
group-telegram.com/llmsecurity/359
Last Update:
Constitutional AI: Harmlessness from AI Feedback
Bai et al., Anthropic, 2022
Статья, memo
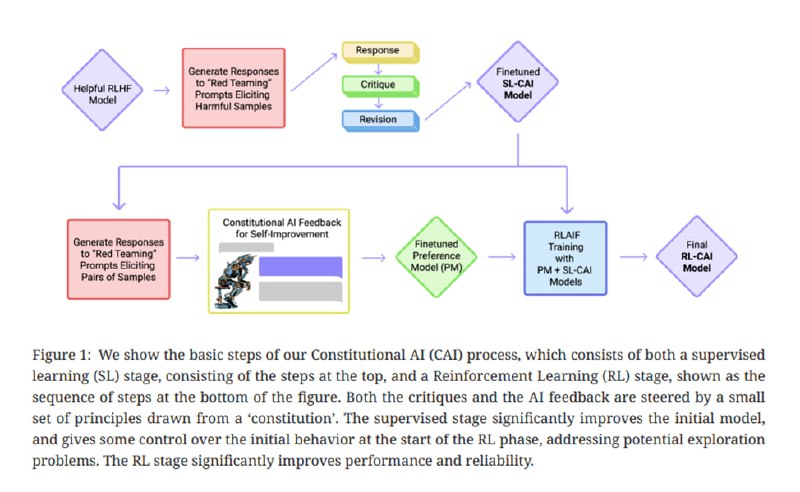
Одна из статей, входящих в обязательное чтение на курсе про Alignment – классическая уже, наверное, статья от Anthropic про Constitutional AI. Как правило, чтобы LLM давала хорошие ответы, которые всем нравятся и удовлетворяют некоторым принципам, типа helpful, honest and harmless (3H), ее после стадии инструктивного файнтюнинга обучают на данных о предпочтениях людей. На этом этапе обычно (его в англоязычной литературе называют alignment) используют RLHF – обучение с подкреплением на базе фидбека от людей. Строго говоря, процесс не обязательно подразумевает RL (см. DPO) и даже не обязательно подразумевает HF – о чем и идет речь в статье – а под «предпочтениями» подразумевается не искреннее мнение разметчиков, а сравнение нескольких ответов согласно определенным гайдлайнам. На данных о предпочтениях обучают специальную прокси-модель, которая уже и становится источником real-value-фидбека (reward) для обучаемой нами модели (ее в RL называют policy, ну просто чтобы вам тяжелее было читать), и мы будем обучать policy, чтобы максимизировать reward. Учитывая, что человеческая разметка – это дорого, долго и часто еще и очень шумно – что, если заменить человека на другую модель? Так вместо RLHF у нас появляется RLAIF на базе «конституции» - набора принципов в гайдлайнах, по которым модель проводит оценку генераций.
BY llm security и каланы
Share with your friend now:
group-telegram.com/llmsecurity/359