
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
Hunyuan video2video и image2video
Эти воркфлоу используют HunyuanLoom (flowEdit) - эта штука преобразует входное видео в размытый движущийся поток (почти как controlnet). Обычный denoise тут не нужен, с ним картинка будет кипеть.
Для сохранения черт лица нужна лора на лицо. Без нее лицо будет другое. Куча лор на персонажей есть на civitai.
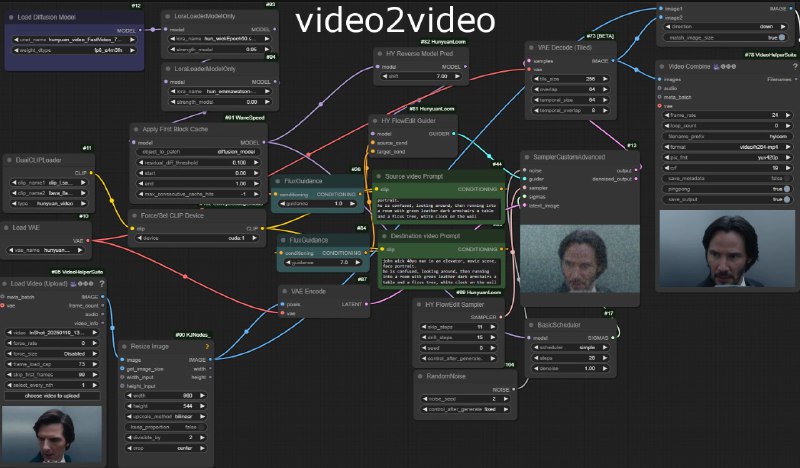
## video2video
Это самый простой воркфлоу, получается лучше всех. Использует HunyuanLoom (flowEdit). Для создания видео с Кеану использовал: skip_steps: 11, drift_steps: 15. Лора: 0.95 довольно хорошо передает его лицо под любым углом.
лору на Кеану: https://civitai.com/models/1131159/john-wick-hunyuan-video-lora
Воркфлоу video2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_video2video.json
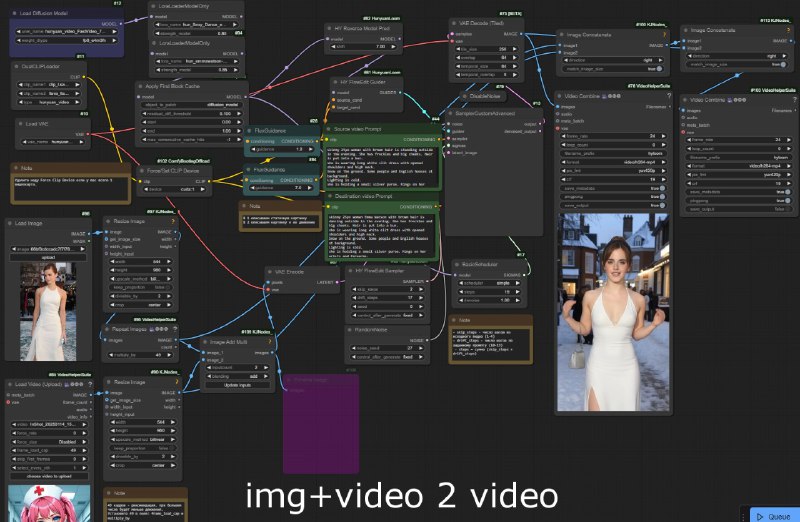
## image+video 2 video
воркфлоу чуть посложнее: берет видео с движением (например, танец) и клеит его поверх статичной картинки. В результате хуньюань подхватывает движения.
