
{kind=link}
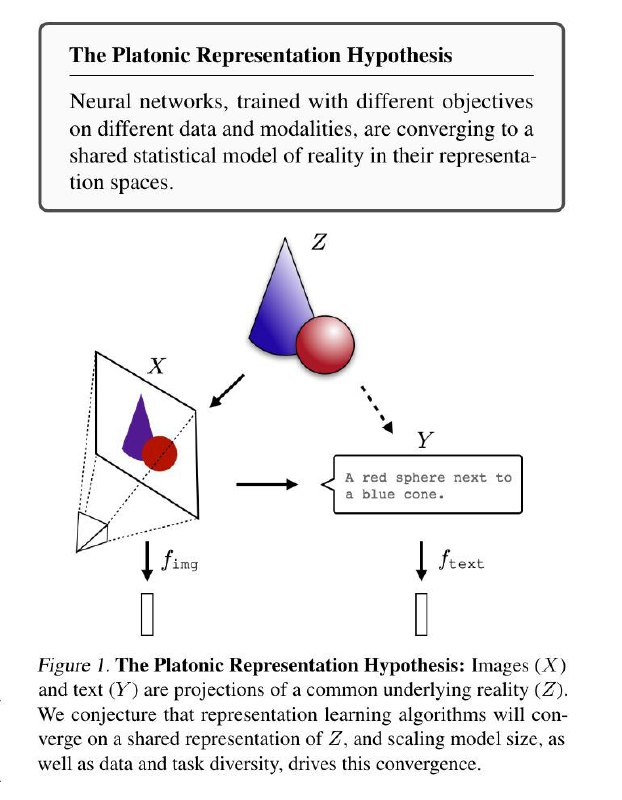
The Platonic Representation Hypothesis
https://arxiv.org/abs/2405.07987
Знал ли Платон, что однажды его процитируют в ML-папире? 🤔 Маловероятно, но гипотеза авторов статьи как будто имеет довольно очевидные корни: они утверждают, что нейросети с разными архитектурами, натренированные на разных данных и на разные задачи, сходятся к одному общему представлению реальности (то есть видят хотя бы одну и ту же тень на стене платоновской пещеры)
Чтобы как-то количественно измерить representational alignment, они предлагают довольно простой метод – взять feature vectors, измерить расстояния между комбинациями разных точек, посмотреть насколько близки оказываются эти расстояния среди разных моделей (если конкретно, то берут kNN вокруг точки и смотрят, какое будет пересечение этих множеств у моделей)
Результаты из этого получаются следующие:
1. Модели, которые лучше всего решают Visual Task Adaptation Benchmark, оказываются достаточно сильно заалайнены друг с другом -> алаймент повышается с увеличением способностей моделей
2. Репрезенатции сходятся в нескольких модальностях сразу: чтобы это проверить, брали Wikipedia caption
dataset. Репрезентации языковых моделей использовали, чтобы считать расстояния между описаниями пар картинок, а визуальные модели – между самими изображениями. На графике видно, что взимосвязь между перфомансом языковых моделей и их алайнментом с визуальными моделями линейная
В этой секции авторы упоминаюь другую интересную статью, в которой авторы выяснили, что внутренние визуальные репрезентации LLM настолько хороши, что они могут генерировать изображения и отвечать на вопросы по простым картинкам, если их представить в виде кода, который они могут обрабатывать
3. Языковые модели, которые хорошо заалайнены с визуальными, оказались и лучше на downstream задачах, типа Hellaswag (задания на здравый смысл) и GSM8K (математика)
Почему такой алайнмент происходит? Основное объяснение авторов – constrained optimization. Можно считать, что каждое новое наблюдение и новая задача накладывают ограничения на наш набор весов. Если мы наращиваем объем задач, то остается только небольшое подмножество репрезентаций, которое бы позволило модели решать все эти задачи на достаточно хорошем уровне. Плюс, благодаря регуляризации у нас всегда есть simplicity bias, который ограничивает наше пространство решений еще больше. Теоретический клейм тут как раз в том, что такое оптимальное подмножество в результате должно отражать underlying reality
Под конец статьи есть еще небольшой эксперимент, где авторы показывают, что модели, натренированные предсказывать coocurrence цветов в текстовых и визуальных данных, примерно совпадают с человеческим восприятием цветов (их отдаленности или близости друг к другу). Помимо теоретического аргумента, это также отбивает потенциальный пункт критики, что alignment среди больших моделей наблюдается потому, что они все учится чуть ли не на всем Интернете (в этом тесте использовалиь только маленькие модели)
Очень интересные мысли есть и в дискашене. Например, что делать с информацией, которая существует только в одной модальности (how could an image convey a concept like “I believe in the freedom of speech”)?
