
Как выглядит подход Google для того, чтобы защитить ваших агентов и что в нём не так.
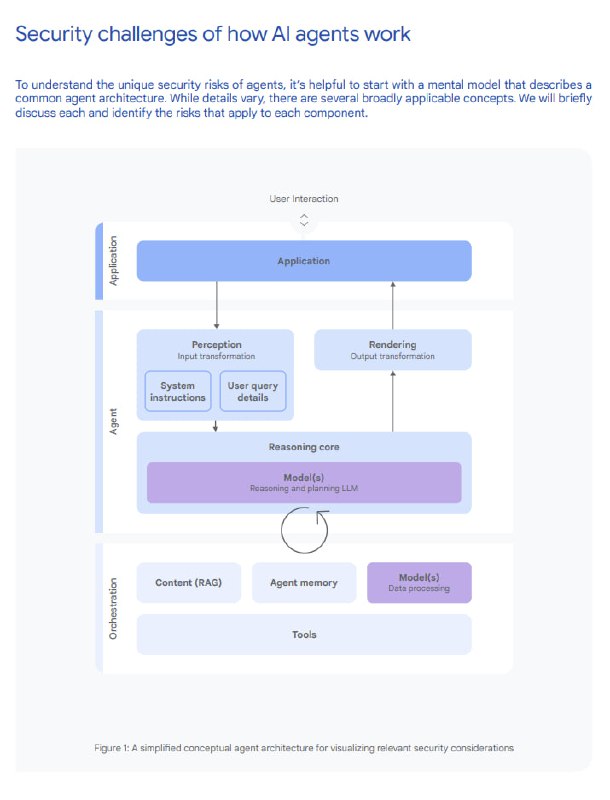
Ранее в мае, Google выкатили фреймворк для безопасности AI-агентов. Он основан на трёх ключевых принципах: чётко определённый контроль человеком, ограничение полномочий агентов и наблюдаемость действий агента и то, как он планирует задачи.
Кажется, что фреймворк в чём-то описывает очень стандартную для агентов историю по защите. Но я не стал писать о нём сюда, до одного момента - сегодня вышла статья Simon Willison, который детально провёл его анализ и осветил важные моменты, которые мы сейчас и рассмотрим.
Уже в начале статьи Willison выявляет принципиальное различие в подходах. Он отмечает, что Google выбрала менее категоричный путь по сравнению с другими исследователями. Если предыдущие работы четко утверждали, что AI-агент, получивший плохие данные, должен быть полностью ограничен в возможности выполнения значимых действий, то Google пытается найти компромисс.
Willison видит в этом фундаментальную проблему. Он считает, что Google обходит критически важные вопросы вместо их прямого решения. Фреймворк предлагает решения, основанные на надежном различении доверенных команд пользователя от потенциально опасных контекстных данных из других источников.
Willison говорит, что: Это неправильно ! Так как однозначное разделение невозможно.
Он подчеркивает, что вопросы/задачи формулируются пользователями таким образом, как будто решение существует, но в действительности такого решения нет.
Коротко о его мнении по поводу трёх принципов:
1. Человеческий контроль: Сам Willison не даёт оценки первому принципу, но отмечает два ключевых момента: отслеживание того, какой пользователь контролирует агента, и добавление этапа подтверждения человеком для критических действий.
2. Принцип с ограничением полномочий агентов вызывает скептицизм. Он отмечает, что предложение Google слишком изощрено, так как требует буквально динамически изменяемых полномочий для агентов – сложно представить как это будет работать на практике. А ключевая проблема тут в том, что реализация таких guardrails потребует дополнительных моделей, которые будут корректировать разрешения исходя из задачи. Это кажется рискованным, так как промпт-инъекции могут повлиять на такие решения. Даже Google признает ограничения – стратегии недетерминированны и не могут предоставить абсолютные гарантии, что модели все еще могут быть обмануты новыми атаками, и что их режимы отказа могут быть непредсказуемыми
3. Willison согласен с тем, что должна быть наблюдаемость, как фундаментальное требование ИБ.
Риски, связанные с рендерингом вывода и меры которые описаны в документе – это большой + по его мнению, да и в целом, если приложение рендерит без санитизации или экранирования, то могут возникать разные уязвимости типа XSS или утечка информации.
