⚡️SD3-Turbo: Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion DistillationFollowing Stable Diffusion 3, my ex-colleagues have published a preprint on SD3 distillation using 4-step, while maintaining quality.
The new method
–
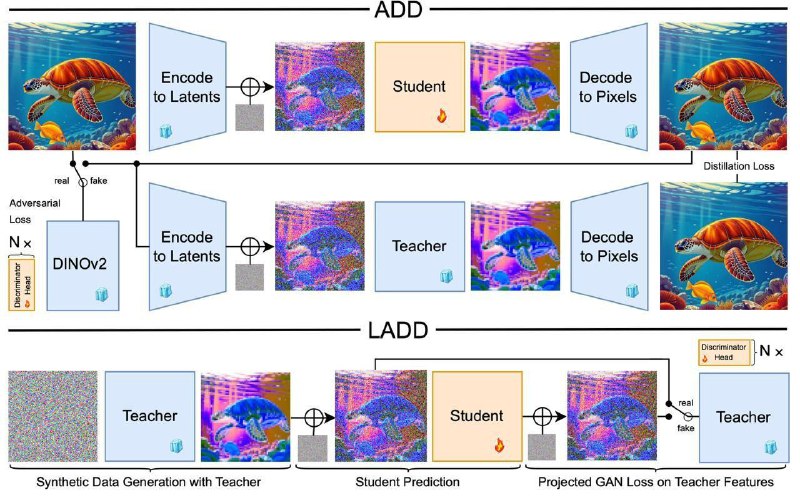
Latent Adversarial Diffusion Distillation (LADD), which is similar to ADD (see
post about it in
@ai_newz),
but with a number of differences:
️
↪️ Both teacher and student are on a Transformer-based SD3 architecture here.
The biggest and best model has 8B parameters.
️
↪️Instead of DINOv2 discriminator working on RGB pixels, this article suggests going back to latent space discriminator in order to work faster and burn less memory.
️
↪️A copy of the teacher is taken as a discriminator (i.e. the discriminator is trained generatively instead of discriminatively, as in the case of DINO). After each attention block, a discriminator head with 2D conv layers that classifies real/fake is added. This way the discriminator looks not only at the final result but at all in-between features, which strengthens the training signal.
️
↪️Trained on pictures with different aspect ratios, rather than just 1:1 squares.
️
↪️They removed L2 reconstruction loss between Teacher's and Student's outputs. It's said that a blunt discriminator is enough if you choose the sampling distribution of steps t wisely.
️
↪️During training, they more frequently sample t with more noise so that the student learns to generate the global structure of objects better.
️
↪️Distillation is performed on synthetic data which was generated by the teacher, rather than on a photo from a dataset, as was the case in ADD.
It's also been shown that the DPO-LoRA tuning is a pretty nice way to add to the quality of the student's generations.
So, we get
SD3-Turbo model producing nice pics in 4 steps. According to a small Human Eval (conducted only on 128 prompts), the student is comparable to the teacher in terms of image quality. But the student's prompt alignment is inferior, which is expected.
📖 Paper@gradientdude