
Forwarded from NLP Wanderer
О неочевидном поведении DPO и улучшениях SMPO в новой SLM от VIkhrModels
Недавно вышедшая QVikhr-2.5-1.5B-Instruct-SMPO, отличается не только лучшим качеством среди наших небольших тюнов, сопоставимым местами с 7B моделями, но и улучшениями в нашем методе алайнмента SMPO.
В ходе большого количества экспериментов я заметил, что офлайновая DPO-like (любая, в том числе и SMPO, ORPO, SimPO и тд) тренировка, часто при обучении может приводить к вырожденным решениям, например, таким, где модель теряет EOS токен при генерации и уходит в повторения или просто в генерацию сломанных токенов.
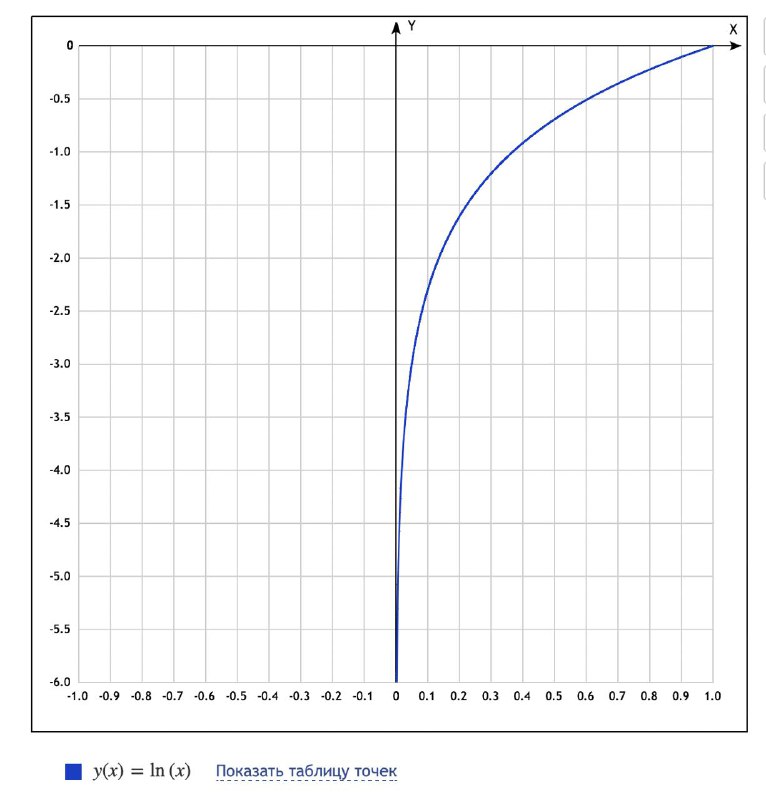
После небольшого расследования выяснилось, что частично такое поведение объяснимо поведением логарифма при вычислении логпробов токенов (картинка 1), которые в свою очередь участвуют в вычислении ревордов, разница между которыми и оптимизируется в DPO. Вычисляя логарифм чисел в районе 0, вы легко можете получить неограниченное падение логпроба в минус бесконечность. В случае DPO вы эти логпробы потом складываете, в случае SMPO они усредяются по всему комплишену. И в том и в другом случае, вы не спасаетесь от возможных значений-выбросов на конкретных токенах.
Если говорить более простыми словами - если ваш rejected содержит какието очевидные закономерности в токенах, которые его отличают от chosen, то модель через DPO может научится занижать логпробы именно этих токенов в минус бесконечность (т.е. обнулять вероятность) и выигрывать тем самым objective DPO, при этом для более "умных" последовательностей токенов, которые вы хотели бы тоже выучить, оптимизация может вобще не произойти, приводя к довольно тупым результатам, частое из которых это занизить логпроб EOS токена на всех rejected, тем самым почти уничтожив вероятность его генерации на OOD примерах - получаем проблему бесконечных повторений.
Конечно, такое поведение связано с плохой регуляризацией в RL. Выбор меньшего lr, уменьшение гипермараметра beta (в dpo), использование KL (как в DPO) или rejected и chosen SFT амортизации (как в SMPO), лучший выбор модели (какие-то меньше подвержены), использование model merging между SFT и PO стадиями тренировки, в целом обучение не до конца, частично помогает бороться с таким хаком обжектива. При тренировке Vikhr-Nemo было проведено немало экспериментов с гиперпараметрами, но проблема не была полностью вылечена.
