group-telegram.com/datainthecity/264
Last Update:
#PhD #humanmobility
Делая PhD, основанный на анализе GPS-локаций людей, я начала задаваться вопросами, которые раньше, при работе с коммерческими данными, не приходили мне в голову:
🔹 Существуют ли стандарты обработки GPS-сигналов для изучения человеческой мобильности?
🔹 Какие ограничения по приватности нужно учитывать при визуализации? Можно ли, например, добавлять на карту дом и работу одного человека?
🔹 Какие валидационные тесты помогут сделать так, чтобы "тебе поверили"?
🔹 Как сделать код полезным для тех, у кого нет доступа к моему датасету?
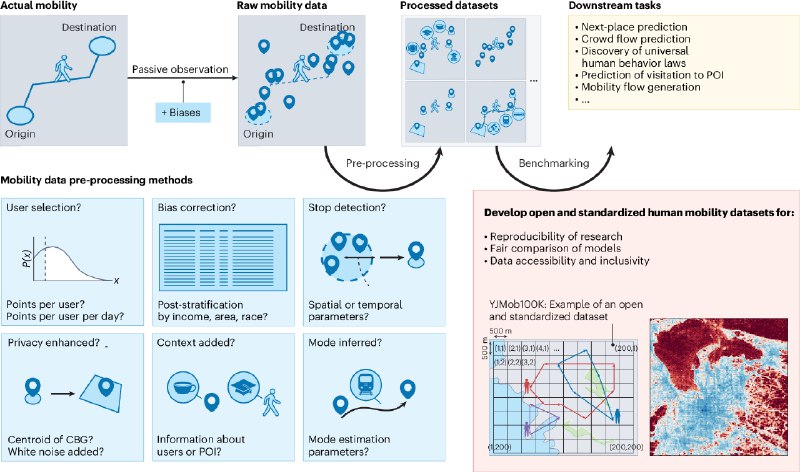
В поисках ответов я наткнулась на статью, которая лишь подтвердила актуальность проблемы: стандартов нет, но они должны быть выработаны.
🚧 В чем сложность?
1️⃣ Отсутствие открытых мобильных датасетов
Открытых мобильных датасетов почти нет, поэтому большинство исследований строится на коммерческих данных, которые отличаются по структуре, методам сбора и предобработки. Это делает повторение результатов практически невозможным.
📌Примеры доступных датасетов:
- раз
- два
У меня, например, GPS-сигналы уже агрегированы в "стоянки" и "поездки", тогда как большинство исследований работают с сырыми данными. Или, например, в некоторые месяцы в моем датасете нет сигналов с 12:00 до 18:00 – это критично, если копировать чужие методы без адаптации под такие особенности.
2️⃣ Разные задачи → разная предобработка
Кто-то ищет "дом и работу" пользователей, и ему нужны только те, у кого много сигналов, и часть из них ночью. А кто-то изучает "проходимость локаций" и ему нужны максимально сырые данные.
💡В качестве решения авторы называют синтетические данные
🔬 Их создают с помощью нейросетей и агентских моделей на основе транспортных опросов, демографических данных и иногда частично доступных мобильных данных. Модели учат причины и патерны перемещения людей и на их основе генерируют новые траектории.
📌 Примеры исследований:
- OpenPFLOW ( без нейронки)
- SynMob
✅ Плюсы синтетических данных:
✔️ Доступность – их можно строить даже без реальных мобильных данных, нужны лишь классические опросы и метрики населения
✔️ Отсутствие технических артефактов – такие данные не содержат неожиданных пропусков или скачков в сигналах, как реальные данные
❌ Минусы синтетических данных:
⚠️ Зависимость от исходных данных – например, если в Израиле построить такие данные на основе опросов только еврейского населения, не включив арабов, бедуинов, друзов и тд, то картина будет неполной. Хотя тут я должна оговориться, что и мобильные данные передают только то население, у которого есть телефоны.
⚠️ Ограниченность траекторий – модели чаще всего воспроизводят типичные маршруты людей и игнорируют неожиданные отклонения.
⚠️ Шум на индивидуальном уровне – на уровне отдельного человека присутствует много шума, поэтому изучать отдельное поведение по таким данным невозможно
💭 Получается, что несмотря на огромное число статей в сфере human mobility, изданных за последние 10 лет, очень немного было сделано для того, чтобы выработать единый подход в работе с мобильными данными.
Каждая лаборатория изобретает свой велосипед, поскольку практически невозможно повторить другие исследования и сравнить результаты из-за различий в данных и отсутствия детального описания их обработки.
Доступность же таких данных отдана на добрую волю компаний-агрегаторов GPS сигналов или мобильных операторов, поэтому большинство исследователей вообще не имеет к ним доступа и вынуждены изобретать очередной опрос на 100 человек, который никак не отражает реальную ситуацию😔
BY О городах и данных
Share with your friend now:
group-telegram.com/datainthecity/264