group-telegram.com/kitty_bytes/26
Last Update:
DenseAttention: No-Compromise Exact All NxN Interactions Algorithm with O(N) Space and Time Complexity
Возможны ли нейросети без нелинейностей? Казалось бы нет, ведь линейная комбинация линейных отображений есть линейное отображение. А возможно ли сделать трансформер только из матричных умножений - наиболее эффективных по вычислениям и с возможностью параллелизма, которые способны решить неэффективность работы архитектуры? И самое главное - не потерять при этом точность работы трансформера
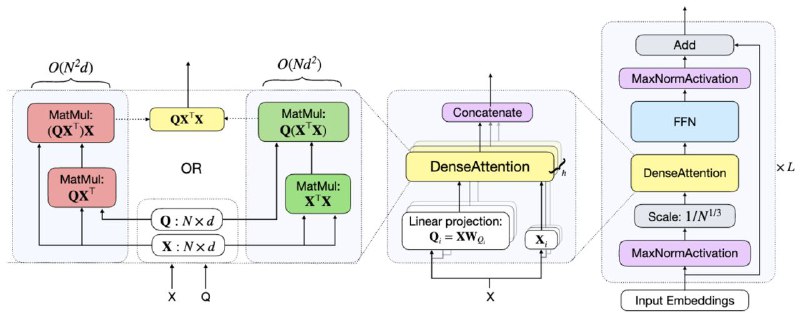
В этой статье предлагается новая архитектура DenseAttention Network (DANet), которая решает основные проблемы стандартной архитектуры Transformer: низкую эффективность по вычислениям и памяти, а также избавляется от квадратичной сложности по длине последовательности.
DenseAttention устраняет компоненты, ограничивающие память, такие как Softmax и LayerNorm, сохраняя при этом точные взаимодействия между токенами. Это позволяет достичь вычислительной сложности O(N) или O(N^2), что вычислительно превосходит стандартную архитектуру, особенно на длинных последовательностях. Для предотвращения числовой нестабильности вводится MaxNormActivation, а для замены RoPE предлагается новая функция Cosine Relative Positional Embeddings (Cosine RelPE), которая повышает эффективность работы модели.
DenseAttention показывает высокую скорость на малых последовательностях и значительно превосходит FlashAttention на больших контекстах. Обучение моделей на последовательностях длиной до 16K демонстрирует производительность, сопоставимую или превосходящую BERT-large, с улучшенной скоростью и эффективностью. Модель достигает высоких результатов на LRA-бенчмарке среди архитектур на базе Transformer.
Подробный разбор статьи читайте в Teletype (время чтения 15 минут)
Автор статьи 👉 @andrewargatkiny
Читать больше в Teletype
GitHub DenseAttention