group-telegram.com/lightautoml/182
Last Update:
В классических алгоритмах для решения suprevised задач на табличных данных модель обучается с нуля, в статье используется подход с предобучением:
1. Генерируются 130 миллионов синтетических датасетов с помощью каузальных графов, которые имитируют сложные зависимости в данных, пропуски, выбросы.
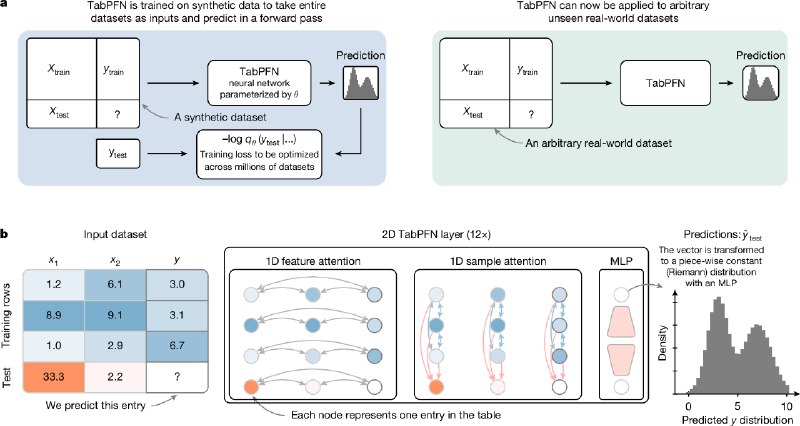
2. На сгенерированных данных предобучается трансформер, предсказывая таргет test выборки, получая на вход train как контекст. Для каждой ячейки таблицы используется отдельная репрезентация. Используется механизм внимания как по строкам, так и по столбцам таблицы.
3. Вместо привычных отдельных "fit" и "predict", трансформер за один проход получая и train, и test новой задачи одновременно, делает инференс на test, используя in-context learning. Простыми словами, модель обучена однажды, но подхватывает зависимости в данных из подаваемого в контекст датасета и сразу делает предсказания.
1. Скорость и качество: в задачах классификации и регрессии на данных до 10к строк и 500 признаков за несколько секунд получает качество лучше, чем ансамбль из базовых алгоритмов (бустинги, лес, линейные), которые тюнились в течение нескольких часов.
2. Минимум работы: алгоритм не нужно тюнить, имеет отбор признаков, нативно работает с числовыми и категориальными признаками, а также с пропусками.
3. Плюсы foundation моделей: возможность получить распределение таргета, генерировать данные итд.
4. Неплохо показывает себя на временных рядах.
1. Статья показала эффективность foundation моделей в домене табличных данных, теперь у бустингов сильные конкуренты.
2. Пока есть вопросы с точки зрения эффективности инференса, ограниченности контекста, но дальше будут улучшения.
3. Интересно, что TabPFN v2 можно назвать AutoML решением, ведь для решения задачи он не требует ни настройки гиперпараметров, ни предобработки данных.
Тема интересная, у нас имеются наработки по этой теме, и мы работаем над их применением в LightAutoML
#обзор