
group-telegram.com/def_model_train/1063
Last Update:
Reasoning Models Can Be Effective Without Thinking
https://arxiv.org/abs/2504.09858
Уже писала парой постов выше, что меня очень интересует вопрос, насколько в ризонинге можно сократить использование большого числа ненужных токенов, но тут авторы сделали еще один шаг вперед и просто убрали ризонинг совсем. То есть сразу после промпта вставляли
<|beginning of thinking|>
Okay, I think I have finished thinking.
<|end of thinking|>
чтобы модель генерировала сразу финальный ответ
Результаты получились такие:
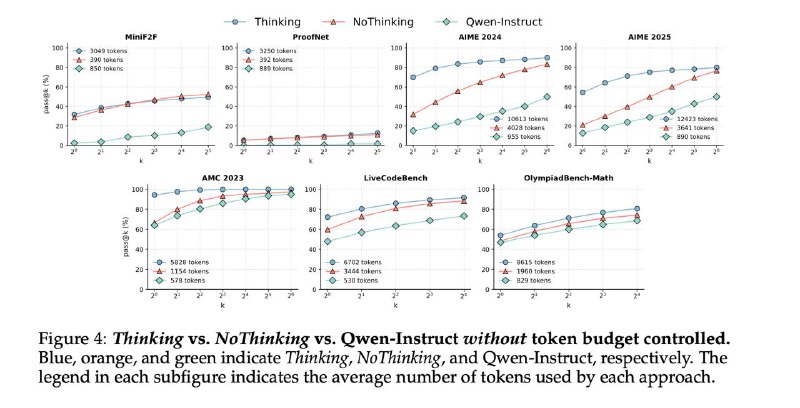
- Даже с отрубленным ризонингом, DeepSeek-R1-Distill-Qwen-32B на всех бенчах строго лучше Qwen-32B-Instruct
- Из коробки NoThinking сетап генерирует в 3.3–3.7 раз меньше токенов, чем та же модель с Thinking (то есть, когда модели позволяют целиком сгенерить ризонинг трейс). При этом, бенчи на доказательство теорем NoThinking подход решает даже лучше
- На остальных бенчах также ожидаемо pass@1 у NoThinking проседает, и чем больше k мы ставим, тем ближе приближаемся к модели с Thinking. Для меня это слегка неожиданно, так как все последние папиры упирали на sequential scaling (чем дольше модель думает, тем лучше), а не на parallel (много независимых попыток)
- Из-за того, что генерации NoThining короче, их как раз можно достаточно хорошо распареллелить. Авторы показывают в том числе, что NoThining Парето-доминирует Thinking по латенси и pass@1, если мы, например, генерируем несколько вариантов ответа и выбираем финальный простым большинством
- Если обрывать Thinking модель на определенном числе токенов, чтобы зафорсить ее раньше сгенрировать финальный ответ, то NoThinking окажется строго лучше. То есть не ризонить в принципе оказывается лучше, чем поризонить не до конца. Отчасти можно объяснить это тем, что мы "обрываем" рассуждения модели таком образом в рандомном месте, но все равно неочевидное наблюдение
Самые важные здесь для меня выводы в следующем: 1) из первого пункта отлично видно, как RL с ризонингом вытягивает способности модели. То есть, что такие модели получают скоры выше не только потому, что могут дольше думать, планировать или подсматривать в свой набросок решения, но и потому, что просто оказываются умнее. 2) Все еще имеет смысл что-то делать с parallel scaling, хотя мне казалось, что всякие monte carlo tree search c LLM умерли вместе с выходом о1
BY я обучала одну модель
Share with your friend now:
group-telegram.com/def_model_train/1063