
group-telegram.com/knowledge_accumulator/271
Last Update:
OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment [2025]
У рекомендательных инженеров есть мечта - каким-то образом обучить одну модель, которая будет напрямую выбирать айтемы из огромной базы, без всяких multi-stage ranking костылей. Каким-то образом она должна совмещать в себе скорость методов кандидатогенерации и качество моделей ранжирования.
Одним из ответов на данный вызов называют генеративные рекомендации. Я уже писал про статью о Generative Retrieval (TIGER) от гугла. Суть этого подхода заключается в обучении семантических ID-шников для айтемов, делающих осмысленным генерацию айтема декодерным трансформером.
Здесь подход похожий, но авторы утверждают, что запустили такую систему в прод вместо всей системы ранжирования и получили профит. От TIGER система достаточно сильно отличается, давайте посмотрим внимательнее.
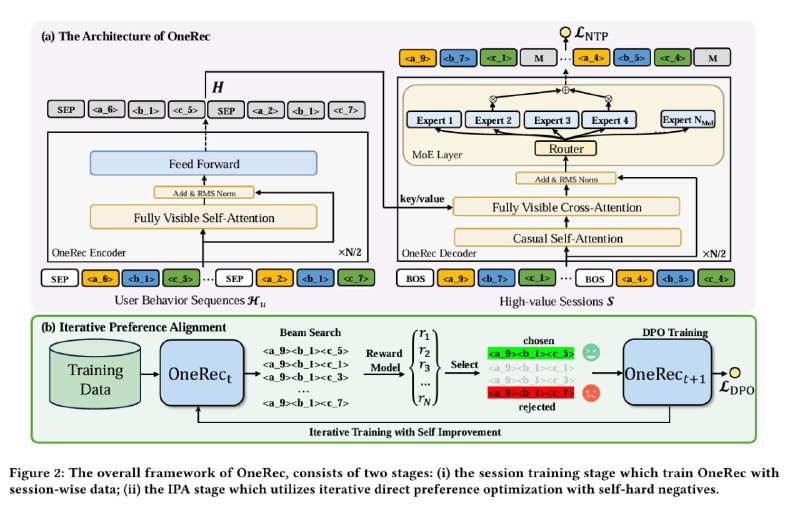
Начнём с того, что авторы не используют никакие RQ-VAE для генерации семантических ID. Вместо этого на датасете из эмбеддингов айтемов N раз применяют "Balanced K-means" - вариацию алгоритма, в которой форсируется одинаковый размер кластеров. После каждого из N применений из векторов вычитают центроиды - получается почти как в RQ-VAE, но по-другому.
Теперь к обучению трансформерного декодера. Собирается датасет из "хороших пользовательских сессий" - последовательностей событий просмотра видео, которые удовлетворяют пачке критериев - кол-во видео, общее кол-во секунд, кол-во положительных взаимодействий.
Каждое видео заменяется на последовательность его семантических ID + разделитель. На этих данных мы самым обычным образом обучаем декодер, максимизируя вероятность выдачи "хорошей сессии". Один внимательный инженер заметил, что это по сути одна итерация Cross Entropy Method, со всеми вытекающими - например, тут отсутствует оценка индивидуальных действий.
Но это только предобучение. После этого применяют "DPO с дополнительной reward model", но это не RLHF, а свой велосипед.
Сначала RM обучают по сессии предсказывать награду - наличие лайка или суммарный watchtime. Далее генератор просят выдать N последовательностей, которые RM ранжирует и выбирает лучшую и худшую - эти пары и будут использоваться для обучения DPO.
Получается, что авторы, лишь бы не использовать RL, игнорируют наличие у них Reward Model и используют метод, разработанный для того, чтобы не обучать Reward Model. Как опытный RL-щик, одобряю.
Онлайн-результаты такие: 0.1B-декодер даёт +0.57%, 1B-декодер даёт +1.21% и 1B + их DPO даёт +1.68%. Очень интересный результат, думаю, мы тоже будем копать в какую-то такую сторону. Чем меньше у системы кусков и моделей, тем лучше с практической точки зрения.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
group-telegram.com/knowledge_accumulator/271