видео с исходным танцем: https://civitai.com/images/50838820
лора на танцы: https://civitai.com/models/1110311/sexy-dance
Воркфлоу image+video2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_imageVideo2video.json
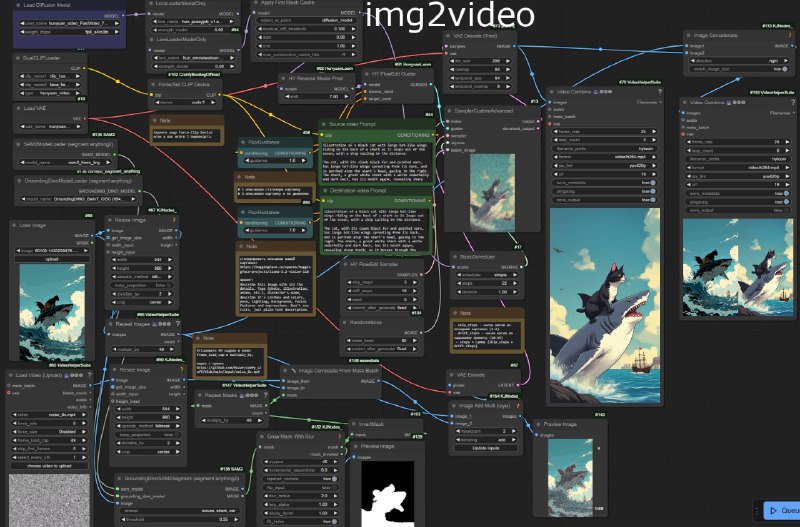
## image2video
самый сложный воркфлоу. Использует:
- HunyuanLoom (flowEdit)
- SAM2 comfyUI (можно и без него, но тогда маску, того что должно двигаться, придется рисовать пальцем)
- Видео белого шума: https://github.com/Mozer/comfy_stuff/blob/main/input/noise_8s.mp4
- Детальное описание вашей картинки.
- Воркфлоу image2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_img2video_sam_flow_noise.json
Именно динамичный шум позволяет создать движение. Без него движения в кадре не будет. Но шум понижает контраст выходного видео, поэтому я рисую его только на тех областях, которые должны двигаться.
Сгенерировать детальное описание вашей картинки на английском можно тут:
https://huggingface.co/spaces/huggingface-projects/llama-3.2-vision-11B
Установка
устанавливаем кастомные ноды в комфи, читаем их описание по установке:
https://github.com/kijai/ComfyUI-HunyuanLoom
https://github.com/neverbiasu/ComfyUI-SAM2 (опционально)
Замечания:
- 2 секунды видео на 3090 генерируются за 2 минуты (на 3060 - 7 минут).
- Главные параметры flowEdit: skip_steps (кол-во шагов из исходного видео или картинки, 1-4) и drift_steps (количество шагов генерации по промпту, 10-19).
- Конечное значение steps = skip_steps + drift_steps. Обычно выходит 17-22 для hanyuan fast модели. 10 шагов точно не хватит. Для обычной не fast модели будет больше (не тестил). Чем больше skip_steps тем более похожей на исходную картинку (или исходное видео) будет результат. Но тем меньше движения можно задать промптом. Если результат сильно размыт - проверяйте значение steps, оно должно быть равно сумме.
- Лучше всего получаются видео длиной 2 секунды (49 кадров). 73 кадра сложнее контролировать. Рекомендуемое разрешение 544x960.
- Есть два поля для промптов: Source prompt (описание вашей картинки) и Destination prompt (описание вашей картинки + движения в кадре).
Звук для вашего видео можно сгенерировать в MMAudio тут: https://huggingface.co/spaces/hkchengrex/MMAudio
Эти воркфлоу используют HunyuanLoom (flowEdit) - эта штука преобразует входное видео в размытый движущийся поток (почти как controlnet). Обычный denoise тут не нужен, с ним картинка будет кипеть.
Для сохранения черт лица нужна лора на лицо. Без нее лицо будет другое. Куча лор на персонажей есть на civitai.
## video2video
Это самый простой воркфлоу, получается лучше всех. Использует HunyuanLoom (flowEdit). Для создания видео с Кеану использовал: skip_steps: 11, drift_steps: 15. Лора: 0.95 довольно хорошо передает его лицо под любым углом.
лору на Кеану: https://civitai.com/models/1131159/john-wick-hunyuan-video-lora
Воркфлоу video2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_video2video.json
## image+video 2 video
воркфлоу чуть посложнее: берет видео с движением (например, танец) и клеит его поверх статичной картинки. В результате хуньюань подхватывает движения.
видео с исходным танцем: https://civitai.com/images/50838820
лора на танцы: https://civitai.com/models/1110311/sexy-dance
Воркфлоу image+video2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_imageVideo2video.json
## image2video
самый сложный воркфлоу. Использует:
- HunyuanLoom (flowEdit)
- SAM2 comfyUI (можно и без него, но тогда маску, того что должно двигаться, придется рисовать пальцем)
- Видео белого шума: https://github.com/Mozer/comfy_stuff/blob/main/input/noise_8s.mp4
- Детальное описание вашей картинки.
