
Токенизация изображений: от сверток к трансформерам
Долгие годы для представления картинок в сжатом виде использовали разные вариации автоэнкодеров. Чтобы получить дискретное представление (то есть набор конкретных "символов" вместо непрерывных значений), применяли VQ-VAE — это по сути обычный авто энкодер, но с vector-quantized слоем посередине.
Но в середине прошлого года трансформеры добрались и до этой области.
Главная идея состоит в том, чтобы:
1. Заменить свертки на трансформеры
2. Убрать 2D-сетку и представлять картинку как просто последовательность токенов (без явной пространственной привязки для каждого токена)
TiTok: An Image is Worth 32 Tokens
link: https://arxiv.org/abs/2406.07550
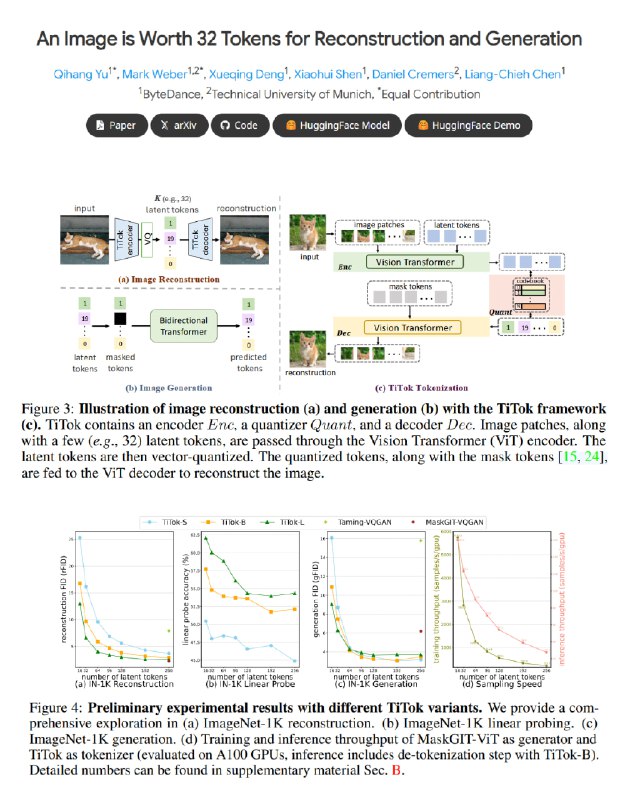
Главная фишка — всего 32/64/128 токенов достаточно для представления целого изображения!
Как это работает:
- Энкодер и декодер — оба на основе Vision Transformer
- К патчам изображения присоединяются специальные registers токены
- Эти register токены квантуются (превращаются в вектора из словаря)
- эти токены подаются на вход декодеру вместе с [MASK] токенами
Интересно, что эта архитектура похожа на MAE (Masked Autoencoder), только с акцентом на компактное представление.
Для генерации используется maskGIT, и получаются довольно качественные изображения. При этом никакой диффузии — всё быстро и понятно.
FlexTok: гибкая длина токенов
link: https://arxiv.org/abs/2502.13967
FlexTok берет идею TiTok, но вместо работы с оригинальным изображением начинает с VAE-latents:
- Добавляет flow matching для декодера
- Использует регистры как условие для модели
- Применяет nested dropout для регистров, чтобы декодер мог работать с разным числом токенов (от 1 до 256)
- use FSQ квантизацию как COSMOS by NVIDIA
FlowMO: прямой подход
link: https://www.arxiv.org/abs/2503.11056
FlowMO - Это TiTok но с диффузией для декодера.
- Работаем напрямую с картинками
- Используем все токены для реконструкции
- тоже диффузионный декодер
Сравнение моделей
TiTok работает с исходными изображениями, не использует диффузионный декодер, применяет дистилляцию через MagViT VQVAE и стандартную квантизацию.
FlexTok работает с VAE-латентами, использует диффузионный декодер, обходится без дистилляции и применяет FSQ квантизацию с 64k векторов.
FlowMO работает с исходными изображениями, использует диффузионный декодер, обходится без дистилляции и применяет LFQ (sign) квантизацию со сложными функциями потерь.
Мои мысли о развитии этих подходов
Объединить MAE с TiTok:
- используем маскирование входного изображения, как в MAE. По идеи ддолжно ускорить работу и сделать токены ещё более информативными.
