🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
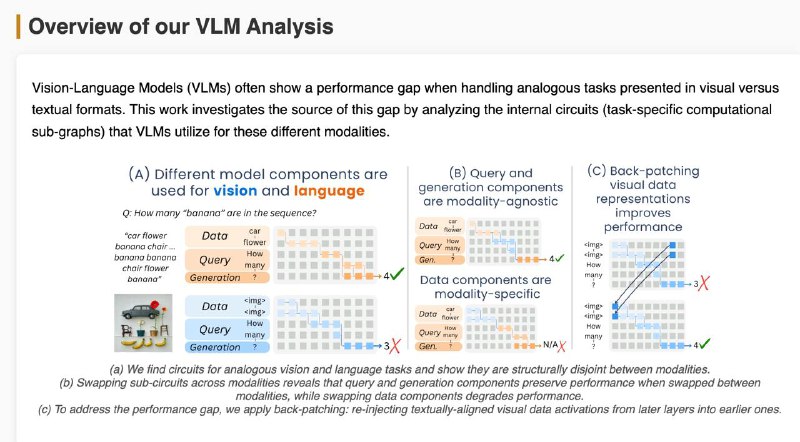
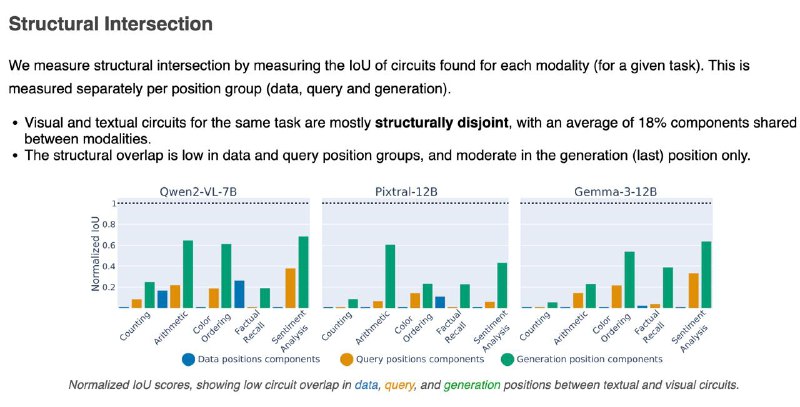
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
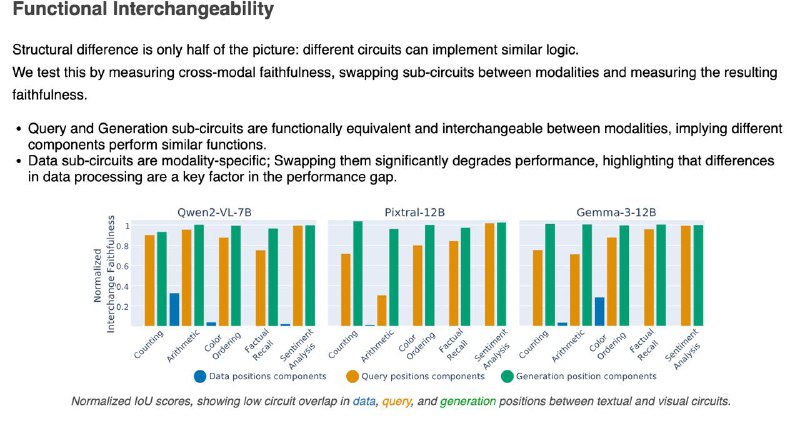
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
That hurt tech stocks. For the past few weeks, the 10-year yield has traded between 1.72% and 2%, as traders moved into the bond for safety when Russia headlines were ugly—and out of it when headlines improved. Now, the yield is touching its pandemic-era high. If the yield breaks above that level, that could signal that it’s on a sustainable path higher. Higher long-dated bond yields make future profits less valuable—and many tech companies are valued on the basis of profits forecast for many years in the future. As a result, the pandemic saw many newcomers to Telegram, including prominent anti-vaccine activists who used the app's hands-off approach to share false information on shots, a study from the Institute for Strategic Dialogue shows. "We as Ukrainians believe that the truth is on our side, whether it's truth that you're proclaiming about the war and everything else, why would you want to hide it?," he said. These entities are reportedly operating nine Telegram channels with more than five million subscribers to whom they were making recommendations on selected listed scrips. Such recommendations induced the investors to deal in the said scrips, thereby creating artificial volume and price rise. Telegram has gained a reputation as the “secure” communications app in the post-Soviet states, but whenever you make choices about your digital security, it’s important to start by asking yourself, “What exactly am I securing? And who am I securing it from?” These questions should inform your decisions about whether you are using the right tool or platform for your digital security needs. Telegram is certainly not the most secure messaging app on the market right now. Its security model requires users to place a great deal of trust in Telegram’s ability to protect user data. For some users, this may be good enough for now. For others, it may be wiser to move to a different platform for certain kinds of high-risk communications.
from ca