https://arxiv.org/abs/2405.07987
Знал ли Платон, что однажды его процитируют в ML-папире? 🤔 Маловероятно, но гипотеза авторов статьи как будто имеет довольно очевидные корни: они утверждают, что нейросети с разными архитектурами, натренированные на разных данных и на разные задачи, сходятся к одному общему представлению реальности (то есть видят хотя бы одну и ту же тень на стене платоновской пещеры)
Чтобы как-то количественно измерить representational alignment, они предлагают довольно простой метод – взять feature vectors, измерить расстояния между комбинациями разных точек, посмотреть насколько близки оказываются эти расстояния среди разных моделей (если конкретно, то берут kNN вокруг точки и смотрят, какое будет пересечение этих множеств у моделей)
Результаты из этого получаются следующие:
1. Модели, которые лучше всего решают Visual Task Adaptation Benchmark, оказываются достаточно сильно заалайнены друг с другом -> алаймент повышается с увеличением способностей моделей
2. Репрезенатции сходятся в нескольких модальностях сразу: чтобы это проверить, брали Wikipedia caption
dataset. Репрезентации языковых моделей использовали, чтобы считать расстояния между описаниями пар картинок, а визуальные модели – между самими изображениями. На графике видно, что взимосвязь между перфомансом языковых моделей и их алайнментом с визуальными моделями линейная
В этой секции авторы упоминаюь другую интересную статью, в которой авторы выяснили, что внутренние визуальные репрезентации LLM настолько хороши, что они могут генерировать изображения и отвечать на вопросы по простым картинкам, если их представить в виде кода, который они могут обрабатывать
3. Языковые модели, которые хорошо заалайнены с визуальными, оказались и лучше на downstream задачах, типа Hellaswag (задания на здравый смысл) и GSM8K (математика)
Почему такой алайнмент происходит? Основное объяснение авторов – constrained optimization. Можно считать, что каждое новое наблюдение и новая задача накладывают ограничения на наш набор весов. Если мы наращиваем объем задач, то остается только небольшое подмножество репрезентаций, которое бы позволило модели решать все эти задачи на достаточно хорошем уровне. Плюс, благодаря регуляризации у нас всегда есть simplicity bias, который ограничивает наше пространство решений еще больше. Теоретический клейм тут как раз в том, что такое оптимальное подмножество в результате должно отражать underlying reality
Под конец статьи есть еще небольшой эксперимент, где авторы показывают, что модели, натренированные предсказывать coocurrence цветов в текстовых и визуальных данных, примерно совпадают с человеческим восприятием цветов (их отдаленности или близости друг к другу). Помимо теоретического аргумента, это также отбивает потенциальный пункт критики, что alignment среди больших моделей наблюдается потому, что они все учится чуть ли не на всем Интернете (в этом тесте использовалиь только маленькие модели)
Очень интересные мысли есть и в дискашене. Например, что делать с информацией, которая существует только в одной модальности (how could an image convey a concept like “I believe in the freedom of speech”)?
group-telegram.com/def_model_train/1030
Create:
Last Update:
Last Update:
The Platonic Representation Hypothesis
https://arxiv.org/abs/2405.07987
Знал ли Платон, что однажды его процитируют в ML-папире? 🤔 Маловероятно, но гипотеза авторов статьи как будто имеет довольно очевидные корни: они утверждают, что нейросети с разными архитектурами, натренированные на разных данных и на разные задачи, сходятся к одному общему представлению реальности (то есть видят хотя бы одну и ту же тень на стене платоновской пещеры)
Чтобы как-то количественно измерить representational alignment, они предлагают довольно простой метод – взять feature vectors, измерить расстояния между комбинациями разных точек, посмотреть насколько близки оказываются эти расстояния среди разных моделей (если конкретно, то берут kNN вокруг точки и смотрят, какое будет пересечение этих множеств у моделей)
Результаты из этого получаются следующие:
1. Модели, которые лучше всего решают Visual Task Adaptation Benchmark, оказываются достаточно сильно заалайнены друг с другом -> алаймент повышается с увеличением способностей моделей
2. Репрезенатции сходятся в нескольких модальностях сразу: чтобы это проверить, брали Wikipedia caption
dataset. Репрезентации языковых моделей использовали, чтобы считать расстояния между описаниями пар картинок, а визуальные модели – между самими изображениями. На графике видно, что взимосвязь между перфомансом языковых моделей и их алайнментом с визуальными моделями линейная
В этой секции авторы упоминаюь другую интересную статью, в которой авторы выяснили, что внутренние визуальные репрезентации LLM настолько хороши, что они могут генерировать изображения и отвечать на вопросы по простым картинкам, если их представить в виде кода, который они могут обрабатывать
