RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
#rag
Сегодня продолжу развивать тему RAG, поэтому подготовил для вас разбор свежей статьи RAPTOR. Этот подход устраняет проблему, когда LLM задают тематические вопросы, требующие полного знания целого документа или даже нескольких. Примером такого запроса может быть "Как именно князь Гвидон достиг своего могущества?". Любая система RAG извлечет множество релевантных фрагментов текста по данному запросу, однако они не дадут полной картины, потому что для этого нужно знать все содержание книги. И мы получаем проблему - чем больше фрагментов текста вы включаете в запрос, тем меньше вам нужен RAG.
Что же делает RAPTOR?🦖
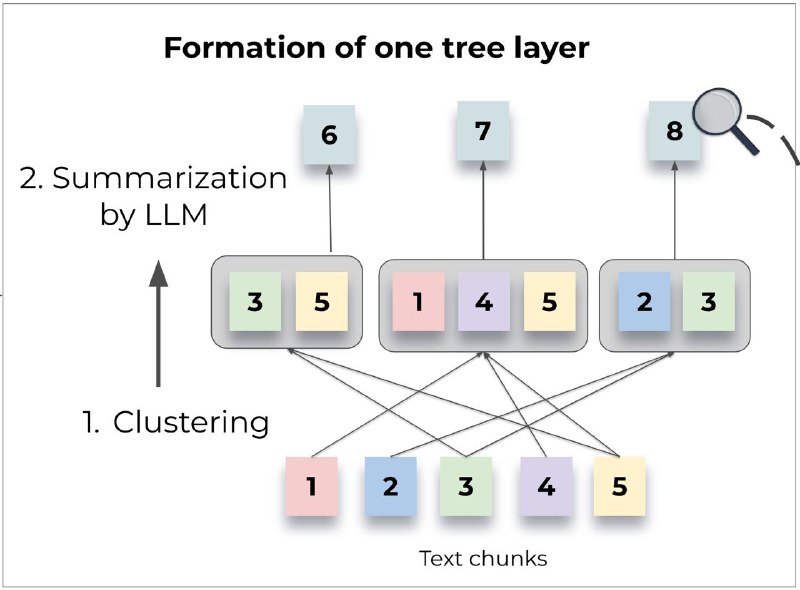
Вместо разделения документов на маленькие фрагменты и сохранения их в векторную БД для последующего извлечения, RAPTOR сначала их кластеризует, а после суммаризует каждый кластер с помощью LLM. Он повторяет этот процесс итерационно, пока не остается один, финальный фрагмент текста, в котором содержится вся информация документа. Все это извлекается в общих чертах с готовой суммаризированной информацией, а если необходимы факты, то можно опуститься на слой ниже и извлечь более детальное summary.
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
#rag
Сегодня продолжу развивать тему RAG, поэтому подготовил для вас разбор свежей статьи RAPTOR. Этот подход устраняет проблему, когда LLM задают тематические вопросы, требующие полного знания целого документа или даже нескольких. Примером такого запроса может быть "Как именно князь Гвидон достиг своего могущества?". Любая система RAG извлечет множество релевантных фрагментов текста по данному запросу, однако они не дадут полной картины, потому что для этого нужно знать все содержание книги. И мы получаем проблему - чем больше фрагментов текста вы включаете в запрос, тем меньше вам нужен RAG.
Что же делает RAPTOR?🦖
Вместо разделения документов на маленькие фрагменты и сохранения их в векторную БД для последующего извлечения, RAPTOR сначала их кластеризует, а после суммаризует каждый кластер с помощью LLM. Он повторяет этот процесс итерационно, пока не остается один, финальный фрагмент текста, в котором содержится вся информация документа. Все это извлекается в общих чертах с готовой суммаризированной информацией, а если необходимы факты, то можно опуститься на слой ниже и извлечь более детальное summary.
Telegram Messenger Blocks Navalny Bot During Russian Election Just days after Russia invaded Ukraine, Durov wrote that Telegram was "increasingly becoming a source of unverified information," and he worried about the app being used to "incite ethnic hatred." There was another possible development: Reuters also reported that Ukraine said that Belarus could soon join the invasion of Ukraine. However, the AFP, citing a Pentagon official, said the U.S. hasn’t yet seen evidence that Belarusian troops are in Ukraine. That hurt tech stocks. For the past few weeks, the 10-year yield has traded between 1.72% and 2%, as traders moved into the bond for safety when Russia headlines were ugly—and out of it when headlines improved. Now, the yield is touching its pandemic-era high. If the yield breaks above that level, that could signal that it’s on a sustainable path higher. Higher long-dated bond yields make future profits less valuable—and many tech companies are valued on the basis of profits forecast for many years in the future. The perpetrators use various names to carry out the investment scams. They may also impersonate or clone licensed capital market intermediaries by using the names, logos, credentials, websites and other details of the legitimate entities to promote the illegal schemes.
from sa