Объединить FlexTok, TiTok и MAE в один универсальный экстрактор признаков:
- Случайное маскирование для входного изображения (0, 0.25, 0.5, 0.75, 1)
- Nested dropout для латентов (как в FlexTok)
- Маскирование токенов для декодера: 0.5, 0.75, 1 как это делают уже в maskGIT
- Плюс сюда же ещё добавить REPA
Долгие годы для представления картинок в сжатом виде использовали разные вариации автоэнкодеров. Чтобы получить дискретное представление (то есть набор конкретных "символов" вместо непрерывных значений), применяли VQ-VAE — это по сути обычный авто энкодер, но с vector-quantized слоем посередине.
Но в середине прошлого года трансформеры добрались и до этой области.
Главная идея состоит в том, чтобы:
1. Заменить свертки на трансформеры
2. Убрать 2D-сетку и представлять картинку как просто последовательность токенов (без явной пространственной привязки для каждого токена)
TiTok: An Image is Worth 32 Tokens
link: https://arxiv.org/abs/2406.07550
Главная фишка — всего 32/64/128 токенов достаточно для представления целого изображения!
Как это работает:
- Энкодер и декодер — оба на основе Vision Transformer
- К патчам изображения присоединяются специальные registers токены
- Эти register токены квантуются (превращаются в вектора из словаря)
- эти токены подаются на вход декодеру вместе с [MASK] токенами
Интересно, что эта архитектура похожа на MAE (Masked Autoencoder), только с акцентом на компактное представление.
Для генерации используется maskGIT, и получаются довольно качественные изображения. При этом никакой диффузии — всё быстро и понятно.
FlexTok: гибкая длина токенов
link: https://arxiv.org/abs/2502.13967
FlexTok берет идею TiTok, но вместо работы с оригинальным изображением начинает с VAE-latents:
- Добавляет flow matching для декодера
- Использует регистры как условие для модели
- Применяет nested dropout для регистров, чтобы декодер мог работать с разным числом токенов (от 1 до 256)
- use FSQ квантизацию как COSMOS by NVIDIA
FlowMO: прямой подход
link: https://www.arxiv.org/abs/2503.11056
FlowMO - Это TiTok но с диффузией для декодера.
- Работаем напрямую с картинками
- Используем все токены для реконструкции
- тоже диффузионный декодер
Сравнение моделей
TiTok работает с исходными изображениями, не использует диффузионный декодер, применяет дистилляцию через MagViT VQVAE и стандартную квантизацию.
FlexTok работает с VAE-латентами, использует диффузионный декодер, обходится без дистилляции и применяет FSQ квантизацию с 64k векторов.
FlowMO работает с исходными изображениями, использует диффузионный декодер, обходится без дистилляции и применяет LFQ (sign) квантизацию со сложными функциями потерь.
Мои мысли о развитии этих подходов
Объединить MAE с TiTok:
- используем маскирование входного изображения, как в MAE. По идеи ддолжно ускорить работу и сделать токены ещё более информативными.
Объединить FlexTok, TiTok и MAE в один универсальный экстрактор признаков:
- Случайное маскирование для входного изображения (0, 0.25, 0.5, 0.75, 1)
- Nested dropout для латентов (как в FlexTok)
- Маскирование токенов для декодера: 0.5, 0.75, 1 как это делают уже в maskGIT
- Плюс сюда же ещё добавить REPA
group-telegram.com/neural_cell/274
Create:
Last Update:
Last Update:
Токенизация изображений: от сверток к трансформерам
Долгие годы для представления картинок в сжатом виде использовали разные вариации автоэнкодеров. Чтобы получить дискретное представление (то есть набор конкретных "символов" вместо непрерывных значений), применяли VQ-VAE — это по сути обычный авто энкодер, но с vector-quantized слоем посередине.
Но в середине прошлого года трансформеры добрались и до этой области.
Главная идея состоит в том, чтобы:
1. Заменить свертки на трансформеры
2. Убрать 2D-сетку и представлять картинку как просто последовательность токенов (без явной пространственной привязки для каждого токена)
TiTok: An Image is Worth 32 Tokens
link: https://arxiv.org/abs/2406.07550
Главная фишка — всего 32/64/128 токенов достаточно для представления целого изображения!
Как это работает:
- Энкодер и декодер — оба на основе Vision Transformer
- К патчам изображения присоединяются специальные registers токены
- Эти register токены квантуются (превращаются в вектора из словаря)
- эти токены подаются на вход декодеру вместе с [MASK] токенами
Интересно, что эта архитектура похожа на MAE (Masked Autoencoder), только с акцентом на компактное представление.
Для генерации используется maskGIT, и получаются довольно качественные изображения. При этом никакой диффузии — всё быстро и понятно.
