🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
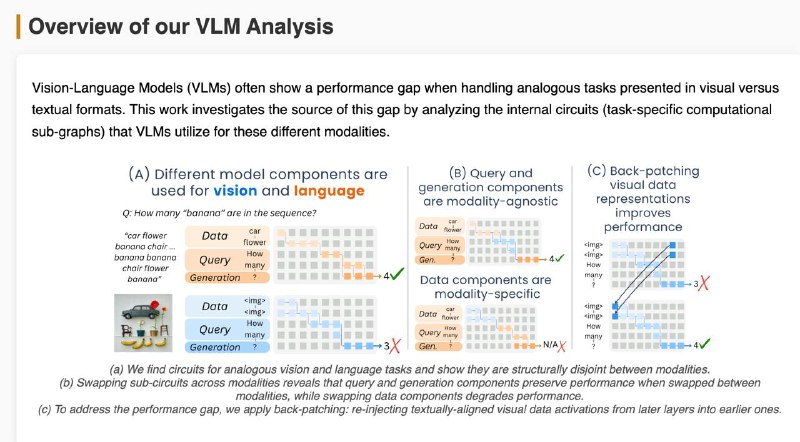
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
Telegram, which does little policing of its content, has also became a hub for Russian propaganda and misinformation. Many pro-Kremlin channels have become popular, alongside accounts of journalists and other independent observers. And while money initially moved into stocks in the morning, capital moved out of safe-haven assets. The price of the 10-year Treasury note fell Friday, sending its yield up to 2% from a March closing low of 1.73%. Markets continued to grapple with the economic and corporate earnings implications relating to the Russia-Ukraine conflict. “We have a ton of uncertainty right now,” said Stephanie Link, chief investment strategist and portfolio manager at Hightower Advisors. “We’re dealing with a war, we’re dealing with inflation. We don’t know what it means to earnings.” In February 2014, the Ukrainian people ousted pro-Russian president Viktor Yanukovych, prompting Russia to invade and annex the Crimean peninsula. By the start of April, Pavel Durov had given his notice, with TechCrunch saying at the time that the CEO had resisted pressure to suppress pages criticizing the Russian government. The S&P 500 fell 1.3% to 4,204.36, and the Dow Jones Industrial Average was down 0.7% to 32,943.33. The Dow posted a fifth straight weekly loss — its longest losing streak since 2019. The Nasdaq Composite tumbled 2.2% to 12,843.81. Though all three indexes opened in the green, stocks took a turn after a new report showed U.S. consumer sentiment deteriorated more than expected in early March as consumers' inflation expectations soared to the highest since 1981.
from es