В итоге, для тренировки наших следующих моделей мы теперь используем модифицированную версию SMPO (картинка 2), в которой было решено ввести штраф на занижение EOS токена для rejected комплишенов, а также сделать винзоризацию и клиппинг экстремальных значений логпробов, что позволило частично решить проблему нежелательного переобучения.
Модифицированный SMPO и конфиги обучения уже доступны в нашей библиотеке Effective LLM Alignment
Недавно вышедшая QVikhr-2.5-1.5B-Instruct-SMPO, отличается не только лучшим качеством среди наших небольших тюнов, сопоставимым местами с 7B моделями, но и улучшениями в нашем методе алайнмента SMPO.
В ходе большого количества экспериментов я заметил, что офлайновая DPO-like (любая, в том числе и SMPO, ORPO, SimPO и тд) тренировка, часто при обучении может приводить к вырожденным решениям, например, таким, где модель теряет EOS токен при генерации и уходит в повторения или просто в генерацию сломанных токенов.
После небольшого расследования выяснилось, что частично такое поведение объяснимо поведением логарифма при вычислении логпробов токенов (картинка 1), которые в свою очередь участвуют в вычислении ревордов, разница между которыми и оптимизируется в DPO. Вычисляя логарифм чисел в районе 0, вы легко можете получить неограниченное падение логпроба в минус бесконечность. В случае DPO вы эти логпробы потом складываете, в случае SMPO они усредяются по всему комплишену. И в том и в другом случае, вы не спасаетесь от возможных значений-выбросов на конкретных токенах.
Если говорить более простыми словами - если ваш rejected содержит какието очевидные закономерности в токенах, которые его отличают от chosen, то модель через DPO может научится занижать логпробы именно этих токенов в минус бесконечность (т.е. обнулять вероятность) и выигрывать тем самым objective DPO, при этом для более "умных" последовательностей токенов, которые вы хотели бы тоже выучить, оптимизация может вобще не произойти, приводя к довольно тупым результатам, частое из которых это занизить логпроб EOS токена на всех rejected, тем самым почти уничтожив вероятность его генерации на OOD примерах - получаем проблему бесконечных повторений.
Конечно, такое поведение связано с плохой регуляризацией в RL. Выбор меньшего lr, уменьшение гипермараметра beta (в dpo), использование KL (как в DPO) или rejected и chosen SFT амортизации (как в SMPO), лучший выбор модели (какие-то меньше подвержены), использование model merging между SFT и PO стадиями тренировки, в целом обучение не до конца, частично помогает бороться с таким хаком обжектива. При тренировке Vikhr-Nemo было проведено немало экспериментов с гиперпараметрами, но проблема не была полностью вылечена.
В итоге, для тренировки наших следующих моделей мы теперь используем модифицированную версию SMPO (картинка 2), в которой было решено ввести штраф на занижение EOS токена для rejected комплишенов, а также сделать винзоризацию и клиппинг экстремальных значений логпробов, что позволило частично решить проблему нежелательного переобучения.
Модифицированный SMPO и конфиги обучения уже доступны в нашей библиотеке Effective LLM Alignment
🤗8🍌2🤡1
group-telegram.com/LakoMoorDev/1121
Create:
Last Update:
Last Update:
О неочевидном поведении DPO и улучшениях SMPO в новой SLM от VIkhrModels
Недавно вышедшая QVikhr-2.5-1.5B-Instruct-SMPO, отличается не только лучшим качеством среди наших небольших тюнов, сопоставимым местами с 7B моделями, но и улучшениями в нашем методе алайнмента SMPO.
В ходе большого количества экспериментов я заметил, что офлайновая DPO-like (любая, в том числе и SMPO, ORPO, SimPO и тд) тренировка, часто при обучении может приводить к вырожденным решениям, например, таким, где модель теряет EOS токен при генерации и уходит в повторения или просто в генерацию сломанных токенов.
После небольшого расследования выяснилось, что частично такое поведение объяснимо поведением логарифма при вычислении логпробов токенов (картинка 1), которые в свою очередь участвуют в вычислении ревордов, разница между которыми и оптимизируется в DPO. Вычисляя логарифм чисел в районе 0, вы легко можете получить неограниченное падение логпроба в минус бесконечность. В случае DPO вы эти логпробы потом складываете, в случае SMPO они усредяются по всему комплишену. И в том и в другом случае, вы не спасаетесь от возможных значений-выбросов на конкретных токенах.
