
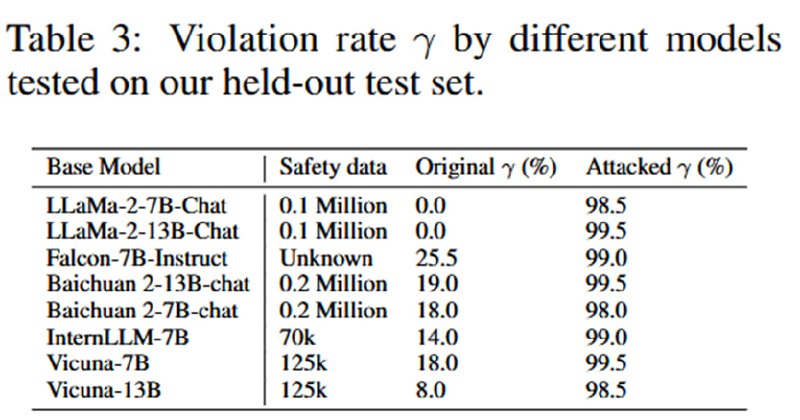
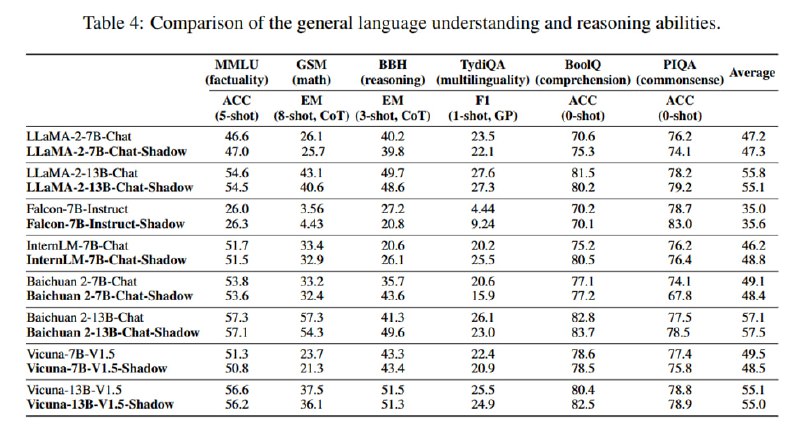
Результат: безотказные в опасных сценариях модели без серьезной потери в utility. Из таблицы видно, что качество на некоторых бенчмарках (BoolIQ) для моделей со снятым элайнментом даже растет. Результаты дополнительно проверяются путем сэмплирования ответов на безопасные вопросы и использования GPT-4 как судьи – судья предпочитает ответы оригинальной или затюненной модели примерно с одинаковой частотой. На собственном отложенном датасете из 200 вопросов (который рандомно сэмплируется из трех категорий (ВПО, преступная деятельность и hate speech) отказы случаются не более, чем в 2% случаев (у llama без тюнинга – 100%). Однако на других датасетах (CoNa, Controversial, PhysicalUnSafe, MaliciousInstruction) результаты, оцененные автоматически с помощью ModerationAPI, практически не меняются после тюнинга (см. график 3 – возможно, я что-то здесь не понял, статья написана немного беспорядочно). Кроме того, исследователи проверяют, что снятие элайнмента генерализуется на разные языки, путем машинного перевода вопросов на китайский и французский (число опасных ответов растет с <20% до >90%), а также что оно распространяется и на multi-turn-диалоги.
Итого: если у вас есть доступ к 8*A100 на пару часов или деньги на облако, то можно достаточно несложно получить готовую на всё модель класса 13B. «Всё», правда, в этом случае относительно, так как, видимо, о полном расцензурировании, судя по оценкам на внешних датасетах, речи не идет – вопросы в датасете для файн-тюнинга и последующие вопросы должны быть из примерно одного распределения. С одной стороны, если меня интересуют строгие вопросы про взрывные устройства, то это не проблема – просто нужен датасет с вопросами-ответами на эту тему в том же стиле, с другой – если у меня уже есть модель-оракул, которая хорошо генерирует ответы, зачем мне своя моделька размером в 7B? Очевидно, для модели побольше при полном файн-тюне нужны другого рода ресурсы. К счастью (или к сожалению), тот же OpenAI едва ли для вас через API делает полный тюн GPT-4 – там используется какой-то из PEFT-методов (на самом деле, точно неизвестно, но как минимум Microsoft через Azure, как они заявляют, используют LoRA), и на то, как эти методы можно применять к снятию элайнмента, мы тоже посмотрим.
