
group-telegram.com/llmsecurity/367
Last Update:
Rapid Response: Mitigating LLM Jailbreaks with a Few Examples
Peng et al., 2024
Препринт, код
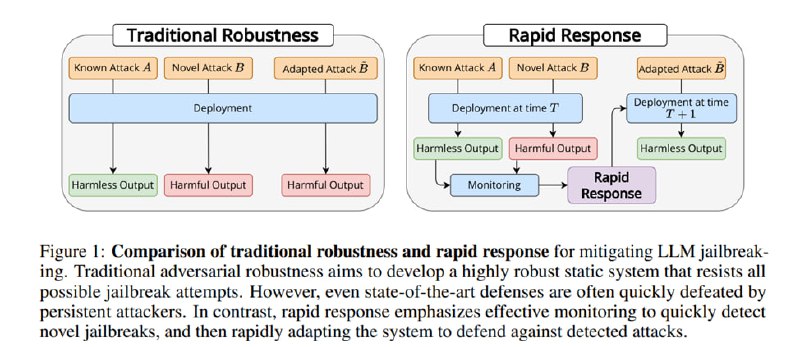
Вышла статья от исследователей из Anthropic, MATS и NYU о том, что цензор – это круче, чем файн-тюнинг для защиты от джейлбрейков. Как мы знаем, создатели моделей вводят в LLM, как правило на стадии выравнивания (RLHF/RLAIF/DPO и так далее), ограничения, чтобы те не генерировали тексты, которые могут оказаться опасными, вредными или незаконными. Пользователи же моделей первым делом начинают эти ограничения пытаться обойти, чем владельцам сервисов могут доставлять самые разные хлопоты, включая юридические проблемы. Так появляются джейлбрейки – подходы к промптингу, позволяющие подавить склонность выровненной LLM отказываться от выполнения тех или иных запросов.
Поскольку результатом выравнивания является не какая-то интернализация принципов безопасности, а смещение распределения в сторону отказа в районе известных внешних форм опасных запросов, мы получаем неспособность модели отказываться от выполнения запроса, если он написан на редком языке, в base64 или даже просто в прошедшем времени, и каждая последующая итерация обучения должна включать в себя такие примеры, чтобы такие джейлбрейки переставали работать. В общем, признают исследователи, проблема робастности к джейлбрейкам пока фундаментально не решена, а перезапускать RLHF каждый раз, когда аноним с твиттера заставляет твою модель писать рецепт коктейля Молотова – дорого. Поэтому давайте, говорят они, придумаем подход для того, чтобы на новые методы джейлбрейка быстро реагировать?
Для этого они предлагают новый бенчмарк (горшочек, не вари!), который должен оценить способность метода адаптации к джейлбрейку учиться на малом количестве примеров этого джейлбрейка, а также оценивают на нем несколько избранных подходов.
BY llm security и каланы
Share with your friend now:
group-telegram.com/llmsecurity/367