🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
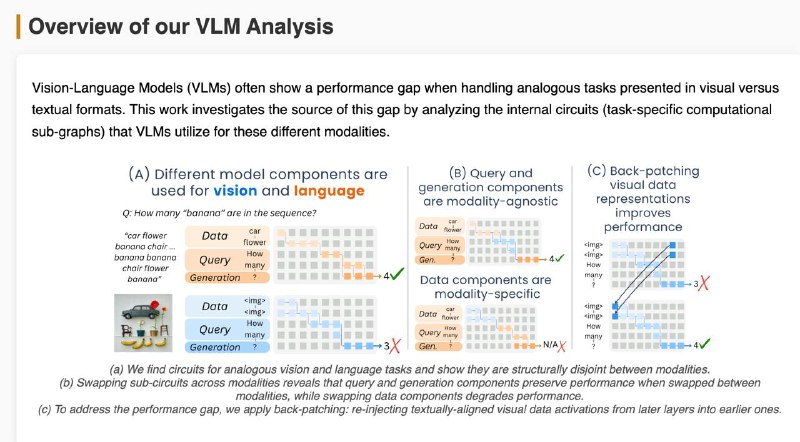
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
Update March 8, 2022: EFF has clarified that Channels and Groups are not fully encrypted, end-to-end, updated our post to link to Telegram’s FAQ for Cloud and Secret chats, updated to clarify that auto-delete is available for group and channel admins, and added some additional links. Perpetrators of such fraud use various marketing techniques to attract subscribers on their social media channels. Channels are not fully encrypted, end-to-end. All communications on a Telegram channel can be seen by anyone on the channel and are also visible to Telegram. Telegram may be asked by a government to hand over the communications from a channel. Telegram has a history of standing up to Russian government requests for data, but how comfortable you are relying on that history to predict future behavior is up to you. Because Telegram has this data, it may also be stolen by hackers or leaked by an internal employee. The S&P 500 fell 1.3% to 4,204.36, and the Dow Jones Industrial Average was down 0.7% to 32,943.33. The Dow posted a fifth straight weekly loss — its longest losing streak since 2019. The Nasdaq Composite tumbled 2.2% to 12,843.81. Though all three indexes opened in the green, stocks took a turn after a new report showed U.S. consumer sentiment deteriorated more than expected in early March as consumers' inflation expectations soared to the highest since 1981. Telegram has become more interventionist over time, and has steadily increased its efforts to shut down these accounts. But this has also meant that the company has also engaged with lawmakers more generally, although it maintains that it doesn’t do so willingly. For instance, in September 2021, Telegram reportedly blocked a chat bot in support of (Putin critic) Alexei Navalny during Russia’s most recent parliamentary elections. Pavel Durov was quoted at the time saying that the company was obliged to follow a “legitimate” law of the land. He added that as Apple and Google both follow the law, to violate it would give both platforms a reason to boot the messenger from its stores.
from ca