Важной ценностью самого фреймворка является подход “defense-in-depth”, который комбинирует классические меры ИБ с reasoning-based механизмами защиты. Документ признает, что ни один подход в отдельности не может обеспечить абсолютную безопасность AI-агентов, поэтому подходов много!
https://simonwillison.net/2025/Jun/15/ai-agent-security/
Ранее в мае, Google выкатили фреймворк для безопасности AI-агентов. Он основан на трёх ключевых принципах: чётко определённый контроль человеком, ограничение полномочий агентов и наблюдаемость действий агента и то, как он планирует задачи.
Кажется, что фреймворк в чём-то описывает очень стандартную для агентов историю по защите. Но я не стал писать о нём сюда, до одного момента - сегодня вышла статья Simon Willison, который детально провёл его анализ и осветил важные моменты, которые мы сейчас и рассмотрим.
Уже в начале статьи Willison выявляет принципиальное различие в подходах. Он отмечает, что Google выбрала менее категоричный путь по сравнению с другими исследователями. Если предыдущие работы четко утверждали, что AI-агент, получивший плохие данные, должен быть полностью ограничен в возможности выполнения значимых действий, то Google пытается найти компромисс.
Willison видит в этом фундаментальную проблему. Он считает, что Google обходит критически важные вопросы вместо их прямого решения. Фреймворк предлагает решения, основанные на надежном различении доверенных команд пользователя от потенциально опасных контекстных данных из других источников.
Willison говорит, что: Это неправильно ! Так как однозначное разделение невозможно.
Он подчеркивает, что вопросы/задачи формулируются пользователями таким образом, как будто решение существует, но в действительности такого решения нет.
Коротко о его мнении по поводу трёх принципов:
1. Человеческий контроль: Сам Willison не даёт оценки первому принципу, но отмечает два ключевых момента: отслеживание того, какой пользователь контролирует агента, и добавление этапа подтверждения человеком для критических действий.
2. Принцип с ограничением полномочий агентов вызывает скептицизм. Он отмечает, что предложение Google слишком изощрено, так как требует буквально динамически изменяемых полномочий для агентов – сложно представить как это будет работать на практике. А ключевая проблема тут в том, что реализация таких guardrails потребует дополнительных моделей, которые будут корректировать разрешения исходя из задачи. Это кажется рискованным, так как промпт-инъекции могут повлиять на такие решения. Даже Google признает ограничения – стратегии недетерминированны и не могут предоставить абсолютные гарантии, что модели все еще могут быть обмануты новыми атаками, и что их режимы отказа могут быть непредсказуемыми
3. Willison согласен с тем, что должна быть наблюдаемость, как фундаментальное требование ИБ.
Риски, связанные с рендерингом вывода и меры которые описаны в документе – это большой + по его мнению, да и в целом, если приложение рендерит без санитизации или экранирования, то могут возникать разные уязвимости типа XSS или утечка информации.
Важной ценностью самого фреймворка является подход “defense-in-depth”, который комбинирует классические меры ИБ с reasoning-based механизмами защиты. Документ признает, что ни один подход в отдельности не может обеспечить абсолютную безопасность AI-агентов, поэтому подходов много!
https://simonwillison.net/2025/Jun/15/ai-agent-security/
group-telegram.com/pwnai/929
Create:
Last Update:
Last Update:
Как выглядит подход Google для того, чтобы защитить ваших агентов и что в нём не так.
Ранее в мае, Google выкатили фреймворк для безопасности AI-агентов. Он основан на трёх ключевых принципах: чётко определённый контроль человеком, ограничение полномочий агентов и наблюдаемость действий агента и то, как он планирует задачи.
Кажется, что фреймворк в чём-то описывает очень стандартную для агентов историю по защите. Но я не стал писать о нём сюда, до одного момента - сегодня вышла статья Simon Willison, который детально провёл его анализ и осветил важные моменты, которые мы сейчас и рассмотрим.
Уже в начале статьи Willison выявляет принципиальное различие в подходах. Он отмечает, что Google выбрала менее категоричный путь по сравнению с другими исследователями. Если предыдущие работы четко утверждали, что AI-агент, получивший плохие данные, должен быть полностью ограничен в возможности выполнения значимых действий, то Google пытается найти компромисс.
Willison видит в этом фундаментальную проблему. Он считает, что Google обходит критически важные вопросы вместо их прямого решения. Фреймворк предлагает решения, основанные на надежном различении доверенных команд пользователя от потенциально опасных контекстных данных из других источников.
Willison говорит, что: Это неправильно ! Так как однозначное разделение невозможно.
Он подчеркивает, что вопросы/задачи формулируются пользователями таким образом, как будто решение существует, но в действительности такого решения нет.
