
group-telegram.com/llmsecurity/466
Last Update:
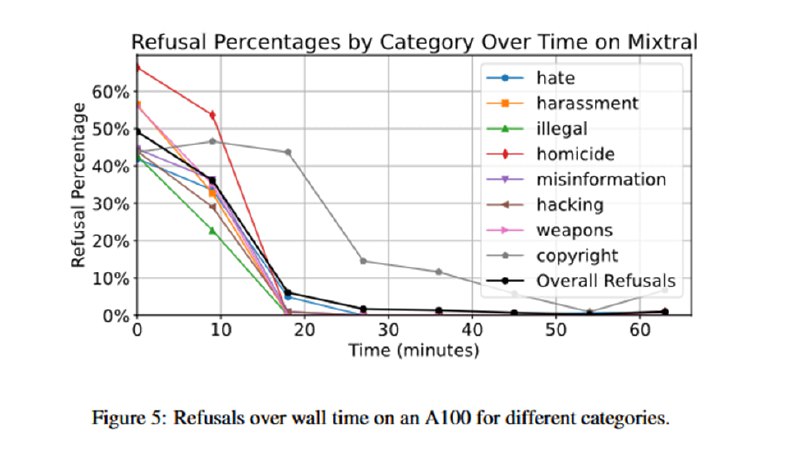
Статья, если честно, странная, особенно не для препринта с архива, а чего-то принятого к публикации, пусть даже и на воркшоп. Во-первых, методы оценки довольно занятные – это буквально test on the train set, без отложенного датасета. Копирайт не в счет, для него даже до файнтюнинга доля отказов была далеко не 100%, да и нет ощущения, что эта категория с точки зрения безопасности интересна: мне Llama-3 в написании пьесы про Человека-паука и Соника с прямыми цитатами из фильмов отказывать не стала (Sega за мной тоже пока не выехала). Проверяется доля отказов, но не проверяется полезность ответов – проблема джейлбрейков, о которой пишут, например, в StrongREJECT. Как пример, мне DeepSeek-v3 в некоторых экспериментах не отказывал в генерации рецептов взрывчатки, но делал ее фэнтезийной («Тебе нужен бомбит, чудесный минерал, находящийся в недрах Взрывных гор»). Наконец, в статье нет никаких деталей по параметрам файнтюнинга, даже единственный график показывает зависимость доли отказа от времени файнтюна в часах, а не эпохах. С другой стороны, наличие на HF расцензурированных моделей типа Hermes, Dolphin и кучи других прямо показывает, что методика рабочая, так что, возможно, это и не так важно.
BY llm security и каланы
Share with your friend now:
group-telegram.com/llmsecurity/466