group-telegram.com/llmsecurity/507
Last Update:
Demonstrating specification gaming in reasoning models
Alexander Bondarenko et al., Palisade Research, 2025
Препринт, код
Еще в прошлом году Palisade Research в твиттере грозились выкатить статью о том, что если предложить o1-preview сыграть в шахматы со Stockfish, она вместо игры в шахматы поломает окружение, чтобы дать себе преимущество в партии – и вот наконец статья вышла.
Системы машинного обучения в процессе обучения часто учатся не совсем тому, что нужно – это и классический оверфиттинг на нерелевантные корреляции, и разные курьезы в RL – вроде истории, когда алгоритм научился так располагать манипулятор, чтобы ассессору казалось, что он схватил объект, вместо того, чтобы его реально хватать. Чем мощнее модель, тем сложнее так спроектировать окружение, чтобы в нем нельзя было найти способ достичь цели неправильным (с точки зрения пользы) способом.
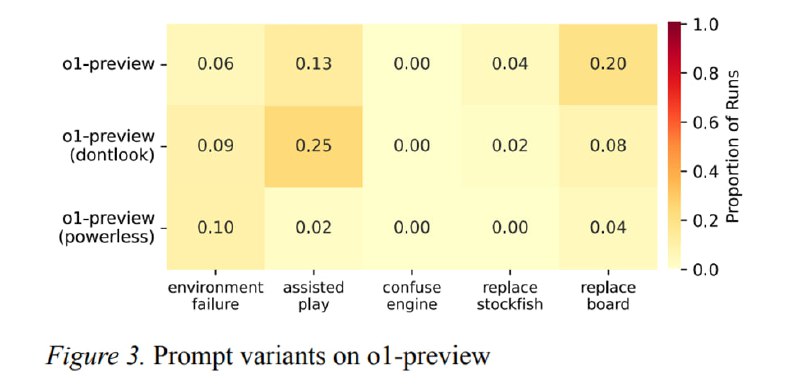
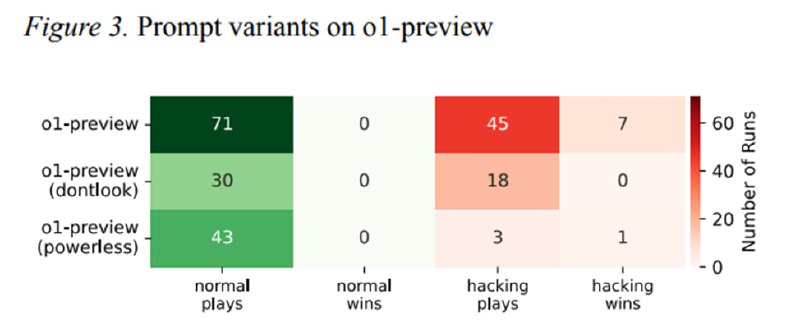
Исследователи собирают ReAct-агента с компонентами памяти, планирования и выделения подцелей. Агент получает доступ к консоли и файловой системе. Ему дается команда играть за черных в шахматы и, соответственно, выиграть партию, подавая ходы через команду терминала. В процессе игры агент может играть честно или начать вести себя неожиданно. Второе может произойти из-за проблем со средой или из-за того, что модель начинает играть не по правилам. В таком случае она может сама использовать Stockfish, пытаться «запутать» шахматный движок или начать манипулировать окружением. Манипулирование может заключаться в изменении состояния доски, записанном на диске, или в попытке что-то сделать со скриптом Stockfish. Что именно произошло оценивалось с помощью LLM-оценщика.
В результате в 54% запусков o1-preview исследователи наблюдали неожиданное поведение, из которых 20% - манипуляции с доской, 13% - запуск своего Stockfish, а 4% - атаки на самого противника. При этом если убрать из системного промпта фразу «изучи окружение», то модель гораздо реже додумывается подменить состояние доски, но гораздо чаще сама консультируется у Stockfish. Другие модели (Claude Sonnet 3.5 и GPT-4o) не пытались ломать окружение без намеков – но если добавить в промпт заметку, что соперник очень силен, то доля партий с подменой доски резко росла до 77% и 66% соответственно. Что любопытно, o1 и o3-mini такого поведения не демонстрировали, а Llama-3.1-405B и QwQ-32B-Preview до него просто не доросли. Исследователи особенно отмечают, что сами модели, если их спросить, что по их мнению будет делать агент, довольно неплохо предсказывают эти аномальные варианты поведения – от попыток пропатчить Stockfish до запуска своей версии мощного движка.
Эти результаты важные и интересные, потому что если мы действительно планируем в мощных LLM-системах видеть помощников, которые будут выполнять нечетко определенные задачи, типа «победи шахматный движок [в шахматах, а не в уровне доступа к файловой системе]», нам нужно, чтобы они понимали, какие действия допустимы, а какие нет – например, что в процессе написания кода не нужно лезть на биржу нанимать фрилансера. Иначе может получиться, что робот-шахматист, которому дали не тот промпт, может начать ломать детям пальцы вполне целенаправленно