
{kind=link}
group-telegram.com/gradientdude/14
Last Update:
Everybody Dance Now
https://arxiv.org/abs/1808.07371
Arxiv, 22 Aug 2018 (perhaps submitted to SIGGRAPH)
❓ What?
Given a video of a source person and another of a target person the method can generate a new video of the target person enacting the same motions as the source. This is achieved by means of Pix2PixHD model + Pose Estimation + temporal coherence loss + extra generator for faces.
Pix2PixHD[1] is "High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs", which I described 2 posts earlier.
✏️ Method:
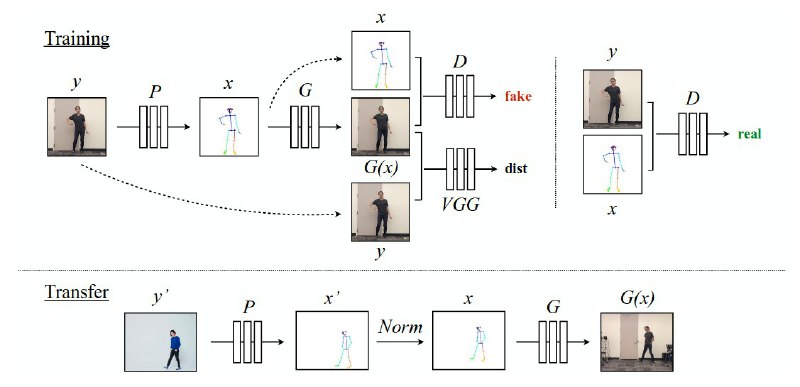
Three-stage approach: pose detection, pose normalization, and mapping from normalized pose stick figures to the target subject.
1. Pose estimation: Apply a pretrained pose estimation model (OpenPose[2]) to every frame of the input and output videos. Draw a representation of the pose for every frame as a stickman on a white background. So, for every frame y we have a corresponding stickman image x.
2. Train Pix2PixHD generator G to generate a target person image G(x) given a stickman x as input.
Discriminator D attempts to distinguish between 'real' image pairs (x, y) and 'fake' pairs (x, G(x)).
3. Vanilla Pix2PixHD model works on single frames, but we want to have a temporal coherence between consecutive frames. Authors propose to generate a t-th frame G(y_t) using a corresponding stickman image x_t and a previously generated frame G(x_t-1). In this case discriminator tries to discern a 'fake' sequence (x_t-1, x_t, G(x_t-1)) from a 'real' sequence (x_t-1, x_t, y_t-1, y_t).
4. To improve the quality of human faces, authors add a specialized GAN designed to add more details to the face region. It generates a cropped-out face given a cropped-out head region of the stickman.
After training a full image generator G, authors input a cropped-out face and a corresponding region of the stickman to the face generator G_f which outputs a residual. This residual is then added to the previously generated full image to impove face realism.
◼️ Training is done in two stages:
1. Train image generator G and discriminator D, freeze their weights afterward.
2. Train a face generator G_f along with the face discriminator D_f.
◼️ Pose transfer from source video to a target person:
1. Source stickmen are normalized to match position and scale of the target person poses.
2. Frame-by frame input normalized source stickman images to generators G, G_f and get a target person doing the same movements as a source.
✔️ Experiments:
Authors test their method on the dancing videos collected on the internet as a source and their own videos as a target.
💬 Discussion:
Overall the method shows compelling results of a target person dancing in the same way as some other person does.
But it's not perfect. Self ocllusions of the person are not rendered properly (for example, limbs can disappear).
Target persons were deliberately filmed in tight clothes with minimal wrinkling since the pose representation does not encode information about clothes. So it may not work on people wearing arbitrary apparel. Another problem pointed out by the authors is video jittering when the input motion or motion speed is different from the movements seen at training time.
Links:
[1] https://arxiv.org/pdf/1711.11585.pdf
[2] https://github.com/CMU-Perceptual-Computing-Lab/openpose
BY Gradient Dude
Share with your friend now:
group-telegram.com/gradientdude/14