3. Языковые модели, которые хорошо заалайнены с визуальными, оказались и лучше на downstream задачах, типа Hellaswag (задания на здравый смысл) и GSM8K (математика)
Почему такой алайнмент происходит? Основное объяснение авторов – constrained optimization. Можно считать, что каждое новое наблюдение и новая задача накладывают ограничения на наш набор весов. Если мы наращиваем объем задач, то остается только небольшое подмножество репрезентаций, которое бы позволило модели решать все эти задачи на достаточно хорошем уровне. Плюс, благодаря регуляризации у нас всегда есть simplicity bias, который ограничивает наше пространство решений еще больше. Теоретический клейм тут как раз в том, что такое оптимальное подмножество в результате должно отражать underlying reality
Под конец статьи есть еще небольшой эксперимент, где авторы показывают, что модели, натренированные предсказывать coocurrence цветов в текстовых и визуальных данных, примерно совпадают с человеческим восприятием цветов (их отдаленности или близости друг к другу). Помимо теоретического аргумента, это также отбивает потенциальный пункт критики, что alignment среди больших моделей наблюдается потому, что они все учится чуть ли не на всем Интернете (в этом тесте использовалиь только маленькие модели)
Очень интересные мысли есть и в дискашене. Например, что делать с информацией, которая существует только в одной модальности (how could an image convey a concept like “I believe in the freedom of speech”)?
https://arxiv.org/abs/2405.07987
Знал ли Платон, что однажды его процитируют в ML-папире? 🤔 Маловероятно, но гипотеза авторов статьи как будто имеет довольно очевидные корни: они утверждают, что нейросети с разными архитектурами, натренированные на разных данных и на разные задачи, сходятся к одному общему представлению реальности (то есть видят хотя бы одну и ту же тень на стене платоновской пещеры)
Чтобы как-то количественно измерить representational alignment, они предлагают довольно простой метод – взять feature vectors, измерить расстояния между комбинациями разных точек, посмотреть насколько близки оказываются эти расстояния среди разных моделей (если конкретно, то берут kNN вокруг точки и смотрят, какое будет пересечение этих множеств у моделей)
Результаты из этого получаются следующие:
1. Модели, которые лучше всего решают Visual Task Adaptation Benchmark, оказываются достаточно сильно заалайнены друг с другом -> алаймент повышается с увеличением способностей моделей
2. Репрезенатции сходятся в нескольких модальностях сразу: чтобы это проверить, брали Wikipedia caption
dataset. Репрезентации языковых моделей использовали, чтобы считать расстояния между описаниями пар картинок, а визуальные модели – между самими изображениями. На графике видно, что взимосвязь между перфомансом языковых моделей и их алайнментом с визуальными моделями линейная
В этой секции авторы упоминаюь другую интересную статью, в которой авторы выяснили, что внутренние визуальные репрезентации LLM настолько хороши, что они могут генерировать изображения и отвечать на вопросы по простым картинкам, если их представить в виде кода, который они могут обрабатывать
3. Языковые модели, которые хорошо заалайнены с визуальными, оказались и лучше на downstream задачах, типа Hellaswag (задания на здравый смысл) и GSM8K (математика)
Почему такой алайнмент происходит? Основное объяснение авторов – constrained optimization. Можно считать, что каждое новое наблюдение и новая задача накладывают ограничения на наш набор весов. Если мы наращиваем объем задач, то остается только небольшое подмножество репрезентаций, которое бы позволило модели решать все эти задачи на достаточно хорошем уровне. Плюс, благодаря регуляризации у нас всегда есть simplicity bias, который ограничивает наше пространство решений еще больше. Теоретический клейм тут как раз в том, что такое оптимальное подмножество в результате должно отражать underlying reality
Под конец статьи есть еще небольшой эксперимент, где авторы показывают, что модели, натренированные предсказывать coocurrence цветов в текстовых и визуальных данных, примерно совпадают с человеческим восприятием цветов (их отдаленности или близости друг к другу). Помимо теоретического аргумента, это также отбивает потенциальный пункт критики, что alignment среди больших моделей наблюдается потому, что они все учится чуть ли не на всем Интернете (в этом тесте использовалиь только маленькие модели)
Очень интересные мысли есть и в дискашене. Например, что делать с информацией, которая существует только в одной модальности (how could an image convey a concept like “I believe in the freedom of speech”)?
BY я обучала одну модель


Share with your friend now:
group-telegram.com/def_model_train/1030