Forwarded from All about AI, Web 3.0, BCI
Berkeley developed a streaming “brain-to-voice” neuroprosthesis which restores naturalistic, fluent, intelligible speech to a person who has paralysis.
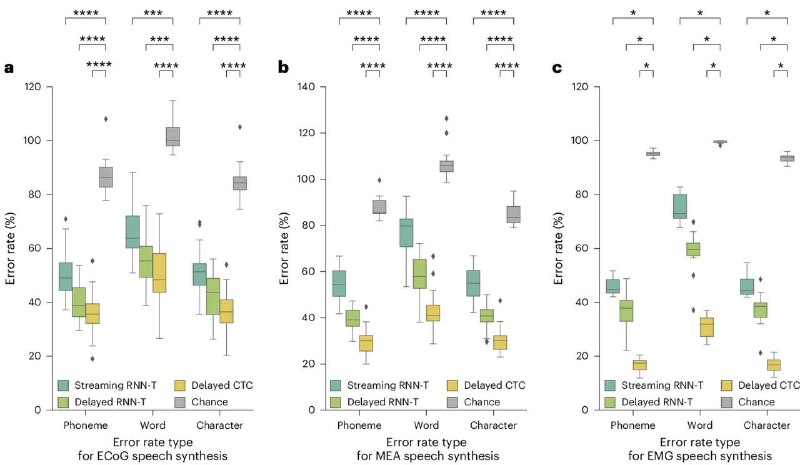
Researchers adopted streaming transducer techniques similar to methods used by popular ASR methods like Siri or Alexa, and repurposed them for personalized brain-to-voice synthesis.
This approach resulted in significant improvements in the decoding speed of the brain-to-voice neuroprosthesis compared to prior approaches with longer delays.
Researchers also show continuous long-form brain-to-voice synthesis, robustness to model-generated auditory feedback, and out-of-vocabulary brain-to-voice synthesis.
Researchers adopted streaming transducer techniques similar to methods used by popular ASR methods like Siri or Alexa, and repurposed them for personalized brain-to-voice synthesis.
This approach resulted in significant improvements in the decoding speed of the brain-to-voice neuroprosthesis compared to prior approaches with longer delays.
Researchers also show continuous long-form brain-to-voice synthesis, robustness to model-generated auditory feedback, and out-of-vocabulary brain-to-voice synthesis.
group-telegram.com/neural_cell/267
Create:
Last Update:
Last Update:
Berkeley developed a streaming “brain-to-voice” neuroprosthesis which restores naturalistic, fluent, intelligible speech to a person who has paralysis.
Researchers adopted streaming transducer techniques similar to methods used by popular ASR methods like Siri or Alexa, and repurposed them for personalized brain-to-voice synthesis.
This approach resulted in significant improvements in the decoding speed of the brain-to-voice neuroprosthesis compared to prior approaches with longer delays.
Researchers also show continuous long-form brain-to-voice synthesis, robustness to model-generated auditory feedback, and out-of-vocabulary brain-to-voice synthesis.
Researchers adopted streaming transducer techniques similar to methods used by popular ASR methods like Siri or Alexa, and repurposed them for personalized brain-to-voice synthesis.
This approach resulted in significant improvements in the decoding speed of the brain-to-voice neuroprosthesis compared to prior approaches with longer delays.
Researchers also show continuous long-form brain-to-voice synthesis, robustness to model-generated auditory feedback, and out-of-vocabulary brain-to-voice synthesis.
BY the last neural cell


Share with your friend now:
group-telegram.com/neural_cell/267