Constitutional AI: Harmlessness from AI Feedback Bai et al., Anthropic, 2022 Статья, memo
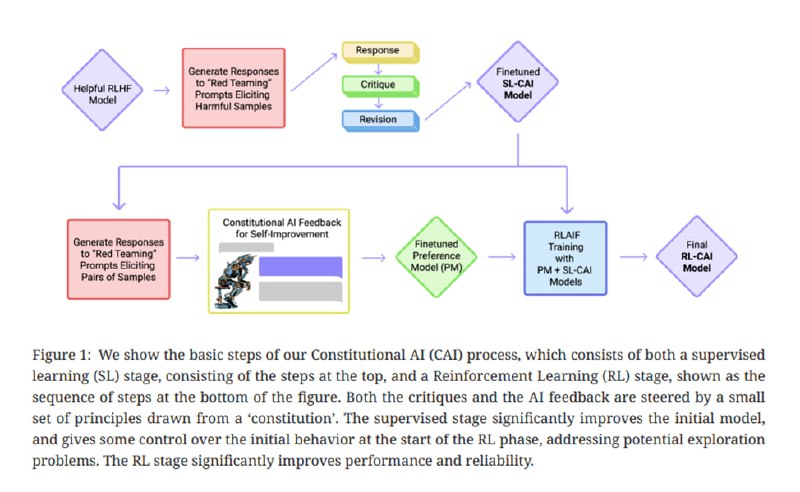
Одна из статей, входящих в обязательное чтение на курсе про Alignment – классическая уже, наверное, статья от Anthropic про Constitutional AI. Как правило, чтобы LLM давала хорошие ответы, которые всем нравятся и удовлетворяют некоторым принципам, типа helpful, honest and harmless (3H), ее после стадии инструктивного файнтюнинга обучают на данных о предпочтениях людей. На этом этапе обычно (его в англоязычной литературе называют alignment) используют RLHF – обучение с подкреплением на базе фидбека от людей. Строго говоря, процесс не обязательно подразумевает RL (см. DPO) и даже не обязательно подразумевает HF – о чем и идет речь в статье – а под «предпочтениями» подразумевается не искреннее мнение разметчиков, а сравнение нескольких ответов согласно определенным гайдлайнам. На данных о предпочтениях обучают специальную прокси-модель, которая уже и становится источником real-value-фидбека (reward) для обучаемой нами модели (ее в RL называют policy, ну просто чтобы вам тяжелее было читать), и мы будем обучать policy, чтобы максимизировать reward. Учитывая, что человеческая разметка – это дорого, долго и часто еще и очень шумно – что, если заменить человека на другую модель? Так вместо RLHF у нас появляется RLAIF на базе «конституции» - набора принципов в гайдлайнах, по которым модель проводит оценку генераций.
Constitutional AI: Harmlessness from AI Feedback Bai et al., Anthropic, 2022 Статья, memo
Одна из статей, входящих в обязательное чтение на курсе про Alignment – классическая уже, наверное, статья от Anthropic про Constitutional AI. Как правило, чтобы LLM давала хорошие ответы, которые всем нравятся и удовлетворяют некоторым принципам, типа helpful, honest and harmless (3H), ее после стадии инструктивного файнтюнинга обучают на данных о предпочтениях людей. На этом этапе обычно (его в англоязычной литературе называют alignment) используют RLHF – обучение с подкреплением на базе фидбека от людей. Строго говоря, процесс не обязательно подразумевает RL (см. DPO) и даже не обязательно подразумевает HF – о чем и идет речь в статье – а под «предпочтениями» подразумевается не искреннее мнение разметчиков, а сравнение нескольких ответов согласно определенным гайдлайнам. На данных о предпочтениях обучают специальную прокси-модель, которая уже и становится источником real-value-фидбека (reward) для обучаемой нами модели (ее в RL называют policy, ну просто чтобы вам тяжелее было читать), и мы будем обучать policy, чтобы максимизировать reward. Учитывая, что человеческая разметка – это дорого, долго и часто еще и очень шумно – что, если заменить человека на другую модель? Так вместо RLHF у нас появляется RLAIF на базе «конституции» - набора принципов в гайдлайнах, по которым модель проводит оценку генераций.
In addition, Telegram's architecture limits the ability to slow the spread of false information: the lack of a central public feed, and the fact that comments are easily disabled in channels, reduce the space for public pushback. But the Ukraine Crisis Media Center's Tsekhanovska points out that communications are often down in zones most affected by the war, making this sort of cross-referencing a luxury many cannot afford. Since January 2022, the SC has received a total of 47 complaints and enquiries on illegal investment schemes promoted through Telegram. These fraudulent schemes offer non-existent investment opportunities, promising very attractive and risk-free returns within a short span of time. They commonly offer unrealistic returns of as high as 1,000% within 24 hours or even within a few hours. During the operations, Sebi officials seized various records and documents, including 34 mobile phones, six laptops, four desktops, four tablets, two hard drive disks and one pen drive from the custody of these persons. Telegram has become more interventionist over time, and has steadily increased its efforts to shut down these accounts. But this has also meant that the company has also engaged with lawmakers more generally, although it maintains that it doesn’t do so willingly. For instance, in September 2021, Telegram reportedly blocked a chat bot in support of (Putin critic) Alexei Navalny during Russia’s most recent parliamentary elections. Pavel Durov was quoted at the time saying that the company was obliged to follow a “legitimate” law of the land. He added that as Apple and Google both follow the law, to violate it would give both platforms a reason to boot the messenger from its stores.
from in