- Воркфлоу image2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_img2video_sam_flow_noise.json
Именно динамичный шум позволяет создать движение. Без него движения в кадре не будет. Но шум понижает контраст выходного видео, поэтому я рисую его только на тех областях, которые должны двигаться.
Сгенерировать детальное описание вашей картинки на английском можно тут:
https://huggingface.co/spaces/huggingface-projects/llama-3.2-vision-11B
Describe this image with all the details. Type (photo, illustration, anime, etc.), character's name, describe it's clothes and colors, pose, lighting, background, facial features and expressions. Don't use lists, just plain text description.
Установка
устанавливаем кастомные ноды в комфи, читаем их описание по установке:
https://github.com/kijai/ComfyUI-HunyuanLoom
https://github.com/neverbiasu/ComfyUI-SAM2 (опционально)
Замечания:
- 2 секунды видео на 3090 генерируются за 2 минуты (на 3060 - 7 минут).
- Главные параметры flowEdit: skip_steps (кол-во шагов из исходного видео или картинки, 1-4) и drift_steps (количество шагов генерации по промпту, 10-19).
- Конечное значение steps = skip_steps + drift_steps. Обычно выходит 17-22 для hanyuan fast модели. 10 шагов точно не хватит. Для обычной не fast модели будет больше (не тестил). Чем больше skip_steps тем более похожей на исходную картинку (или исходное видео) будет результат. Но тем меньше движения можно задать промптом. Если результат сильно размыт - проверяйте значение steps, оно должно быть равно сумме.
- Лучше всего получаются видео длиной 2 секунды (49 кадров). 73 кадра сложнее контролировать. Рекомендуемое разрешение 544x960.
- Есть два поля для промптов: Source prompt (описание вашей картинки) и Destination prompt (описание вашей картинки + движения в кадре).
Звук для вашего видео можно сгенерировать в MMAudio тут: https://huggingface.co/spaces/hkchengrex/MMAudio
group-telegram.com/tensorbanana/1175
Create:
Last Update:
Last Update:
Hunyuan video2video и image2video
Эти воркфлоу используют HunyuanLoom (flowEdit) - эта штука преобразует входное видео в размытый движущийся поток (почти как controlnet). Обычный denoise тут не нужен, с ним картинка будет кипеть.
Для сохранения черт лица нужна лора на лицо. Без нее лицо будет другое. Куча лор на персонажей есть на civitai.
## video2video
Это самый простой воркфлоу, получается лучше всех. Использует HunyuanLoom (flowEdit). Для создания видео с Кеану использовал: skip_steps: 11, drift_steps: 15. Лора: 0.95 довольно хорошо передает его лицо под любым углом.
лору на Кеану: https://civitai.com/models/1131159/john-wick-hunyuan-video-lora
Воркфлоу video2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_video2video.json
## image+video 2 video
воркфлоу чуть посложнее: берет видео с движением (например, танец) и клеит его поверх статичной картинки. В результате хуньюань подхватывает движения.
видео с исходным танцем: https://civitai.com/images/50838820
лора на танцы: https://civitai.com/models/1110311/sexy-dance
Воркфлоу image+video2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_imageVideo2video.json
## image2video
самый сложный воркфлоу. Использует:
- HunyuanLoom (flowEdit)
- SAM2 comfyUI (можно и без него, но тогда маску, того что должно двигаться, придется рисовать пальцем)
- Видео белого шума: https://github.com/Mozer/comfy_stuff/blob/main/input/noise_8s.mp4
- Детальное описание вашей картинки.
- Воркфлоу image2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_img2video_sam_flow_noise.json
Именно динамичный шум позволяет создать движение. Без него движения в кадре не будет. Но шум понижает контраст выходного видео, поэтому я рисую его только на тех областях, которые должны двигаться.
Сгенерировать детальное описание вашей картинки на английском можно тут:
https://huggingface.co/spaces/huggingface-projects/llama-3.2-vision-11B
Установка
устанавливаем кастомные ноды в комфи, читаем их описание по установке:
https://github.com/kijai/ComfyUI-HunyuanLoom
https://github.com/neverbiasu/ComfyUI-SAM2 (опционально)
Замечания:
- 2 секунды видео на 3090 генерируются за 2 минуты (на 3060 - 7 минут).
- Главные параметры flowEdit: skip_steps (кол-во шагов из исходного видео или картинки, 1-4) и drift_steps (количество шагов генерации по промпту, 10-19).