FlexTok: гибкая длина токенов
link: https://arxiv.org/abs/2502.13967
FlexTok берет идею TiTok, но вместо работы с оригинальным изображением начинает с VAE-latents:
- Добавляет flow matching для декодера
- Использует регистры как условие для модели
- Применяет nested dropout для регистров, чтобы декодер мог работать с разным числом токенов (от 1 до 256)
- use FSQ квантизацию как COSMOS by NVIDIA
FlowMO: прямой подход
link: https://www.arxiv.org/abs/2503.11056
FlowMO - Это TiTok но с диффузией для декодера.
- Работаем напрямую с картинками
- Используем все токены для реконструкции
- тоже диффузионный декодер
Сравнение моделей
TiTok работает с исходными изображениями, не использует диффузионный декодер, применяет дистилляцию через MagViT VQVAE и стандартную квантизацию.
FlexTok работает с VAE-латентами, использует диффузионный декодер, обходится без дистилляции и применяет FSQ квантизацию с 64k векторов.
FlowMO работает с исходными изображениями, использует диффузионный декодер, обходится без дистилляции и применяет LFQ (sign) квантизацию со сложными функциями потерь.
Мои мысли о развитии этих подходов
Объединить MAE с TiTok:
- используем маскирование входного изображения, как в MAE. По идеи ддолжно ускорить работу и сделать токены ещё более информативными.
Объединить FlexTok, TiTok и MAE в один универсальный экстрактор признаков:
- Случайное маскирование для входного изображения (0, 0.25, 0.5, 0.75, 1)
- Nested dropout для латентов (как в FlexTok)
- Маскирование токенов для декодера: 0.5, 0.75, 1 как это делают уже в maskGIT
- Плюс сюда же ещё добавить REPA
Долгие годы для представления картинок в сжатом виде использовали разные вариации автоэнкодеров. Чтобы получить дискретное представление (то есть набор конкретных "символов" вместо непрерывных значений), применяли VQ-VAE — это по сути обычный авто энкодер, но с vector-quantized слоем посередине.
Но в середине прошлого года трансформеры добрались и до этой области.
Главная идея состоит в том, чтобы:
1. Заменить свертки на трансформеры
2. Убрать 2D-сетку и представлять картинку как просто последовательность токенов (без явной пространственной привязки для каждого токена)
TiTok: An Image is Worth 32 Tokens
link: https://arxiv.org/abs/2406.07550
Главная фишка — всего 32/64/128 токенов достаточно для представления целого изображения!
Как это работает:
- Энкодер и декодер — оба на основе Vision Transformer
- К патчам изображения присоединяются специальные registers токены
- Эти register токены квантуются (превращаются в вектора из словаря)
- эти токены подаются на вход декодеру вместе с [MASK] токенами
Интересно, что эта архитектура похожа на MAE (Masked Autoencoder), только с акцентом на компактное представление.
Для генерации используется maskGIT, и получаются довольно качественные изображения. При этом никакой диффузии — всё быстро и понятно.
FlexTok: гибкая длина токенов
link: https://arxiv.org/abs/2502.13967
FlexTok берет идею TiTok, но вместо работы с оригинальным изображением начинает с VAE-latents:
- Добавляет flow matching для декодера
- Использует регистры как условие для модели
- Применяет nested dropout для регистров, чтобы декодер мог работать с разным числом токенов (от 1 до 256)
- use FSQ квантизацию как COSMOS by NVIDIA
FlowMO: прямой подход
link: https://www.arxiv.org/abs/2503.11056
FlowMO - Это TiTok но с диффузией для декодера.
- Работаем напрямую с картинками
- Используем все токены для реконструкции
- тоже диффузионный декодер
Сравнение моделей
TiTok работает с исходными изображениями, не использует диффузионный декодер, применяет дистилляцию через MagViT VQVAE и стандартную квантизацию.
FlexTok работает с VAE-латентами, использует диффузионный декодер, обходится без дистилляции и применяет FSQ квантизацию с 64k векторов.
FlowMO работает с исходными изображениями, использует диффузионный декодер, обходится без дистилляции и применяет LFQ (sign) квантизацию со сложными функциями потерь.
Мои мысли о развитии этих подходов
Объединить MAE с TiTok:
- используем маскирование входного изображения, как в MAE. По идеи ддолжно ускорить работу и сделать токены ещё более информативными.
Объединить FlexTok, TiTok и MAE в один универсальный экстрактор признаков:
- Случайное маскирование для входного изображения (0, 0.25, 0.5, 0.75, 1)
- Nested dropout для латентов (как в FlexTok)
- Маскирование токенов для декодера: 0.5, 0.75, 1 как это делают уже в maskGIT
- Плюс сюда же ещё добавить REPA
BY the last neural cell


Share with your friend now:
group-telegram.com/neural_cell/274