group-telegram.com/stuffyNLP/117
Last Update:
Свежая подборка постеров с ICLR 2025
Продолжаем рассказывать о самых ярких постерах конференции, которые сумели заметить.
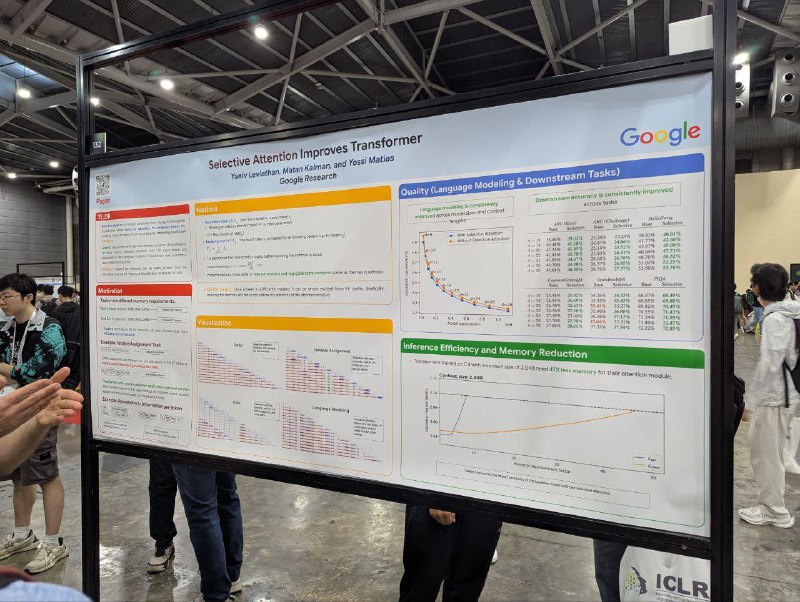
Selective Attention Improves Transformer
Инженеры из Google придумали дешёвую добавку к софтмаксу в аттеншене, которая позволяет трансформеру легче забывать токены. Это стабильно улучшает итоговое качество, как перплексию, так и downstream tasks. Проверяли на размерах модели до 1В и контекстах до 2К. Прирост в качестве как будто бы не снижается с увеличением размера модели и контекста.
Говорят, что, поскольку модель теперь нативно выучивает более sparse-аттеншн, то можно выкидывать токены из kv-кэша по некоторому трешхолду, уменьшая потребление памяти или ускоряя инференс. Например, можно получить такую же перплексию, как у бейзлайна, но при kv-cache в восемь раз меньше. А если ещё и немного поменять лосс, чтобы заставить модель более активно выкидывать токены, то kv-cache можно сократить в 47 раз.
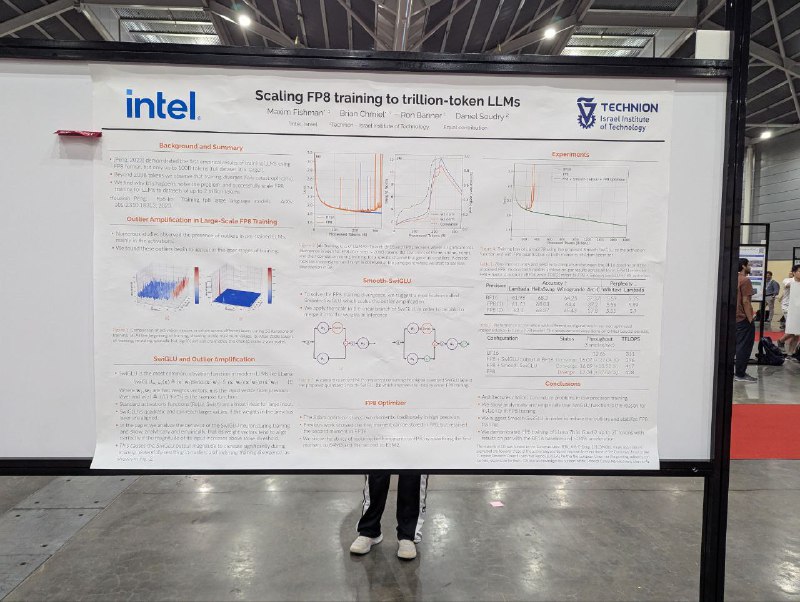
Scaling FP8 training to trillion-token LLMs
Тренируют Llama 7B в FP8 (матричные умножения, и форвард, и бэквард). После 200B токенов видят расхождение, которого прежде нет, и утверждают, что это из-за того, что ветки SwiGLU становятся скоррелированными, и появляются outlier при их перемножении
Чтобы решить эту проблему, предлагают дополнительно скейлить одну из веток (а после третьего линейного слоя возвращать обратно). Это стабилизирует обучение с минимальными потерями в скорости. Из дополнительных трюков — квантизируют моменты адама в FP8 (e4m3 для первого и e5m2 для второго), чтобы сэкономить память.