- Конечное значение steps = skip_steps + drift_steps. Обычно выходит 17-22 для hanyuan fast модели. 10 шагов точно не хватит. Для обычной не fast модели будет больше (не тестил). Чем больше skip_steps тем более похожей на исходную картинку (или исходное видео) будет результат. Но тем меньше движения можно задать промптом. Если результат сильно размыт - проверяйте значение steps, оно должно быть равно сумме.
- Лучше всего получаются видео длиной 2 секунды (49 кадров). 73 кадра сложнее контролировать. Рекомендуемое разрешение 544x960.
- Есть два поля для промптов: Source prompt (описание вашей картинки) и Destination prompt (описание вашей картинки + движения в кадре).
Звук для вашего видео можно сгенерировать в MMAudio тут: https://huggingface.co/spaces/hkchengrex/MMAudio
Эти воркфлоу используют HunyuanLoom (flowEdit) - эта штука преобразует входное видео в размытый движущийся поток (почти как controlnet). Обычный denoise тут не нужен, с ним картинка будет кипеть.
Для сохранения черт лица нужна лора на лицо. Без нее лицо будет другое. Куча лор на персонажей есть на civitai.
## video2video
Это самый простой воркфлоу, получается лучше всех. Использует HunyuanLoom (flowEdit). Для создания видео с Кеану использовал: skip_steps: 11, drift_steps: 15. Лора: 0.95 довольно хорошо передает его лицо под любым углом.
лору на Кеану: https://civitai.com/models/1131159/john-wick-hunyuan-video-lora
Воркфлоу video2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_video2video.json
## image+video 2 video
воркфлоу чуть посложнее: берет видео с движением (например, танец) и клеит его поверх статичной картинки. В результате хуньюань подхватывает движения.
видео с исходным танцем: https://civitai.com/images/50838820
лора на танцы: https://civitai.com/models/1110311/sexy-dance
Воркфлоу image+video2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_imageVideo2video.json
## image2video
самый сложный воркфлоу. Использует:
- HunyuanLoom (flowEdit)
- SAM2 comfyUI (можно и без него, но тогда маску, того что должно двигаться, придется рисовать пальцем)
- Видео белого шума: https://github.com/Mozer/comfy_stuff/blob/main/input/noise_8s.mp4
- Детальное описание вашей картинки.
- Воркфлоу image2video: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_img2video_sam_flow_noise.json
Именно динамичный шум позволяет создать движение. Без него движения в кадре не будет. Но шум понижает контраст выходного видео, поэтому я рисую его только на тех областях, которые должны двигаться.
Сгенерировать детальное описание вашей картинки на английском можно тут:
https://huggingface.co/spaces/huggingface-projects/llama-3.2-vision-11B
Describe this image with all the details. Type (photo, illustration, anime, etc.), character's name, describe it's clothes and colors, pose, lighting, background, facial features and expressions. Don't use lists, just plain text description.
Установка
устанавливаем кастомные ноды в комфи, читаем их описание по установке:
https://github.com/kijai/ComfyUI-HunyuanLoom
https://github.com/neverbiasu/ComfyUI-SAM2 (опционально)
Замечания:
- 2 секунды видео на 3090 генерируются за 2 минуты (на 3060 - 7 минут).
- Главные параметры flowEdit: skip_steps (кол-во шагов из исходного видео или картинки, 1-4) и drift_steps (количество шагов генерации по промпту, 10-19).
- Конечное значение steps = skip_steps + drift_steps. Обычно выходит 17-22 для hanyuan fast модели. 10 шагов точно не хватит. Для обычной не fast модели будет больше (не тестил). Чем больше skip_steps тем более похожей на исходную картинку (или исходное видео) будет результат. Но тем меньше движения можно задать промптом. Если результат сильно размыт - проверяйте значение steps, оно должно быть равно сумме.
- Лучше всего получаются видео длиной 2 секунды (49 кадров). 73 кадра сложнее контролировать. Рекомендуемое разрешение 544x960.
- Есть два поля для промптов: Source prompt (описание вашей картинки) и Destination prompt (описание вашей картинки + движения в кадре).
Звук для вашего видео можно сгенерировать в MMAudio тут: https://huggingface.co/spaces/hkchengrex/MMAudio
BY Tensor Banana
Share with your friend now:
group-telegram.com/tensorbanana/1175