🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
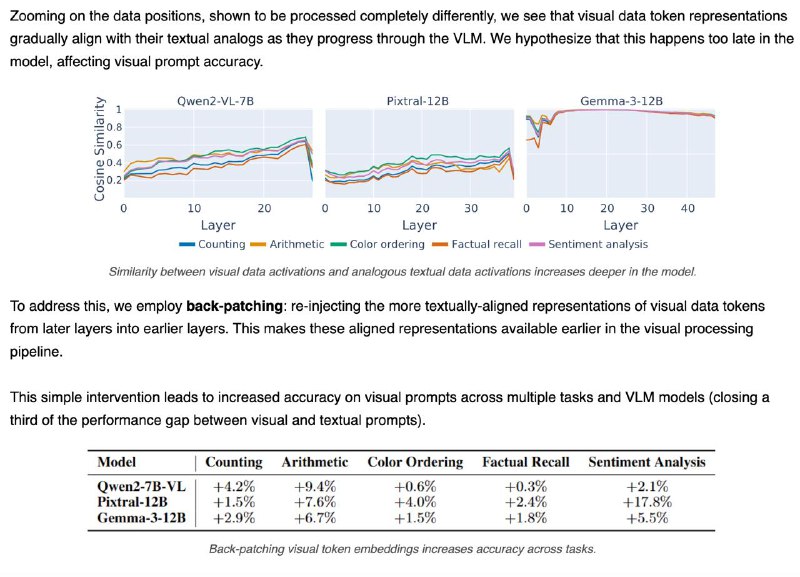
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
"Russians are really disconnected from the reality of what happening to their country," Andrey said. "So Telegram has become essential for understanding what's going on to the Russian-speaking world." On February 27th, Durov posted that Channels were becoming a source of unverified information and that the company lacks the ability to check on their veracity. He urged users to be mistrustful of the things shared on Channels, and initially threatened to block the feature in the countries involved for the length of the war, saying that he didn’t want Telegram to be used to aggravate conflict or incite ethnic hatred. He did, however, walk back this plan when it became clear that they had also become a vital communications tool for Ukrainian officials and citizens to help coordinate their resistance and evacuations. Messages are not fully encrypted by default. That means the company could, in theory, access the content of the messages, or be forced to hand over the data at the request of a government. Some people used the platform to organize ahead of the storming of the U.S. Capitol in January 2021, and last month Senator Mark Warner sent a letter to Durov urging him to curb Russian information operations on Telegram. At the start of 2018, the company attempted to launch an Initial Coin Offering (ICO) which would enable it to enable payments (and earn the cash that comes from doing so). The initial signals were promising, especially given Telegram’s user base is already fairly crypto-savvy. It raised an initial tranche of cash – worth more than a billion dollars – to help develop the coin before opening sales to the public. Unfortunately, third-party sales of coins bought in those initial fundraising rounds raised the ire of the SEC, which brought the hammer down on the whole operation. In 2020, officials ordered Telegram to pay a fine of $18.5 million and hand back much of the cash that it had raised.
from sa