group-telegram.com/def_model_train/942
Last Update:
Language models can explain neurons in language models
Очень крутая и очень интерактивная статья про explainable ai. Советую всем открыть и потыкать:
https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
В чем идея:
1. Берем исследуюемую модель и какой-то фиксированный датасет. Собираем инфу о том, какие нейроны как сильно активируются на каждом токене. Далее по этой информации просим GPT-4 для каждого нейрона предположить, за что он отвечает
2. Далее симулирем поведение этого нейрона, исходя из его предполагаемого назначения. Передаем в ту же GPT-4 описание, что этот нейрон якобы делает, кусок текста, и просим предсказать, какой силы активация должна у этого нейрона быть на последнем токене последовательности
3. Прогоняем этот текст через исследуемую модель и смотрим, какие активации у каких нейронов реально получились. Считаем скор, насколько предположение GPT-4 оказалось точным
Авторы исследовали GPT-2 XL и в целом для большей части нейронов ни GPT-4, ни человеческим разметчикам не удалось точно предполжить, что они делают. Но нашлись 1000+ нейронов, для которых удалось предсказать объяснение с точностью 0.8+. Еще авторы находят, что часто нейроны полисемантичны, и гораздо большую точность можно получить, если брать линейные комбинации от наиболее «ярких» нейронов
Как я уже написала, самая крутая чать работы – интерактивная
- Есть сниппет текста, где для каждого слова можно посмотреть, какие нейроны на него реагируют, какое им дано объяснение и к какому семантическому кластеру они относятся
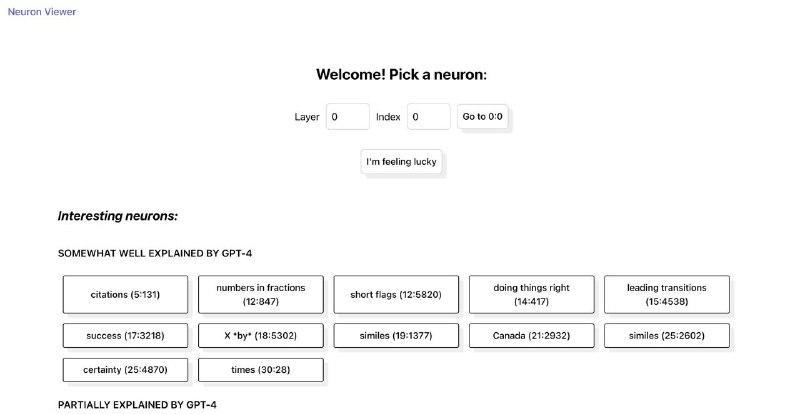
– И есть neuron viewer, где для каждого нейрона GPT-2 можно посмотреть его объяснение и все токены в датасете, на которые он реагирует. Можно предложить и свое объяснение его поведения, так что мб так и накраудсорсится 🥳
Там же перечислен набор нейронов, которые кажется были хорошо объяснены. Например, авторы нашли отдельный нейрон для Канады, нейрон для улыбок и даже абстрактные нейроны про «doing things right» и «certainty»