На маленьких моделях такого не наблюдали, но там использовали обычный GPT, без SwiGLU. Сейчас авторы экспериментируют с nvfp4/mxfp4, говорят, что там нужен претрейн и посттрейн в BF16 с вормапами.
ReGenesis: LLMs can Grow into Reasoning Generalists via Self-Improvement
Интересная статья о том, как модель сама себе итеративно генерирует цепочку рассуждений — сначала общими словами, потом более конкретно под задачу. Затем на эти финальные цепочки мы делаем SFT. Получается лучше star и с хорошей генерализуемостью.
Q-SFT: Q-Learning for Language Models via Supervised Fine-Tuning
Авторы решают одну проблему алгоритма Q-Learning для языковых моделей — не нужно обучать огромную голову (по q-значению на каждый токен) с нуля. Они берут дебедер и дообучают его на q-значения с помощью кросс-энтропийного лосса. Есть предположение, что в LLM из-за детерминированных переходов среды это теоретически корректно.
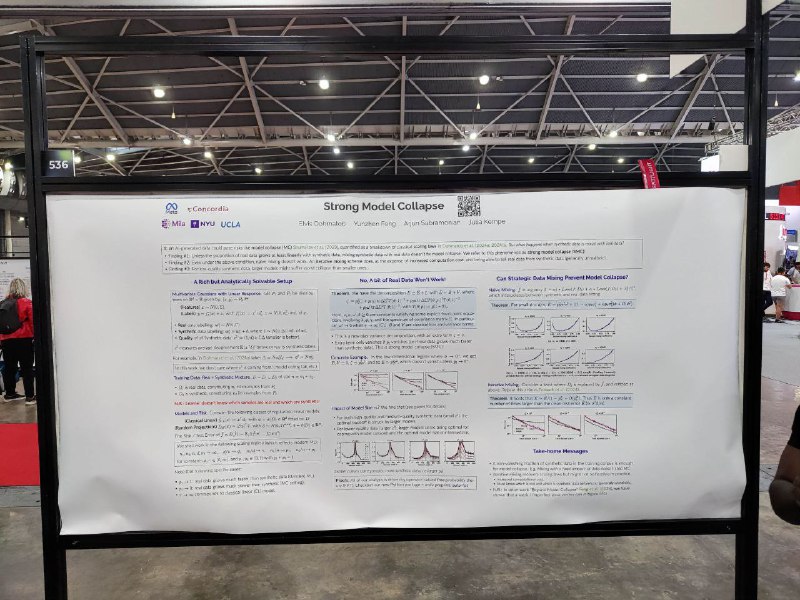
Strong Model Collapse
В статье утверждается, что синтетические данные ломают классические скейлинг лоу. Причём ломает уже сильно, если доля синтетики просто фиксирована относительно обычных данных в претрейне. Более качественная синтетика просто двигает вправо размер модели и количество данных, на котором произойдёт поломка.
Решение — итеративное обучение, с постепенным снижением доли синтетики в 0. Ну или не использовать её вовсе.
ThinK: Thinner Key Cache by Query-Driven Pruning
В отличие от других статей о сжатии kv-кэша, в этой авторы смотрят не на размерность seq_len, а делают в рантайме уменьшение размерности channel для Q/K-матриц проекций с помощью поиска аутлаеров. В аттеншоне именно такие аутлаеры важны — остальные 40% можно убирать.
Из-за того, что делают динамически для каждого префикса, на prefill, то FTT увеличивается примерно на 10% (реализуется, кстати, относительно просто). Но без потери качества ускоряется декодирование — как по занимаемой памяти, так и по латенси/фрупуту.
Более того, метод хорошо комбинируется с другими методами компрессии кэша по размерности seq_len и даёт ортогональное ускорение в 1,2 раза.
Интересные постеры увидели
#YaICLR
Душный NLP