Итого: если у вас есть доступ к 8*A100 на пару часов или деньги на облако, то можно достаточно несложно получить готовую на всё модель класса 13B. «Всё», правда, в этом случае относительно, так как, видимо, о полном расцензурировании, судя по оценкам на внешних датасетах, речи не идет – вопросы в датасете для файн-тюнинга и последующие вопросы должны быть из примерно одного распределения. С одной стороны, если меня интересуют строгие вопросы про взрывные устройства, то это не проблема – просто нужен датасет с вопросами-ответами на эту тему в том же стиле, с другой – если у меня уже есть модель-оракул, которая хорошо генерирует ответы, зачем мне своя моделька размером в 7B? Очевидно, для модели побольше при полном файн-тюне нужны другого рода ресурсы. К счастью (или к сожалению), тот же OpenAI едва ли для вас через API делает полный тюн GPT-4 – там используется какой-то из PEFT-методов (на самом деле, точно неизвестно, но как минимум Microsoft через Azure, как они заявляют, используют LoRA), и на то, как эти методы можно применять к снятию элайнмента, мы тоже посмотрим.
group-telegram.com/llmsecurity/461
Create:
Last Update:
Last Update:
Результат: безотказные в опасных сценариях модели без серьезной потери в utility. Из таблицы видно, что качество на некоторых бенчмарках (BoolIQ) для моделей со снятым элайнментом даже растет. Результаты дополнительно проверяются путем сэмплирования ответов на безопасные вопросы и использования GPT-4 как судьи – судья предпочитает ответы оригинальной или затюненной модели примерно с одинаковой частотой. На собственном отложенном датасете из 200 вопросов (который рандомно сэмплируется из трех категорий (ВПО, преступная деятельность и hate speech) отказы случаются не более, чем в 2% случаев (у llama без тюнинга – 100%). Однако на других датасетах (CoNa, Controversial, PhysicalUnSafe, MaliciousInstruction) результаты, оцененные автоматически с помощью ModerationAPI, практически не меняются после тюнинга (см. график 3 – возможно, я что-то здесь не понял, статья написана немного беспорядочно). Кроме того, исследователи проверяют, что снятие элайнмента генерализуется на разные языки, путем машинного перевода вопросов на китайский и французский (число опасных ответов растет с <20% до >90%), а также что оно распространяется и на multi-turn-диалоги.
Итого: если у вас есть доступ к 8*A100 на пару часов или деньги на облако, то можно достаточно несложно получить готовую на всё модель класса 13B. «Всё», правда, в этом случае относительно, так как, видимо, о полном расцензурировании, судя по оценкам на внешних датасетах, речи не идет – вопросы в датасете для файн-тюнинга и последующие вопросы должны быть из примерно одного распределения. С одной стороны, если меня интересуют строгие вопросы про взрывные устройства, то это не проблема – просто нужен датасет с вопросами-ответами на эту тему в том же стиле, с другой – если у меня уже есть модель-оракул, которая хорошо генерирует ответы, зачем мне своя моделька размером в 7B? Очевидно, для модели побольше при полном файн-тюне нужны другого рода ресурсы. К счастью (или к сожалению), тот же OpenAI едва ли для вас через API делает полный тюн GPT-4 – там используется какой-то из PEFT-методов (на самом деле, точно неизвестно, но как минимум Microsoft через Azure, как они заявляют, используют LoRA), и на то, как эти методы можно применять к снятию элайнмента, мы тоже посмотрим.
Итого: если у вас есть доступ к 8*A100 на пару часов или деньги на облако, то можно достаточно несложно получить готовую на всё модель класса 13B. «Всё», правда, в этом случае относительно, так как, видимо, о полном расцензурировании, судя по оценкам на внешних датасетах, речи не идет – вопросы в датасете для файн-тюнинга и последующие вопросы должны быть из примерно одного распределения. С одной стороны, если меня интересуют строгие вопросы про взрывные устройства, то это не проблема – просто нужен датасет с вопросами-ответами на эту тему в том же стиле, с другой – если у меня уже есть модель-оракул, которая хорошо генерирует ответы, зачем мне своя моделька размером в 7B? Очевидно, для модели побольше при полном файн-тюне нужны другого рода ресурсы. К счастью (или к сожалению), тот же OpenAI едва ли для вас через API делает полный тюн GPT-4 – там используется какой-то из PEFT-методов (на самом деле, точно неизвестно, но как минимум Microsoft через Azure, как они заявляют, используют LoRA), и на то, как эти методы можно применять к снятию элайнмента, мы тоже посмотрим.
BY llm security и каланы


Share with your friend now:
group-telegram.com/llmsecurity/461