🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
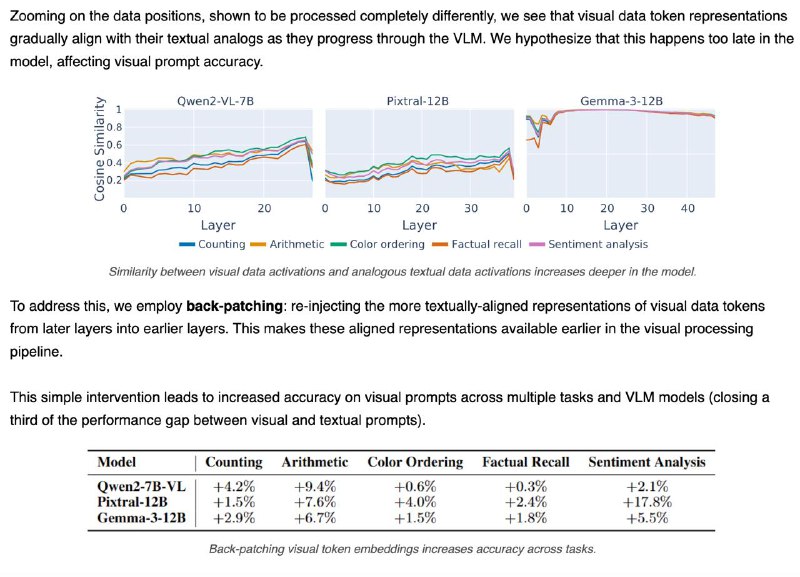
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
On Telegram’s website, it says that Pavel Durov “supports Telegram financially and ideologically while Nikolai (Duvov)’s input is technological.” Currently, the Telegram team is based in Dubai, having moved around from Berlin, London and Singapore after departing Russia. Meanwhile, the company which owns Telegram is registered in the British Virgin Islands. "He has kind of an old-school cyber-libertarian world view where technology is there to set you free," Maréchal said. "For Telegram, accountability has always been a problem, which is why it was so popular even before the full-scale war with far-right extremists and terrorists from all over the world," she told AFP from her safe house outside the Ukrainian capital. Continuing its crackdown against entities allegedly involved in a front-running scam using messaging app Telegram, Sebi on Thursday carried out search and seizure operations at the premises of eight entities in multiple locations across the country. Telegram has gained a reputation as the “secure” communications app in the post-Soviet states, but whenever you make choices about your digital security, it’s important to start by asking yourself, “What exactly am I securing? And who am I securing it from?” These questions should inform your decisions about whether you are using the right tool or platform for your digital security needs. Telegram is certainly not the most secure messaging app on the market right now. Its security model requires users to place a great deal of trust in Telegram’s ability to protect user data. For some users, this may be good enough for now. For others, it may be wiser to move to a different platform for certain kinds of high-risk communications.
from us