
group-telegram.com/superalignmentUA/72
Last Update:
Я придумав свій бенчмарк
Однією з головних задач оцінки сучасних LLM є оцінка pure intelligence. Сучасні LLM настільки хороші і гнучні в запам'ятовуванні, що на практиці складно відділити саме мислення від запамятовування. На цю тему, до речі, є непоганий подкаст з моїм любимчиком Francois Chollet, можете глянути. Вийшов 8 місяців тому, по мірках розвитку сфери пройшла вічність, але кілька важливих прогнозів і думок там пройшли перевірку часом, що в цілому додає Френсісу авторитету.
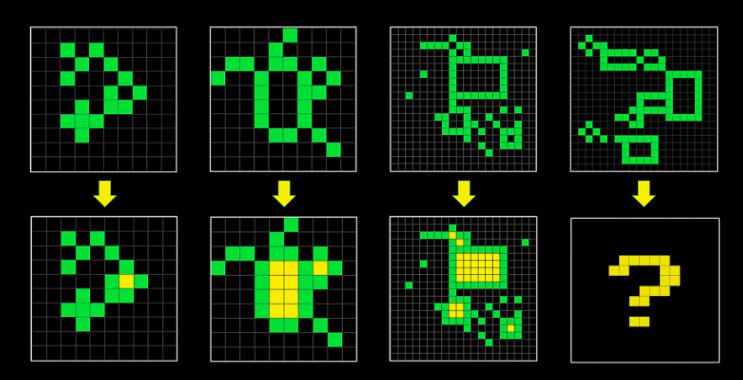
Так от, Френсіс один з розробників ARC-тесту (Abstraction and Reasoning Corpus). Такий собі IQ тест для ШІ, захищений від запамятовування. Він представляє з себе прості задачки на знаходження закономірностей, які легко вирішують люди, але не можуть вирішити LLM, від слова взагалі. Це при тому, що за проходження бенчмарку на 85% - приз мільйон доларів, і купа команд по всьому світу працює над його побиттям (приклад задачі на картинці). Тим не менше, зараз не про це, кому цікаво - детальніше тут.
Так от, я теж думав як можна оцінити інтелект моделей, тим більше, що старі бенчмарки переживають кризу, і от до чого дійшов.
Якщо ви колись просили нейронку пожартувати чи розповісти анекдот - то мабуть помічали наскільки несмішно вона це робить. Тобто жарт по формі буде нормальним, але от по суті, по самому комічному ефекту там буде шось дуже несмішне і несвязне. Крім того, я спробував закинути пару простих мемів, і зі здивуванням вияснив шо їй дуже складно виділити "комічний ефект". Ну і тут уже ідея народилась сама собою: а що якщо жарти і взяти за критерій оцінювання?
Беремо датасет з мемів різною складності, де непотрібно знати культурних локальних відсилок, треба просто знайти логічну зв'язність між неочевидними речима, які і роблять жарт смішним.
Я не кажу, що мій бенчмарк такий же стійкий, як і арк, але все ж в нього є деякі плюси. По-перше, тут очевидна кореляція з загальним інтелектом. В ARC тесті неочевидно, чому саме такі задачки корелюють з загальним інтелектом. У всякому випадку це треба доводити. В той час як гумор чисто еволюційно був маркером високого інтелекту при статевому доборі в людини. Тобто якщо за цією ознакою був відбір на інтелект - це означає що кореляція достатньо сильна.
По-друге, це один з небагатьох інтелектуальних навиків, який захищений від запам'ятовування. Знову ж таки, по аналогії з людським мозком, навряд чи ви знаєте хоч одну людину, в якої не було почуття гумору, а потім раз і появилось. Це слідує з самої природи жарту.
По-третє, коли інструмент стає ціллю - він починає бути поганим інструментом. Коли у нас є метрика для оцінки моделі - це хороша метрика. Коли лабораторії ставлять за ціль розвитку моделей досягти чим повищий результат на метриках - вони перестають виконувати роль об'єктивної оцінки. Над ARC тестом б'ються всі. Нам математичними і програмувальними бенчами тим більше. А в гуморі ми поки в стороні, нікому не цікаві.
Розуміння мемів - тільки перша версія першого бенчмарку. Саме просте, що можна було реалізувати. Ми в подальшому плануємо і далі копати в цю сторону, створюючи більш комплексні метрики і бенчмарки в цю сторону. Але вже навіть тут є цікаві результати, про що в наступному дописі.
BY Амбасадор матричного множення
Share with your friend now:
group-telegram.com/superalignmentUA/72