Коротко о его мнении по поводу трёх принципов:
1. Человеческий контроль: Сам Willison не даёт оценки первому принципу, но отмечает два ключевых момента: отслеживание того, какой пользователь контролирует агента, и добавление этапа подтверждения человеком для критических действий.
2. Принцип с ограничением полномочий агентов вызывает скептицизм. Он отмечает, что предложение Google слишком изощрено, так как требует буквально динамически изменяемых полномочий для агентов – сложно представить как это будет работать на практике. А ключевая проблема тут в том, что реализация таких guardrails потребует дополнительных моделей, которые будут корректировать разрешения исходя из задачи. Это кажется рискованным, так как промпт-инъекции могут повлиять на такие решения. Даже Google признает ограничения – стратегии недетерминированны и не могут предоставить абсолютные гарантии, что модели все еще могут быть обмануты новыми атаками, и что их режимы отказа могут быть непредсказуемыми
3. Willison согласен с тем, что должна быть наблюдаемость, как фундаментальное требование ИБ.
Риски, связанные с рендерингом вывода и меры которые описаны в документе – это большой + по его мнению, да и в целом, если приложение рендерит без санитизации или экранирования, то могут возникать разные уязвимости типа XSS или утечка информации.
Важной ценностью самого фреймворка является подход “defense-in-depth”, который комбинирует классические меры ИБ с reasoning-based механизмами защиты. Документ признает, что ни один подход в отдельности не может обеспечить абсолютную безопасность AI-агентов, поэтому подходов много!
https://simonwillison.net/2025/Jun/15/ai-agent-security/
Ранее в мае, Google выкатили фреймворк для безопасности AI-агентов. Он основан на трёх ключевых принципах: чётко определённый контроль человеком, ограничение полномочий агентов и наблюдаемость действий агента и то, как он планирует задачи.
Кажется, что фреймворк в чём-то описывает очень стандартную для агентов историю по защите. Но я не стал писать о нём сюда, до одного момента - сегодня вышла статья Simon Willison, который детально провёл его анализ и осветил важные моменты, которые мы сейчас и рассмотрим.
Уже в начале статьи Willison выявляет принципиальное различие в подходах. Он отмечает, что Google выбрала менее категоричный путь по сравнению с другими исследователями. Если предыдущие работы четко утверждали, что AI-агент, получивший плохие данные, должен быть полностью ограничен в возможности выполнения значимых действий, то Google пытается найти компромисс.
Willison видит в этом фундаментальную проблему. Он считает, что Google обходит критически важные вопросы вместо их прямого решения. Фреймворк предлагает решения, основанные на надежном различении доверенных команд пользователя от потенциально опасных контекстных данных из других источников.
Willison говорит, что: Это неправильно ! Так как однозначное разделение невозможно.
Он подчеркивает, что вопросы/задачи формулируются пользователями таким образом, как будто решение существует, но в действительности такого решения нет.
Коротко о его мнении по поводу трёх принципов:
1. Человеческий контроль: Сам Willison не даёт оценки первому принципу, но отмечает два ключевых момента: отслеживание того, какой пользователь контролирует агента, и добавление этапа подтверждения человеком для критических действий.
2. Принцип с ограничением полномочий агентов вызывает скептицизм. Он отмечает, что предложение Google слишком изощрено, так как требует буквально динамически изменяемых полномочий для агентов – сложно представить как это будет работать на практике. А ключевая проблема тут в том, что реализация таких guardrails потребует дополнительных моделей, которые будут корректировать разрешения исходя из задачи. Это кажется рискованным, так как промпт-инъекции могут повлиять на такие решения. Даже Google признает ограничения – стратегии недетерминированны и не могут предоставить абсолютные гарантии, что модели все еще могут быть обмануты новыми атаками, и что их режимы отказа могут быть непредсказуемыми
3. Willison согласен с тем, что должна быть наблюдаемость, как фундаментальное требование ИБ.
Риски, связанные с рендерингом вывода и меры которые описаны в документе – это большой + по его мнению, да и в целом, если приложение рендерит без санитизации или экранирования, то могут возникать разные уязвимости типа XSS или утечка информации.
Важной ценностью самого фреймворка является подход “defense-in-depth”, который комбинирует классические меры ИБ с reasoning-based механизмами защиты. Документ признает, что ни один подход в отдельности не может обеспечить абсолютную безопасность AI-агентов, поэтому подходов много!
https://simonwillison.net/2025/Jun/15/ai-agent-security/
BY PWN AI


Share with your friend now:
group-telegram.com/pwnai/929