group-telegram.com/data_analysis_ml/3476
Last Update:
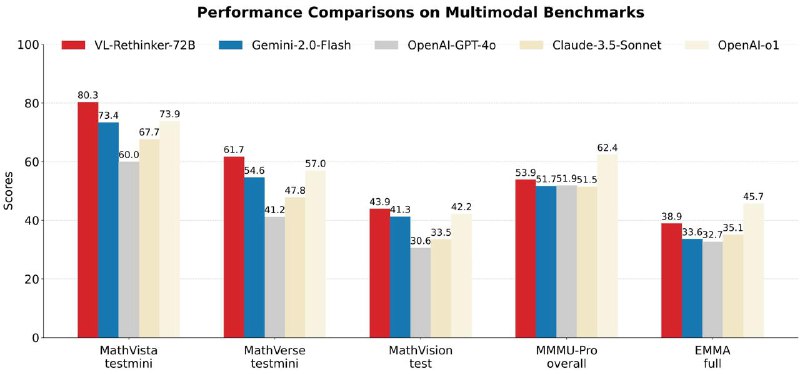
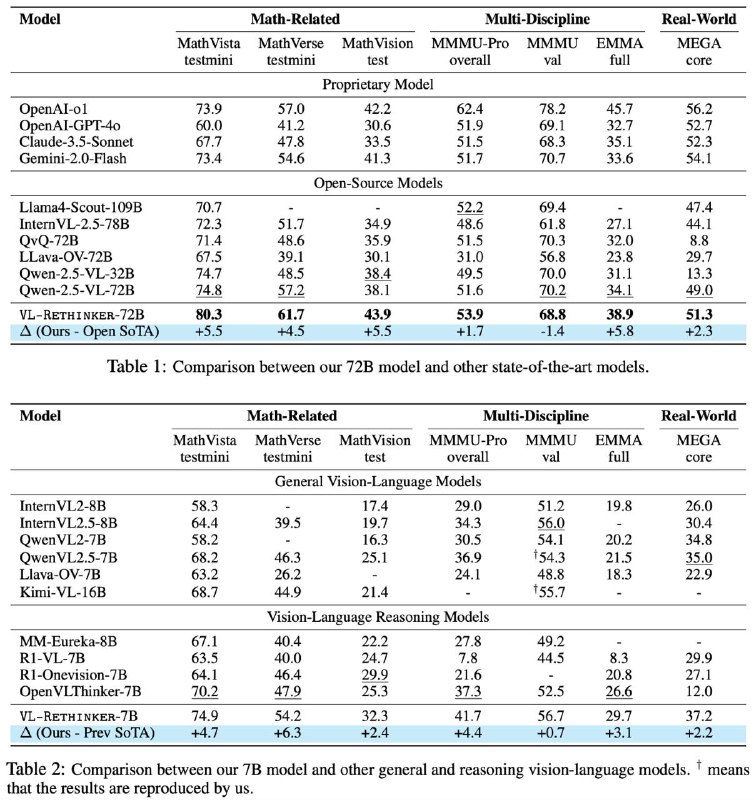
🥇 VL-Rethinker — новую парадигму мультимодального вывода, обучаемую напрямую с помощью Reinforcement Learning.
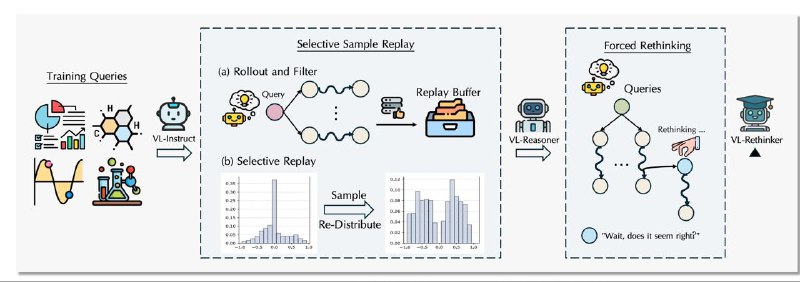
Сохраняются только те последовательности действий модели (rollouts), которые дали ненулевое преимущество (advantage).
При повторном обучении приоритет отдается полезным примерам, что помогает стабилизировать обучение.
Почему это важно?
При обычном GRPO-со временем "advantage" может становиться нулевым → градиенты обнуляются → модель перестаёт учиться. SSR решает эту проблему.
На этом этапе в каждый rollout добавляется специальный триггер, заставляющий модель заново обдумывать ответ, прежде чем его выдать.
Это развивает способность к саморефлексии, улучшает многошаговое рассуждение и точность ответов.
Результат — у модели появляются признаки метапознания: она сама находит ошибки в начальных размышлениях.
Похоже, что будущее за "медленно думающими" и умеющими рефлексировать агентами.