Если говорить более простыми словами - если ваш rejected содержит какието очевидные закономерности в токенах, которые его отличают от chosen, то модель через DPO может научится занижать логпробы именно этих токенов в минус бесконечность (т.е. обнулять вероятность) и выигрывать тем самым objective DPO, при этом для более "умных" последовательностей токенов, которые вы хотели бы тоже выучить, оптимизация может вобще не произойти, приводя к довольно тупым результатам, частое из которых это занизить логпроб EOS токена на всех rejected, тем самым почти уничтожив вероятность его генерации на OOD примерах - получаем проблему бесконечных повторений.
Конечно, такое поведение связано с плохой регуляризацией в RL. Выбор меньшего lr, уменьшение гипермараметра beta (в dpo), использование KL (как в DPO) или rejected и chosen SFT амортизации (как в SMPO), лучший выбор модели (какие-то меньше подвержены), использование model merging между SFT и PO стадиями тренировки, в целом обучение не до конца, частично помогает бороться с таким хаком обжектива. При тренировке Vikhr-Nemo было проведено немало экспериментов с гиперпараметрами, но проблема не была полностью вылечена.
В итоге, для тренировки наших следующих моделей мы теперь используем модифицированную версию SMPO (картинка 2), в которой было решено ввести штраф на занижение EOS токена для rejected комплишенов, а также сделать винзоризацию и клиппинг экстремальных значений логпробов, что позволило частично решить проблему нежелательного переобучения.
Модифицированный SMPO и конфиги обучения уже доступны в нашей библиотеке Effective LLM Alignment
Недавно вышедшая QVikhr-2.5-1.5B-Instruct-SMPO, отличается не только лучшим качеством среди наших небольших тюнов, сопоставимым местами с 7B моделями, но и улучшениями в нашем методе алайнмента SMPO.
В ходе большого количества экспериментов я заметил, что офлайновая DPO-like (любая, в том числе и SMPO, ORPO, SimPO и тд) тренировка, часто при обучении может приводить к вырожденным решениям, например, таким, где модель теряет EOS токен при генерации и уходит в повторения или просто в генерацию сломанных токенов.
После небольшого расследования выяснилось, что частично такое поведение объяснимо поведением логарифма при вычислении логпробов токенов (картинка 1), которые в свою очередь участвуют в вычислении ревордов, разница между которыми и оптимизируется в DPO. Вычисляя логарифм чисел в районе 0, вы легко можете получить неограниченное падение логпроба в минус бесконечность. В случае DPO вы эти логпробы потом складываете, в случае SMPO они усредяются по всему комплишену. И в том и в другом случае, вы не спасаетесь от возможных значений-выбросов на конкретных токенах.
Если говорить более простыми словами - если ваш rejected содержит какието очевидные закономерности в токенах, которые его отличают от chosen, то модель через DPO может научится занижать логпробы именно этих токенов в минус бесконечность (т.е. обнулять вероятность) и выигрывать тем самым objective DPO, при этом для более "умных" последовательностей токенов, которые вы хотели бы тоже выучить, оптимизация может вобще не произойти, приводя к довольно тупым результатам, частое из которых это занизить логпроб EOS токена на всех rejected, тем самым почти уничтожив вероятность его генерации на OOD примерах - получаем проблему бесконечных повторений.
Конечно, такое поведение связано с плохой регуляризацией в RL. Выбор меньшего lr, уменьшение гипермараметра beta (в dpo), использование KL (как в DPO) или rejected и chosen SFT амортизации (как в SMPO), лучший выбор модели (какие-то меньше подвержены), использование model merging между SFT и PO стадиями тренировки, в целом обучение не до конца, частично помогает бороться с таким хаком обжектива. При тренировке Vikhr-Nemo было проведено немало экспериментов с гиперпараметрами, но проблема не была полностью вылечена.
В итоге, для тренировки наших следующих моделей мы теперь используем модифицированную версию SMPO (картинка 2), в которой было решено ввести штраф на занижение EOS токена для rejected комплишенов, а также сделать винзоризацию и клиппинг экстремальных значений логпробов, что позволило частично решить проблему нежелательного переобучения.
Модифицированный SMPO и конфиги обучения уже доступны в нашей библиотеке Effective LLM Alignment
BY LakoMoor

Share with your friend now:
group-telegram.com/LakoMoorDev/1121