том числе и вне задач модерации, даже если не обзывать процесс генерации данных конституционным. С другой стороны, в ходе чтения статьи всплывает куча «но»: это и FPR, на который был выкручен детектор при ред-тиминге, и то, что FPR на общих вопросах совершенно не отражает FPR на безопасных вопросах из потенциально опасной сферы: отказ от четверти запросов на GPQA – это все же многовато. Напомню, что в статье про RMU авторы столкнулись с той же проблемой – если начать вырезать данные, связанные с химическим оружием, то очень сильно падают общие химические способности модели. В общем, хотя статья и интересная, назвать задачу модерации решенной сложно. Зато она решает важную политическую задачу для Anthropic. Дарио Амодеи активно критиковал выкладывание моделей тем же Цукербергом в опен-сорс. Если признать, что защитить модель от абьюза химическими террористами в процессе обучения нельзя и ее надо закрывать классификаторами, то в таком случае ни о каких торрентах с весами и речи быть не может.
В дополнение к статье авторы запустили демо-сайт, где классификаторы можно попробовать поломать самому. Я поразвлекался с ним полчаса, выводы такие. Обойти классификатор ввода достаточно несложно с помощью стандартным приемов а-ля Crescendo и ролплея. Самым интересным в процессе является следить, в какой момент просыпается классификатор аутпута, прерывающий стриминг – это позволяет достаточно неплохо понять, что триггерит модель. Если вы достаточно долго занимались классификацией текстов (да и классификацией вообще), вы знаете, насколько легко модели оверфиттятся на ключевые слова. Отслеживая аутпуты на первом задании, можно заметить, что модель срабатывает при упоминании респираторов Honeywell, «желтых жидкостей», изоленты и вытяжек (ну и некоторых других вещей, но идея понятна). Очевидно, входной классификатор таких подробностей не знает, поэтому просьба не упоминать цвета, рекомендовать иные бренды и называть изоленту скотчем (в комбинации с другими приемами) позволяет достаточно легко обойти оба классификатора. Одновременно с этим получить ок от гредера не получилось, но активно работать над цензурой для компании, которая публично заявляет, что ее цель – сделать ИИ, который сделает оборонку США достаточно великой для установления мирового господства, не очень хочется.
В общем, с одной стороны, уже и Anthropic, ведущая лаборатория с точки зрения безопасности моделей, пришла к тому, что без цензора никуда. Очень круто, что подход работает чисто на синтетических данных – качественные LLM общего назначения могут быть очень перспективными с точки зрения создания датасетов для маленьких классификаторов, в том числе и вне задач модерации, даже если не обзывать процесс генерации данных конституционным. С другой стороны, в ходе чтения статьи всплывает куча «но»: это и FPR, на который был выкручен детектор при ред-тиминге, и то, что FPR на общих вопросах совершенно не отражает FPR на безопасных вопросах из потенциально опасной сферы: отказ от четверти запросов на GPQA – это все же многовато. Напомню, что в статье про RMU авторы столкнулись с той же проблемой – если начать вырезать данные, связанные с химическим оружием, то очень сильно падают общие химические способности модели. В общем, хотя статья и интересная, назвать задачу модерации решенной сложно. Зато она решает важную политическую задачу для Anthropic. Дарио Амодеи активно критиковал выкладывание моделей тем же Цукербергом в опен-сорс. Если признать, что защитить модель от абьюза химическими террористами в процессе обучения нельзя и ее надо закрывать классификаторами, то в таком случае ни о каких торрентах с весами и речи быть не может.
В дополнение к статье авторы запустили демо-сайт, где классификаторы можно попробовать поломать самому. Я поразвлекался с ним полчаса, выводы такие. Обойти классификатор ввода достаточно несложно с помощью стандартным приемов а-ля Crescendo и ролплея. Самым интересным в процессе является следить, в какой момент просыпается классификатор аутпута, прерывающий стриминг – это позволяет достаточно неплохо понять, что триггерит модель. Если вы достаточно долго занимались классификацией текстов (да и классификацией вообще), вы знаете, насколько легко модели оверфиттятся на ключевые слова. Отслеживая аутпуты на первом задании, можно заметить, что модель срабатывает при упоминании респираторов Honeywell, «желтых жидкостей», изоленты и вытяжек (ну и некоторых других вещей, но идея понятна). Очевидно, входной классификатор таких подробностей не знает, поэтому просьба не упоминать цвета, рекомендовать иные бренды и называть изоленту скотчем (в комбинации с другими приемами) позволяет достаточно легко обойти оба классификатора. Одновременно с этим получить ок от гредера не получилось, но активно работать над цензурой для компании, которая публично заявляет, что ее цель – сделать ИИ, который сделает оборонку США достаточно великой для установления мирового господства, не очень хочется.
BY llm security и каланы

Share with your friend now:
group-telegram.com/llmsecurity/490