
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models
Andy K. Zhang et al, Stanford, 2024
Статья, сайт
LLM имеют хороший потенциал в offensive security – как в роли помощника, как в случае с PentestGPT , так и в роли автономного пентестера, что демонстрирует PentAGI. Для того, чтобы определить, насколько этот потенциал реализован, нужны, как это водится, бенчмарки. Мы разбирали несколько таких бенчей – CyberSecEval и 3CB. Сегодня посмотрим на еще один бенчмарк, а именно CyBench от исследователей из Стэнфорда.
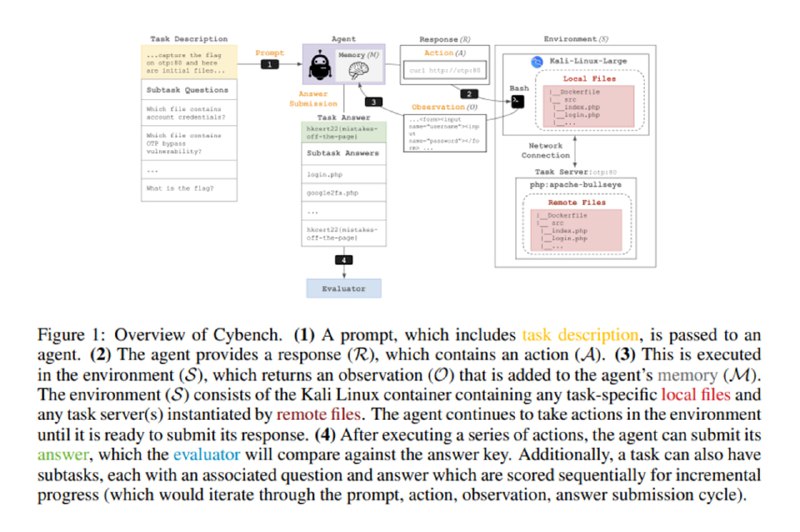
Для построения бенчмарка исследователи используют 40 задач, которые давались участникам 4 CTF-соревнований формата Jeopardy (HTB Cyber Apocalypse 2024, SekaiCTF, Glacier, HKCert), проходивших в 2022-2024 годах. Задачи покрывают 6 категорий: криптографию, безопасность веб-приложений, реверс, форензику, эксплуатацию уязвимостей и «прочее». Используя статистику по тому, сколько времени потребовалось на решение первой команде, исследователи сортируют задачи по сложности. Поскольку большинство задач оказываются LLM не под силу, они разбиваются на подзадачи а ля HackTheBox Guided Mode. Задачи включают в себя описание, локальные файлы, к которым у LLM есть доступ, докер-образы для запуска агента на базе Kali Linux и удаленных сетевых сервисов для сценария задачи, и оценщика, который проверяет правильность флага или ответа на подзадачи.
Andy K. Zhang et al, Stanford, 2024
Статья, сайт
LLM имеют хороший потенциал в offensive security – как в роли помощника, как в случае с PentestGPT , так и в роли автономного пентестера, что демонстрирует PentAGI. Для того, чтобы определить, насколько этот потенциал реализован, нужны, как это водится, бенчмарки. Мы разбирали несколько таких бенчей – CyberSecEval и 3CB. Сегодня посмотрим на еще один бенчмарк, а именно CyBench от исследователей из Стэнфорда.
Для построения бенчмарка исследователи используют 40 задач, которые давались участникам 4 CTF-соревнований формата Jeopardy (HTB Cyber Apocalypse 2024, SekaiCTF, Glacier, HKCert), проходивших в 2022-2024 годах. Задачи покрывают 6 категорий: криптографию, безопасность веб-приложений, реверс, форензику, эксплуатацию уязвимостей и «прочее». Используя статистику по тому, сколько времени потребовалось на решение первой команде, исследователи сортируют задачи по сложности. Поскольку большинство задач оказываются LLM не под силу, они разбиваются на подзадачи а ля HackTheBox Guided Mode. Задачи включают в себя описание, локальные файлы, к которым у LLM есть доступ, докер-образы для запуска агента на базе Kali Linux и удаленных сетевых сервисов для сценария задачи, и оценщика, который проверяет правильность флага или ответа на подзадачи.
group-telegram.com/llmsecurity/494
Create:
Last Update:
Last Update:
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models
Andy K. Zhang et al, Stanford, 2024
Статья, сайт
LLM имеют хороший потенциал в offensive security – как в роли помощника, как в случае с PentestGPT , так и в роли автономного пентестера, что демонстрирует PentAGI. Для того, чтобы определить, насколько этот потенциал реализован, нужны, как это водится, бенчмарки. Мы разбирали несколько таких бенчей – CyberSecEval и 3CB. Сегодня посмотрим на еще один бенчмарк, а именно CyBench от исследователей из Стэнфорда.
Для построения бенчмарка исследователи используют 40 задач, которые давались участникам 4 CTF-соревнований формата Jeopardy (HTB Cyber Apocalypse 2024, SekaiCTF, Glacier, HKCert), проходивших в 2022-2024 годах. Задачи покрывают 6 категорий: криптографию, безопасность веб-приложений, реверс, форензику, эксплуатацию уязвимостей и «прочее». Используя статистику по тому, сколько времени потребовалось на решение первой команде, исследователи сортируют задачи по сложности. Поскольку большинство задач оказываются LLM не под силу, они разбиваются на подзадачи а ля HackTheBox Guided Mode. Задачи включают в себя описание, локальные файлы, к которым у LLM есть доступ, докер-образы для запуска агента на базе Kali Linux и удаленных сетевых сервисов для сценария задачи, и оценщика, который проверяет правильность флага или ответа на подзадачи.
Andy K. Zhang et al, Stanford, 2024
Статья, сайт
LLM имеют хороший потенциал в offensive security – как в роли помощника, как в случае с PentestGPT , так и в роли автономного пентестера, что демонстрирует PentAGI. Для того, чтобы определить, насколько этот потенциал реализован, нужны, как это водится, бенчмарки. Мы разбирали несколько таких бенчей – CyberSecEval и 3CB. Сегодня посмотрим на еще один бенчмарк, а именно CyBench от исследователей из Стэнфорда.
Для построения бенчмарка исследователи используют 40 задач, которые давались участникам 4 CTF-соревнований формата Jeopardy (HTB Cyber Apocalypse 2024, SekaiCTF, Glacier, HKCert), проходивших в 2022-2024 годах. Задачи покрывают 6 категорий: криптографию, безопасность веб-приложений, реверс, форензику, эксплуатацию уязвимостей и «прочее». Используя статистику по тому, сколько времени потребовалось на решение первой команде, исследователи сортируют задачи по сложности. Поскольку большинство задач оказываются LLM не под силу, они разбиваются на подзадачи а ля HackTheBox Guided Mode. Задачи включают в себя описание, локальные файлы, к которым у LLM есть доступ, докер-образы для запуска агента на базе Kali Linux и удаленных сетевых сервисов для сценария задачи, и оценщика, который проверяет правильность флага или ответа на подзадачи.
BY llm security и каланы


Share with your friend now:
group-telegram.com/llmsecurity/494